 |
Главная |


Код с постоянным весом
|
из
5.00
|
Помехоустойчивое кодирование
Под помехой понимается любое воздействие, накладывающееся на полезный сигнал и затрудняющее его прием. Ниже приведена классификация помех и их источников.
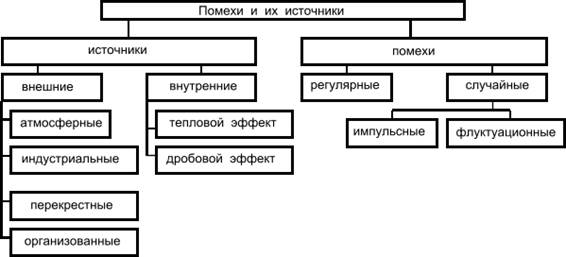
Внешние источники помех вызывают в основном импульсные помехи, а внутренние - флуктуационные. Помехи, накладываясь на видеосигнал, приводят к двум типам искажений: краевые и дробления. Краевые искажения связаны со смещением переднего или заднего фронта импульса. Дробление связано с дроблением единого видеосигнала на некоторое количество более коротких сигналов.
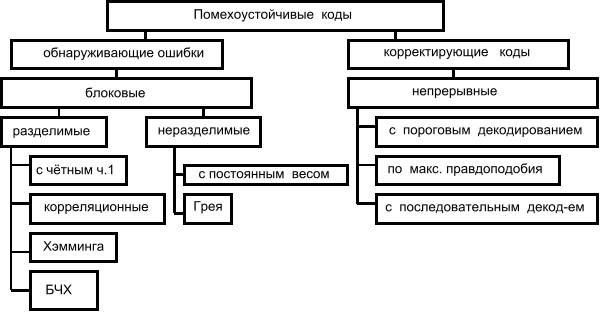
Приведем классификацию помехоустойчивых кодов.
Построение помехоустойчивых кодов в основном связано с добавлением к исходной комбинации (k-символов) контрольных (r-символов) см.на рис.5.1. Закодированная комбинация будет составлять n-символов. Эти коды часто называют (n,k) - коды.
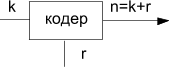 k—число символов в исходной комбинации
k—число символов в исходной комбинации
r—число контрольных символов
Рис.5.1. Получение (n,k)-кодов.
Коды с обнаружением ошибок
Код с проверкой на четность.
Такой код образуется путем добавления к передаваемой комбинации, состоящей из k информационных символов, одного контрольного символа (0 или 1), так, чтобы общее число единиц в передаваемой комбинации было четным.
Пример 5.1. Построим коды для проверки на четность, где k - исходные комбинации, r - контрольные символы.
| k | r | n |
Определим, каковы обнаруживающие свойства этого кода. Вероятность Poo обнаружения ошибок будет равна
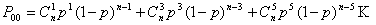
Так как вероятность ошибок 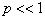 является весьма малой величиной, то можно ограничится
является весьма малой величиной, то можно ограничится 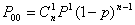
Вероятность появления всевозможных ошибок, как обнаруживаемых так и не обнаруживаемых, равна 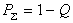 , где
, где 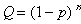 - вероятность отсутствия искажений в кодовой комбинации. Тогда
- вероятность отсутствия искажений в кодовой комбинации. Тогда 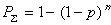 .
.
При передаче большого количества кодовых комбинаций Nk , число кодовых комбинаций, в которых ошибки обнаруживаются, равно: 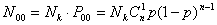
Общее количество комбинаций с обнаруживаемыми и не обнаруживаемыми ошибками равно 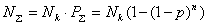
Тогда коэффициент обнаружения Kобн для кода с четной защитой будет равен
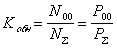
Например, для кода с k=5 и вероятностью ошибки 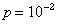 коэффициент обнаружения составит
коэффициент обнаружения составит 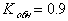 . То есть 90% ошибок обнаруживаем, при этом избыточность будет составлять
. То есть 90% ошибок обнаруживаем, при этом избыточность будет составлять 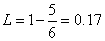 или 17%.
или 17%.
Код с постоянным весом.
Этот код содержит постоянное число единиц и нулей. Число кодовых комбинаций составит 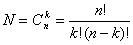
Пример 5.2. Коды с двумя единицами из пяти и тремя единицами из семи.
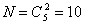
| 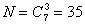
|
Этот код позволяет обнаруживать любые одиночные ошибки и часть многократных ошибок. Не обнаруживаются этим кодом только ошибки смещения, когда одновременно одна единица переходит в ноль и один ноль переходит в единицу, два ноля и две единицы меняются на обратные символы и т.д.
Рассмотрим код с тремя единицами из семи. Для этого кода возможны смещения трех типов.
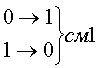
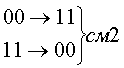
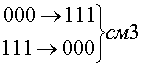
Вероятность появления не обнаруживаемых ошибок смещения
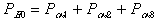 , где
, где 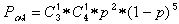
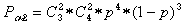
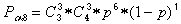
При p<<1 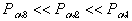 , тогда
, тогда 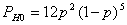
Вероятность появления всевозможных ошибок как обнаруживаемых, так и не обнаруживаемых будет составлять 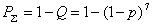
Вероятность обнаруживаемых ошибок 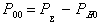 . Тогда коэффициент обнаружения будет равен
. Тогда коэффициент обнаружения будет равен 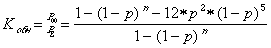
Например, код  при коэффициент обнаружения составит
при коэффициент обнаружения составит 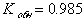 , избыточность L=27%.
, избыточность L=27%.
3. Корреляционный код (Код с удвоением).Элементы данного кода заменяются двумя символами, единица ‘1’ преобразуется в 10, а ноль ‘0’ в 01.
Вместо комбинации 1010011 передается 10011001011010. Ошибка обнаруживается в том случае, если в парных элементах будут одинаковые символы 00 или 11 (вместо 01 и 10).
Например, при k=5, n=10 и вероятности ошибки , 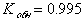 . Но при этом избыточность будет составлять 50%.
. Но при этом избыточность будет составлять 50%.
4. Инверсный код.К исходной комбинации добавляется такая же комбинация по длине. В линию посылается удвоенное число символов. Если в исходной комбинации четное число единиц, то добавляемая комбинация повторяет исходную комбинацию, если нечетное, то добавляемая комбинация является инверсной по отношению к исходной.
| k | r | n |
Прием инверсного кода осуществляется в два этапа. На первом этапе суммируются единицы в первой основной группе символов. Если число единиц четное, то контрольные символы принимаются без изменения, если нечетное, то контрольные символы инвертируются. На втором этапе контрольные символы суммируются с информационными символами по модулю два. Нулевая сумма говорит об отсутствии ошибок. При ненулевой сумме, принятая комбинация бракуется. Покажем суммирование для принятых комбинаций без ошибок (1,3) и с ошибками (2,4).
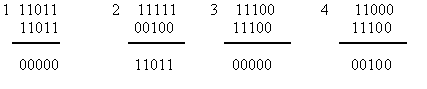
Обнаруживающие способности данного кода достаточно велики. Данный код обнаруживает практически любые ошибки, кроме редких ошибок смещения, которые одновременно происходят как среди информационных символов, так и среди соответствующих контрольных. Например, при k=5, n=10 и . Коэффициент обнаружения будет составлять 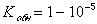 .
.
5. Код Грея. Код Грея используется для преобразования угла поворота тела вращения в код. Принцип работы можно представить по рис.5.2. На пластине, которая вращается на валу, сделаны отверстия, через которые может проходить свет. Причём, диск разбит на сектора, в которых и сделаны эти отверстия. При вращении, свет проходит через них, что приводит к срабатыванию фотоприёмников. При снятии информации в виде двоичных кодов может произойти существенная ошибка. Например, возьмем две соседние цифры 7 и 8. Двоичные коды этих цифр отличаются во всех разрядах.
7 0111 -> 1111
8 1000 -> 0000
Если ошибка произойдет в старшем разряде, то это приведет к максимальной ошибке, на 3600. А код Грея, это такой код в котором все соседние комбинации отличаются только одним символом, поэтому при переходе от изображения одного числа к изображению соседнего происходит изменение только на единицу младшего разряда. Ошибка будет минимальной.
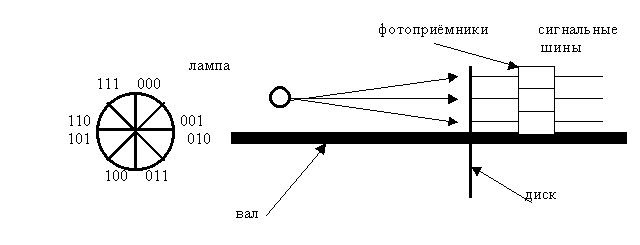
Рис.5.2. Схема съема информации угла поворота вала в код
Код Грея записывается следующим образом
| Номер | Код Грея |
| 0 0 0 0 | |
| 0 0 0 1 | |
| 0 0 1 1 | |
| 0 0 1 0 | |
| 0 1 1 0 | |
| 0 1 1 1 | |
| 0 1 0 1 | |
| 0 1 0 0 | |
| 1 1 0 0 | |
| 1 1 0 1 | |
| 1 1 1 1 | |
| 1 1 1 0 | |
| 1 0 1 0 | |
| 1 0 1 1 | |
| 1 0 0 1 | |
| 1 0 0 0 |
Разряды в коде Грея не имеют постоянного веса. Вес k-разряда определяется следующим образом 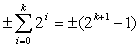 .
.
При этом все нечетные единицы, считая слева направо, имеют положительный вес, а все четные единицы отрицательный.
Например, 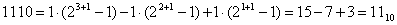
Непостоянство весов разрядов затрудняет выполнение арифметических операций в коде Грея, поэтому необходимо уметь делать перевод кода Грея в обычный двоичный код и наоборот. Алгоритм перевода чисел можно представить следующим образом.
Пусть 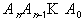 -- двоичный код,
-- двоичный код, 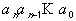 -- код Грея
-- код Грея
Тогда переход из двоичного кода в код Грея выполнится по следующему алгоритму
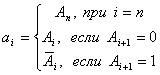
Например, 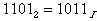 .
.
Обратный переход из кода Грея в двоичный код
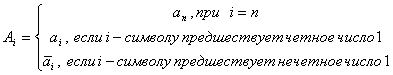

Например, 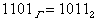 .
.
Корректирующие коды
Корректирующими называются коды позволяющие обнаруживать и исправлять ошибки. Идею представления корректирующих кодов можно представить с помощью N-мерного куба. Возьмем трехмерный куб (рис.5.3), длина ребер, в котором равна одной единице. Вершины такого куба отображают двоичные коды. Минимальное расстояние между вершинами определяется минимальным количеством ребер, находящихся между вершинами. Это расстояние называется кодовым (или хэмминговым) и обозначается буквой d.
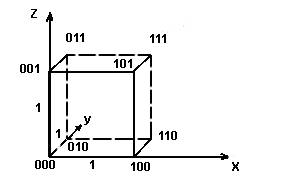
Рис.5.3. Представление двоичных кодов с помощью куба
Иначе, кодовое расстояние - это то минимальное число элементов, в которых одна кодовая комбинация отличается от другой. Для определения кодового расстояния достаточно сравнить две кодовые комбинации по модулю 2. Так, сложив две комбинации
11001010101
определим, что расстояние между ними d=7.
Для кода с N=3 восемь кодовых комбинаций размещаются на вершинах трехмерного куба. Такой код имеет кодовое расстояние d=1, и для передачи используются все восемь кодовых комбинаций 000,001,..,111. Такой код является не помехоустойчивым, он не в состоянии обнаружить ошибку.
Если выберем комбинации с кодовым расстоянием d=2, например, 000,110,101,011, то такой код позволит обнаруживать однократные ошибки. Назовем эти комбинации разрешенными, предназначенными для передачи информации. Все остальные 001,010,100,111 - запрещенные.
Любая одиночная ошибка приводит к тому, что разрешенная комбинация переходит в ближайшую, запрещенную комбинацию (см. рис.5.3). Получив запрещенную комбинацию, мы обнаружим ошибку. Выберем далее вершины с кодовым расстоянием d=3
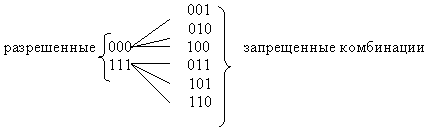
Такой код может исправить одну одиночную ошибку или обнаружить две ошибки. Таким образом, увеличивая кодовое расстояние можно увеличить помехоустойчивость кода. В общем случае кодовое расстояние определяется по формуле d=t + l + 1 где t - число исправляемых ошибок , l - число обнаруживаемых ошибок. Обычно l>t.
Большинство корректирующих кодов являются линейными кодами. Линейные коды - это такие коды, у которых контрольные символы образуются путем линейной комбинации информационных символов. Кроме того, корректирующие коды являются групповыми кодами. Групповые коды (Gn) - это такие коды, которые имеют одну основную операцию. При этом, должно соблюдаться условие замкнутости (то есть, при сложении двух элементов группы получается элемент принадлежащий этой же группе ). Число разрядов в группе не должно увеличиваться. Этому условию удовлетворяет операция поразрядного сложения по модулю 2. В группе, кроме того, должен быть нулевой элемент.
Пример 5.3. Ниже приведены кодовые комбинации, являющиеся группой или нет.
1) 1101 1110 0111 1011 – не группа, так как нет нулевого элемента
2) 0000 1101 1110 0111 – не группа, так как не соблюдается условие замкнутости (1101+1110=0011)
3) 000 001 010 011 100 101 110 111 - группа
4) 000 001 010 111 - подгруппа
Большинство корректирующих кодов образуются путем добавления к исходной k - комбинации r - контрольных символов. В итоге в линию передаются n=k+r символов. При этом корректирующие коды называются (n,k) кодами. Как можно определить необходимое число контрольных символов?
Для построения кода способного обнаруживать и исправлять одиночную ошибку необходимое число контрольных разрядов будет составлять
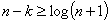 . Это равносильно известной задаче о минимуме числа контрольных вопросов, на которые могут быть даны ответы вида “да” или “нет”, для однозначного определения одного из элементов конечного множества.
. Это равносильно известной задаче о минимуме числа контрольных вопросов, на которые могут быть даны ответы вида “да” или “нет”, для однозначного определения одного из элементов конечного множества.
Если необходимо исправить две ошибки, то число различных исходов будет составлять 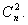 Тогда
Тогда 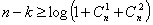 , в этом случае обнаруживаются однократные и двукратные ошибки. В общем случае, число контрольных символов должно быть не меньше
, в этом случае обнаруживаются однократные и двукратные ошибки. В общем случае, число контрольных символов должно быть не меньше
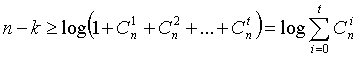 (5.1)
(5.1)
Эта формула называется неравенством Хэмминга, или нижней границей Хэмминга для числа контрольных символов.
Код Хэмминга
Код Хэмминга, являющийся групповым (n,k) кодом, с минимальным расстоянием d=3 позволяет обнаруживать и исправлять однократные ошибки. Для построения кода Хэмминга используется матрица H. 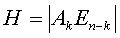 , где Ak- транспонированная подматрица, En-k - единичная подматрица порядка n-k.
, где Ak- транспонированная подматрица, En-k - единичная подматрица порядка n-k.
Если Х - исходная последовательность, то произведение Х·Н=0. Пусть E- вектор ошибок. Тогда (Х+Е)·Н = Х·Н+Е·Н = 0+Е·Н=E·H - синдром или корректор, который позволяет обнаружить и исправить ошибки. Контрольные символы e1 ,e2 ,...,er образуются из информационных символов, путем линейной комбинации 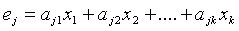 , где аj={0,1} - коэффициенты, взятые из подматрицы A матрицы H.
, где аj={0,1} - коэффициенты, взятые из подматрицы A матрицы H.
Рассмотрим Построение кода Хэмминга для k=4 символам. Число контрольных символов r=n-k можно определить по неравенству Хэмминга для однократной ошибки. Но так, как нам известно, только исходное число символов k, то проще вычислить по эмпирической формуле
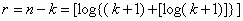 , (5.2)
, (5.2)
где [.] - означает округление до большего ближайшего целого значения. Вычислим для k=4 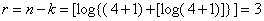 . Получим код (n,k)=(7,4); n=7; k=4; r=n-k=3; d=3. Построим матрицу H.
. Получим код (n,k)=(7,4); n=7; k=4; r=n-k=3; d=3. Построим матрицу H.
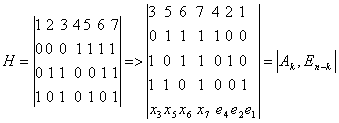
Контрольные символы ej определим по формуле . Например, 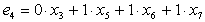 . Для простоты оставляем только слагаемые с единичными коэффициентами. В результате получим систему линейных уравнений, с помощью которых вычисляются контрольные разряды. Каждый контрольный разряд является как бы дополнением для определенных информационных разрядов для проверки на четность.
. Для простоты оставляем только слагаемые с единичными коэффициентами. В результате получим систему линейных уравнений, с помощью которых вычисляются контрольные разряды. Каждый контрольный разряд является как бы дополнением для определенных информационных разрядов для проверки на четность.
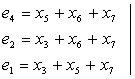
При декодировании вычисляем корректор K=k4k2k1
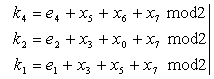
Если корректор равен нулю, следовательно, ошибок нет. Если корректор не равен нулю, то местоположение вектор-столбца матрицы H, совпадающего с вычисленным корректором, указывает место ошибки. При передаче может возникнуть двойная и более ошибка. Корректор также не будет равен нулю. В этом случае произойдет исправление случайного символа и нами будет принят неверный код. Для исключения такого автоматического исправления вводится еще один символ 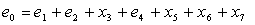 для проверки всей комбинации на четность. Кодовое расстояние d=4. Тогда матрица H будет иметь вид
для проверки всей комбинации на четность. Кодовое расстояние d=4. Тогда матрица H будет иметь вид

Пример 5.4. Дана 1101 - исходная комбинация (k=4). Закодировать ее в коде Хэмминга.
По формуле (5.2) находим число контрольных символов r=3. Берем регистр из 7 ячеек памяти. Размещаем исходную комбинацию в ячейках 3,5,6,7.
1 2 3 4 5 6 7
* * 1 * 1 0 1
Находим контрольные символы
е4 = 5 + 6 + 7 = 1 + 0 + 1 = 0
е2 = 3 + 6 + 7 = 1 + 0 + 1 = 0
е1 = 3 + 5 + 7 = 1 + 1 + 1 = 1
Закодированная комбинация будет иметь вид
1 2 3 4 5 6 7
1 0 1 0 1 0 1
Допустим, что при передаче возникла ошибка, и мы приняли неверную комбинацию
1 2 3 4 5 6 7
1 0 1 0 1 1 1
Проверяем ее
к 4 = 4 + 5 + 6 + 7 = 0 + 1 + 1 + 1 = 1
к2 = 2 + 3 + 6 + 7 = 0 + 1 + 1 + 1 = 1
к1 = 1 + 3 + 5 + 7 = 1 + 1 + 1 + 1 + 0
K= 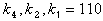 - в шестом разряде ошибка.
- в шестом разряде ошибка.
Если бы нам понадобилось построить код и для проверки двойных ошибок, необходимо было бы ввести еще один дополнительный нулевой разряд.
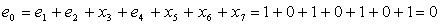
Получим следующий код
0 1 2 3 4 5 6 7
0 1 0 1 0 1 0 1
При передаче и возникновении ошибки код будет иметь вид
0 1 2 3 4 5 6 7
0 1 0 1 0 1 1 1
Проверка в этом случае показала бы, что корректор K=110, а проверка всей комбинации на четность E0 = 0+1+0+1+0+1+1+1=1. Это указывает на одиночную ошибку. Допускается автоматическое исправление ошибки.
Существует следующий алгоритм декодирования кода Хэмминга с d=4
| Корректор - K | Значение E0 | Вывод |
| K=0 | E0=0 | Ошибок нет |
| K#0 | E0#0 | Произошла одиночная ошибка |
| K#0 | E0=0 | Произошла двойная ошибка. Исправление запрещено. |
| K=0 | E0#0 | Произошла тройная или более нечетная ошибка |
Код (7,4) является минимально возможным кодом с достаточно большой избыточностью. Эффективность кода (k/n) растет с увеличением длины кода
| Длина кода - n | ||||
| Число информационных разрядов - k | ||||
| Число контрольных разрядов - r | ||||
| Эффективность кода k/n | 0,57 | 0,73 | 0,84 | 0,9 |
|
из
5.00
|
Обсуждение в статье: Код с постоянным весом |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы