 |
Главная |


Данные с фиксированной точкой
|
из
5.00
|
Память
Память - устройство ЭВМ, предназначенное для хранения обрабатываемой информации. Прежде чем приступить к обсуждению организации данных в памяти нужно узнать в чем она измеряется.
Бит - единица измерения количества информации и объема памяти. Измеряет минимальное количество информации, для кодирования которой достаточно одного двоичного разряда. Память ЭВМ состоит из элементов, способных запоминать значения битов (0 или 1). Такой выбор кода записи в вычислительной технике связан с тем, что в физическом мире наиболее просто реализуются системы, обладающие двумя устойчивыми состояниями. [От англ. BI (nary digi) T - binary-двоичный и digit-знак, цифра]
Минимальная адресуемая порция информации в памяти называется ячейкой памяти. Но что значит "адресовать", чтобы разобраться с этим для начала посмотрим в таблицу, в которой указана длина ячейки памяти в битах для разных вычислительных машин:

Основное преимущество ячеек памяти, как уже отмечалось выше, в том, что мы можем их адресовать, т.е. любая ячейка памяти имеет свой уникальный номер, по которому компьютер всегда может непосредственно по адресу обратиться к содержимому ячейки. Бит таким свойством не обладает (конечно если нам надо обратиться к 2057-му биту в компьютере IBM, то мы обращаемся к 257 байту и выделяем у него 1 бит (такие средства у компьютера есть), но как вы видите адресуем мы именно байт, а не бит).
Иногда последовательно идущие байты объединяют в более крупные структуры. Рассмотрим их:
На компьютере Intel *86 дополнительно есть
Слово(word) - состоит из 2 байт. Снизу указана последовательность
следования байт (сначала идет байт с номером 0, потом 1,2,..).

Отметим "экзотическую" особенность представления чисел в данных компьютерах: числа размером в слово и двойное слово хранятся в памяти в перевернутом виде. Если на число отведено слово памяти, то старшие(левые) 8 битов хранятся в о втором байте слова, а младшие (правые) 8 битов - в первом байте; в терминах шестнадцатеричной системы: первые две цифры числа хранятся во втором байте слова, а две последние - в первом байте. Например, число 98 = 0062h (h означает hexadecimal - шестнадцатеричный) храниться в памяти так (А - адрес слова):
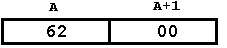
Зачем это сделано? Как известно, сложение и вычитание многозначных чисел мы начинаем с действий над младшими цифрами. С другой стороны, первые модели ПК (с процессором 8080) были 8-разрядными, в них за раз можно было считать из памяти только один байт. Поскольку в этих условиях многозначное число нельзя считать из памяти сразу, то в первую очередь приходиться считывать байт, где находятся младшие цифры числа, а для этого надо, чтобы такой байт хранился в памяти первым. По этой причине в первых моделях ПК и появилось "перевернутое" представление чисел. В последующих же моделях, где уже можно было сразу считать из памяти все число, ради сохранения преемственности, ради того, чтобы ранее составленные программы могли выполняться на новых ПК, сохранили это "перевернутое" представление. Поэтому на рисунке слова такая странная нумерация байтов. Т.е. старшая часть числа записывается во второй байт. Далее на рисунках числа под байтами означают порядок их записи в память.
Двойное слово (Double Word) - состоит из 4 байт

Для компьютеров Dec PDPII
Двойное слово также имеет размер 4 байта, но порядок следования байт другой:

Для компьютеров Motorola, IBM 370
Слово - имеет размер 4 байта и порядок следования байт прямой. Кроме этого слово подразделяется на 2 полуслова, каждое длиной 2 байта.

Компьютеры Dec VAX
Слово также имеет размер 4 байта, но порядок следования байт в слове
обратный
Вернемся к компьютерам Intel и подробнее рассмотрим такую структуру как байт. По принятым соглашениям биты в байтах нумеруются справа налево(см рис.), но вообще для компьютеров это не верно (для IBM-370 порядок следования обратный):
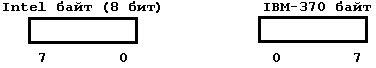
Логические данные
Логические данные (булевский тип) представлен двумя значениями: истина и ложь. Широко применяется в логических выражениях и выражениях отношения. Здесь есть одна проблема, она связана с машинным представлением логических значений "истина" и "ложь". Дело в том, что в ЭВМ, как правило, нет стандартных представлений логических величин. В ПК минимальная порция информации, обрабатываемая командами, - это байт, в связи с чем на одну логическую переменную обычно и отводят один байт. Но с другой стороны, для представления логического значения достаточно одного бита. Возникает вопрос: как заполнить 8 битов байта, если нужен только 1 бит? Это можно сделать по-разному, каждый может выбрать свой способ заполнения байта, поэтому и нет какого-то одного, стандартного способа представления логических величин. Рассмотрим только некоторые:


Символьные данные
Значением символьного типа является множество всех символов ПК.
1 символ = 1 байт (ASCII, ДКОИ, КОИ-8)
1 символ = 2 байта (Unicode)
В компьютере каждый символ обычно обозначен одним байтом - восьмью двоичными цифрами. Это всего 256 возможных значений. Естественно, все мыслимые символы в этот диапазон не уложить. Поэтому разработчики кодовой таблицы выбирают какие алфавиты охватить, а какие пропустить. Существует множество вариантов кодировки. Вот некоторые примеры реализации символов в разных кодировках:
ДКОИ латинская 'A' - C1 (16)
русская 'А' - C1 (16)
пробел - 20(16) - ASCII
40(16) - ДКОИ
ноль - 30(16) - ASCII
F0(16) - ДКОИ
Принятая в США (и зашитая в аппаратуру знакогенератора каждого IBM-совместимого компьютере) кодовая таблица 437 для DOS содержит самые частые в математических текстах греческие буквы и знаки, а также буквы характерные для некоторых западноевропейских алфавитов. Для того чтобы ввести в кодовую таблицу символы русского языка используют русификаторы. Они меняют вторую половину кодовой таблицы на русские символы. Но и тут нет единого стандарта. В зависимости от принятого способа кодировки русские строчные буквы могут образовывать один сплошной массив (кодировки ГОСТ и MIC), два массива (альтернативная кодировка), не сплошной массив (кодировка типа ЕСТЕЛ), неупорядоченный массив (кодировка КОИ-8).
Постепенно набирает популярность новая кодовая таблица - Unicode. В ней каждый символ обозначен двумя байтами. В 65536 позициях новой таблицы умещаются все современные алфавиты, слоговые системы письма, специальные знаки(вроде интегралов и нот), даже китайские иероглифы.
К сожалению, шрифтовой файл со всеми символами Unicode занимает несколько мегабайт. Кроме того в Турбо Паскале нет средств работы со шрифтами Unicode, в отличие от других языков (например, Delphi).
Для кодировки символов на IBM-совместимых компьютерах чаще всего используется код ASCII (American Standard Code for Information Interchange - американский стандартный код для обмена информацией). Каждому символу в нем приписывается целое число в диапазоне 0..255. Это число служит кодом внутреннего представления символа. Символы с кодами (0..1F) относятся к служебным кодам.
Хранение текста
С самого своего изобретения основной задачей компьютеров стало хранение и обработка информации. Если учесть, что большая часть информации представляет собой последовательность символов, то необходимость создания строковых типов возникла достаточно быстро. В основном задачу хранения символов можно решить следующим образом:
1) Массивы символов, т.е. данные хранятся в массиве, но этот тип хранения не очень удобен, т.к. слова состоят из разного числа символов и большая часть памяти просто не используется
2) Строки - самый удобный способ хранения, но реализовать его можно по-разному:
а) строка с первым значимым символом - это массив символов, первый элемент которого содержит длину строки. В языке Turbo Pascal для компьютеров IBM PC максимальная длина такой строки составляет 256 байт. Но как легко заметить большая часть памяти теряется.

б) строка с завершающим нулевым (null) символом - это последовательность символов в конце которой стоит символ с кодом #0. Основные достоинства этого способа хранения информации - отсутствие мусора, динамическое изменение размера строки (такой тип реализован в C, в последней версии Turbo Pascal 7.0 в рамках типа PChar).

Из этого следует, что строки требуют для своего хранения на 1 байт больше, чем нужно. Т.е. если нужна строка в n символов, то ее настоящая длина в памяти будет (n+1) символ.
Арифметические данные
Обработка числовой информации на ЭВМ, как правило, происходит следующим образом. Поскольку исходные данные и результаты записываются в привычной для людей десятичной системе, а ЭВМ работает с двоичными числами, то при вводе числа переводятся в двоичную систему, после чего происходит обработка двоичных чисел, а при выводе результаты переводятся в десятичную систему. При этом на перевод чисел из одной системы в другую, естественно, тратиться время. Но если исходных данных и результатов немного, а их обработка занимает значительное время, тогда затраты на перевод не очень заметны.
Однако есть класс задач (например, коммерческие), для которых характерен ввод большого массива числовых данных с последующим применением к ним всего одной-двух арифметических операций и выводом также большого количества результатов. В этих условиях переводы чисел из десятичной системы в двоичную и обратно могут занять львиную долю общих затрат времени, что, конечно, невыгодно. С учетом этого в компьютерах предусматривается специальное представление целых чисел, при котором они фактически не отличаются от записи чисел в десятичной системе и которое потому практически не требует перевода чисел из внешнего представления во внутреннее и обратно, и предусмотрены команды арифметических операций над такими числами. Данное представление чисел называется двоично-десятичным(binary coded decimal, BCD-числа) и строятся по следующему принципу: берется десятичная запись числа и каждая его цифра заменяется на 4 двоичные цифры (от 0000 до 1001), обозначающие эту цифру в двоичной системе.
Различие между двоичными и двоично-десятичными представлениями чисел проявляется в том, что если в двоичном представлении за основу берется величина числа (независимо от того, как именно вначале оно было записано), то в двоично-десятичном представлении за основу берется запись числа, причем именно в десятичной форме (если число записать в другой системе, скажем в семеричной, то получилось бы иное представление).
Примеры представления:
Intel *86: различаются неупакованные (1 цифра - 1 байт) и упакованные
(2 цифры - 1 байт) десятичные цифры.

Упакуем, например, число 13 которое в двоичном виде записывается как 00001011, а в двоично-десятичном оно будет выглядеть как 00010011. Чтобы в двоично-десятичном числе был еще и знак, добавляют еще один байт, который считается знаковым. В пример приведу неупакованное девятизначное число со знаком:

IBM-370:
Совершенно иначе десятичные данные реализованы в этих процессорах.
 |
Неупакованные данные представляют собой объединение байт размером до 16 байт. При записи десятичное число разбивается на десятичные цифры записи и каждая из них записывается в отдельный байт. При этом каждый байт в шестнадцатеричной записи выглядит как F*(16) , где * - десятичная цифра. При этом последний байт является знаковым и записывается в шестнадцатеричной системе как D*(16) если число отрицательное и C*(16) если число положительное. Для примера запишем числа +156(10) и –156(10) в таком виде.
 |
Упакованные данные также представляют собой объединение байт размером до 16 байт. В них десятичное число записывается немного в другом виде. Теперь в каждый байт записывается не по одной цифре, а по две. Последний байт, как и в прошлой конструкции, играет роль знакового и представляет собой шестнадцатеричную запись *D(16) если число знаковое и *C(16) если беззнаковое (где * - последняя цифра в записи числа).
Данные с фиксированной точкой
Данные с фиксированной точкой - это форма представления чисел в ЭВМ с постоянным положением запятой, отделяющей целую часть числа от дробной. В ЭВМ числа с фиксированной точкой являются одним из базовых типов. Если предположить, что после запятой идут одни нули, то сразу получим множество целых чисел. В результате чего числа с фиксированной запятой можно условно поделить на целочисленные и числа с дробной частью. Рассмотрим конкретную реализацию для различных компьютеров.
Intel *86
Для компьютеров данной серии характерно то, что у них отсутствуют данные с фиксированной запятой, кроме, естественно, данных, представляющих целые числа. Процессор имеет команды для работы с целыми (знаковыми и беззнаковыми) числами, имеющих в памяти следующий размер: 1 байт, 2 байта, 4 байта и 8 байт.
IBM - 370
Может работать с целыми числами размером 2,4 и 8 байт. Последний случай
особый, т.к. процессор не имеет команд для их обработки. Кроме этого
структуры размером 4 байта могут представлять только знаковые числа.
Форма представления чисел:
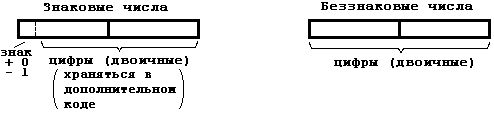
Положительные целые со знаком - это 0 и все положительные числа.
Отрицательные целые со знаком - это все числа, меньшие 0. Отличительным признаком числа со знаком является особая трактовка одного из битов поля, представляющего число. Естественно, что физически этот бит ничем не отличается от других – все зависит от команды, работающей с данным полем. Если в ее алгоритме заложена работа с целыми числами со знаком, то она будет по-особому трактовать этот бит. В случае, если бит равен 0, то число считается положительным и его значение вычисляется по обычным правилам. В случае, если этот бит равен 1, число считается отрицательным и предполагается, что оно записано в так называемом дополнительном коде. Разберемся в том, что он собой представляет.
Дополнительный код некоторого отрицательного числа представляет собой результат инвертирования (замены 1 на 0 и наоборот) каждого бита двоичного числа, плюс единица. К примеру рассмотрим десятичное число -185(10). Модуль данного числа в двоичном представлении равен 10111001(2). Сначала нужно дополнить это значение слева нулями до нужной размерности - байта, слова и т.д. В нашем случае дополнить нужно до структуры размером в 2 байта (в IBM-370 это полуслово, а в Intel - слово), так как диапазон представления знаковых чисел в байте составляет -128..127. Следующее действие – получить двоичное дополнение. Для этого все разряды двоичного числа нужно инвертировать:
0000000010111001(2) в 1111111101000110(2)
Теперь прибавляем единицу:
1111111101000110(2) + 0000000000000001(2) = 1111111101000111(2)
Результат преобразования равен 1111111101000111(2). Именно так и представляется число
-185(10) в компьютере. При работе с числами со знаком от вас наверняка потребуется умение выполнять обратное действие - имея двоичное дополнение числа, определить значение его
модуля. При этом необходимо сделать два действия:
1. Выполнить инвертирование битов двоичного дополнения.
2. К полученному двоичному числу прибавить двоичную единицу.
К примеру, определим модуль двоичного представления числа -185(10)= 1111111101000111(2):
1111111101000111(2) - инвертируем биты - 0000000010111000(2)
Добавляем двоичную единицу:
0000000010111000(2) + 0000000000000001(2) = 0000000010111001(2) = |-185|
Так как один бит является знаковым, то естественно появляется разница в диапазонах
значений для чисел со знаком и без знака. Кроме этого число интерпретируется
по-разному в зависимости от того как на него смотреть.
10000000(2) - это число 128 если смотреть на него как на беззнаковое
10000000(2) - это число -128 если смотреть на него как на знаковое (судя по первому биту это
отрицательное число). Число -128 является самым большим среди однобайтовых
знаковых чисел.
01111111(2) - это число +127 - самое большое положительное число среди однобайтовых
знаковых чисел.
Еще пример, если для целого 90(10) отведено 2 байта, то содержимым байта будет двоичное число 01011010(2), а для числа –90(10) соответственно 1111111110100110(2).

Если при кодировании числа знак или цифра числа не размещается в поле, то
возникает ситуация переполнения знака.
Поскольку в ячейке из k разрядов можно записать 2k различных комбинаций из 0 и 1, то в различных ячейках можно записать:
1 байт знаковых -128..127
беззнаковых 0..255
2 байта знаковых -32768..32767
беззнаковых 0..65535
4 байта знаковых -2147483648..2147483647
беззнаковых 0..4294967295
Кроме этого в нескольких байтах можно хранить и не только целые числа. Посмотрим как можно реализовать число с фиксированной точкой на компьютере с помощью 3 байт. Первые два байта будут хранить число записанное в двоичной форме начиная со старшего разряда, а третий - положение десятичной точки. Пусть, например, надо записать в эту структуру десятичное число 1.1 - число с точкой. В двоичной системе эта дробь записывается в виде 1.0(00110). Тогда, записывая эту дробь в нашу структуру, получим:

Обращаю ваше внимание на то, что точка может находиться только в границах байта и не выходить за его пределы. Этим и отличаются данные с фиксированной точкой и плавающей точкой. Но при операциях с данными с фиксированной точкой необходимо постоянно выравнивать положение точки относительно каждого операнда, поэтому действия с фиксированной точкой выполняются за очень большое время. Из-за чего данные с фиксированной точкой очень редко используются на практике.
|
из
5.00
|
Обсуждение в статье: Данные с фиксированной точкой |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы