 |
Главная |


ИНТЕРВАЛЫ ПРОГНОЗА ПО УРАВНЕНИЮ РЕГРЕССИИ
|
из
5.00
|
Одной из центральных задач эконометрического моделирования является предсказание (прогнозирование) значений зависимой переменной при определенных значениях объясняющих переменных при определенных значениях объясняющих переменных. Здесь возможен двоякий подход: либо предсказать условное математическое ожидание зависимой переменной (предсказание среднего значения), либо прогнозировать некоторое конкретное значение зависимой переменной (предсказание конкретного значения).
Замечание. Некоторые авторы различают такие понятия, как прогнозирование и предсказание. Если значение объясняющей переменной X известно точно, то оценивание зависимой переменной Y называется предсказанием. Если же значение объясняющей переменной X неизвестно точно, то говорят, что делается прогноз значения Y. Такая ситуация характерна для временных рядов. В данном случае мы не будем различать предсказание и прогноз.
Различают точечное и интервальное прогнозирование. В первом случае оценка – некоторое число, во втором – интервал, в котором находится истинное значение зависимой переменной с заданным уровнем значимости.
а) Предсказание среднего значения. Пусть построено уравнение парной регрессии  , на основе которого необходимо предсказать условное математическое ожидание
, на основе которого необходимо предсказать условное математическое ожидание  . В данном случае значение
. В данном случае значение  является точечной оценкой . Тогда естественно возникает вопрос, как сильно может отклониться модельное значение
является точечной оценкой . Тогда естественно возникает вопрос, как сильно может отклониться модельное значение  , рассчитанное по эмпирическому уравнению, от соответствующего условного математического ожидания. Ответ на этот вопрос даётся на основе интервальных оценок, построенных с заданным уровнем значимости a при любом конкретном значении xp объясняющей переменной.
, рассчитанное по эмпирическому уравнению, от соответствующего условного математического ожидания. Ответ на этот вопрос даётся на основе интервальных оценок, построенных с заданным уровнем значимости a при любом конкретном значении xp объясняющей переменной.
Запишем эмпирическое уравнение регрессии в виде
 .
.
Здесь выделены две независимые составляющие: средняя  и приращение
и приращение  . Отсюда вытекает, что дисперсия
. Отсюда вытекает, что дисперсия  будет равна
будет равна
 . (5.53)
. (5.53)
Из теории выборки известно, что
 .
.
Используя в качестве оценки s2 остаточную дисперсию S2, получим
 . (5.54)
. (5.54)
Дисперсия коэффициента регрессии, как уже было показано
 . (5.55)
. (5.55)
Подставляя найденные дисперсии в (5.41), получим
 . (5.56)
. (5.56)
Таким образом, формула расчета стандартной ошибки предсказываемого по линии регрессии среднего значения Y имеет вид
 . (5.57)
. (5.57)
Величина стандартной ошибки  , как видно из формулы, достигает минимума при
, как видно из формулы, достигает минимума при  , и возрастает по мере удаления от
, и возрастает по мере удаления от  в любом направлении. Иными словами, больше разность между
в любом направлении. Иными словами, больше разность между  и , тем больше ошибка с которой предсказывается среднее значение y для заданного значения xp. Можно ожидать наилучшие результаты прогноза, если значения xp находятся в центре области наблюдений X и нельзя ожидать хороших результатов прогноза по мере удаления от .
и , тем больше ошибка с которой предсказывается среднее значение y для заданного значения xp. Можно ожидать наилучшие результаты прогноза, если значения xp находятся в центре области наблюдений X и нельзя ожидать хороших результатов прогноза по мере удаления от .
 Случайная величина
Случайная величина
 (5.58)
(5.58)
имеет распределение Стьюдента с числом степеней свободы n=n–2 (в рамках нормальной классической модели). Следовательно, по таблице критических точек распределения Стьюдента по требуемому уровню значимости a и числу степеней свободы n=n–2 можно определить критическую точку  , удовлетворяющую условию
, удовлетворяющую условию
 .
.
С учетом (5.46) имеем:
 .
.
Отсюда, после некоторых алгебраических преобразований, получим, что доверительный интервал для  имеет вид:
имеет вид:
 , (5.59)
, (5.59)
где предельная ошибка Dp имеет вид
 . (5.60)
. (5.60)
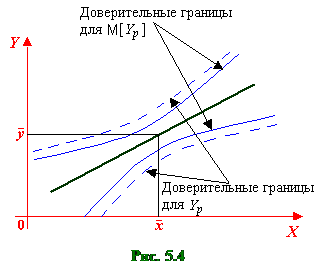
Из формул (5.57) и (5.60) видно, что величина (длина) доверительного интервала зависит от значения объясняющей переменной xp: при она минимальна, а по мере удаления xp от величина доверительного интервала увеличивается (рис. 5.4). Таким образом, прогноз значений зависимой переменной Y по уравнению регрессии оправдан, если значение xp объясняющей переменной X не выходит за диапазон ее значений по выборке (причем более точный, чем ближе xp к ). Другими словами, экстраполяция кривой регрессии, т.е. её использование вне пределов обследованного диапазона значений объясняющей переменной (даже если она оправдана для рассматриваемой переменной исходя из смысла решаемой задачи) может привести к значительным погрешностям.
б) Предсказание индивидуальных значений зависимой переменной. На практике иногда более важно знать дисперсию Y, чем ее средние значения или доверительные интервалы для условных математических ожиданий. Это связано с тем, что фактические значения Y варьируют около среднего значения  . Индивидуальные значения Y могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S2. Поэтому ошибка предсказываемого индивидуального значения Y должны включать не только стандартную ошибку
. Индивидуальные значения Y могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S2. Поэтому ошибка предсказываемого индивидуального значения Y должны включать не только стандартную ошибку  , но и случайную ошибку S. Это позволяет определять допустимые границы для конкретного значения Y.
, но и случайную ошибку S. Это позволяет определять допустимые границы для конкретного значения Y.
Пусть нас интересует некоторое возможное значение y0 переменной Y при определенном значении xp объясняющей переменной X. Предсказанное по уравнению регрессии значение Y при X=xp составляет yp. Если рассматривать значение y0 как случайную величину Y0, а yp – как случайную величину Yp, то можно отметить, что
 ,
,
 .
.
Случайные величины Y0 и Yp являются независимыми, а следовательно, случайная величина U= Y0–Yp имеет нормальное распределение с
 и
и  . (5.61)
. (5.61)
Используя в качестве s2 остаточную дисперсию S2, получим формулу расчета стандартной ошибки предсказываемого по линии регрессии индивидуального значения Y:
 . (5.63)
. (5.63)
Случайная величина
 (5.64)
(5.64)
имеет распределение Стьюдента с числом степеней свободы k=n–2. На основании этого можно построить доверительный интервал для индивидуальных значений Yp:
 , (5.65)
, (5.65)
где предельная ошибка Du имеет вид
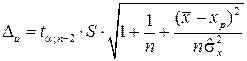 . (5.66)
. (5.66)
Заметим, что данный интервал шире доверительного интервала для условного математического ожидания (см. рис. 5.4).
Пример 5.5. По данным примеров 5.1-5.3 рассчитать 95%-ый доверительный интервал для условного математического ожидания и индивидуального значения при xp=160.
Решение. В примере 5.1 было найдено  . Воспользовавшись формулой (5.48), найдем предельную ошибку для условного математического ожидания
. Воспользовавшись формулой (5.48), найдем предельную ошибку для условного математического ожидания
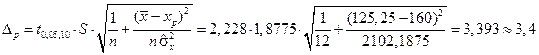 .
.
Тогда доверительный интервал для среднего значения  на уровне значимости a=0,05 будет иметь вид
на уровне значимости a=0,05 будет иметь вид
(149,8; 156,6).
Другими словами, среднее потребление при доходе 160 с вероятностью 0,95 будет находиться в интервале (149,8; 156,6).
Рассчитаем границы интервала, в котором будет сосредоточено не менее 95% возможных объёмов потребления при уровне дохода xp=160, т.е. доверительный интервал для индивидуального значения . Найдем предельную ошибку для индивидуального значения
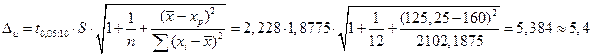 .
.
Тогда интервал, в котором будут находиться , по крайней мере, 95% индивидуальных объёмов потребления при доходе xp=160, имеет вид
(147,8; 158,6).
Нетрудно заметить, что он включает в себя доверительный интервал для условного среднего потребления. â
ПРИМЕРЫ
Пример 5.65.По территориям региона приводятся данные за 199X г. (таб. 1.1).
Табл. 5.3
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., x | Среднедневная заработная плата, руб., y |
Задания:
1. Рассчитать линейный коэффициент парной корреляции, оценить его статистическую значимость и построить для него доверительный интервал с уровнем значимости a=0,05.
2. Построить линейное уравнение парной регрессии y на x и оценить статистическую значимость параметров регрессии. Сделать рисунок.
3. Оценить качество уравнения регрессии при помощи коэффициента детерминации. Проверить качество уравнения регрессии при помощи F-критерия Фишера.
4. Выполнить прогноз заработной платы y при прогнозном значении среднедушевого прожиточного минимума x, составляющем 107% от среднего уровня. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал для уровня значимости a=0,05. Сделать выводы.
Решение
1. Для определения степени тесноты связи обычно используют коэффициент корреляции:
 ,
,
где  ,
,  – выборочные дисперсии переменных x и y. Для расчета коэффициента корреляции строим расчетную таблицу (табл. 5.4):
– выборочные дисперсии переменных x и y. Для расчета коэффициента корреляции строим расчетную таблицу (табл. 5.4):
Таблица 5.4
| x | y | xy | x2 | y2 | 
| 
| e2 | |
| 148,77 | -15,77 | 248,70 | ||||||
| 152,45 | -4,45 | 19,82 | ||||||
| 157,05 | -23,05 | 531,48 | ||||||
| 149,69 | 4,31 | 18,57 | ||||||
| 158,89 | 3,11 | 9,64 | ||||||
| 174,54 | 20,46 | 418,52 | ||||||
| 138,65 | 0,35 | 0,13 | ||||||
| 157,97 | 0,03 | 0,00 | ||||||
| 144,17 | 7,83 | 61,34 | ||||||
| 157,05 | 4,95 | 24,46 | ||||||
| 146,93 | 12,07 | 145,70 | ||||||
| 182,83 | -9,83 | 96,55 | ||||||
| Итого | – | 1574,92 | ||||||
| Среднее значение | 85,58 | 155,75 | 13484,00 | 7492,25 | 24531,42 | – | – | – |
По данным таблицы находим:
 ,
,  ,
,  ,
,  ,
,
 ,
,  ,
,  ,
,  ,
,
 ,
,  .
.
Таким образом, между заработной платой (y) и среднедушевым прожиточным минимумом (x) существует прямая достаточно сильная корреляционная зависимость.
Для оценки статистической значимости коэффициента корреляции рассчитаем двухсторонний t-критерий Стьюдента:
 ,
,
который имеет распределение Стьюдента с k=n–2 и уровнем значимости a. В нашем случае
 и
и  .
.
Поскольку  , то коэффициент корреляции существенно отличается от нуля.
, то коэффициент корреляции существенно отличается от нуля.
Для значимого коэффициента можно построить доверительный интервал, который с заданной вероятностью содержит неизвестный генеральный коэффициент корреляции. Для построения интервальной оценки (для малых выборок n<30), используют z-преобразование Фишера:

Распределение z уже при небольших n является приближенным нормальным распределением с математическим ожиданием  и дисперсией
и дисперсией  . Поэтому вначале строят доверительный интервал для M[z], а затем делают обратное z-преобразование. Применяя z-преобразование для найденного коэффициента корреляции, получим
. Поэтому вначале строят доверительный интервал для M[z], а затем делают обратное z-преобразование. Применяя z-преобразование для найденного коэффициента корреляции, получим
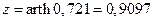 .
.
Доверительный интервал для M(z) будет иметь вид
 ,
,
где tg находится с помощью функции Лапласа F(tg)=g/2. Для g=0,95 имеем tg=1,96. Тогда
 ,
,
или  . Обратное z-преобразование осуществляется по формуле
. Обратное z-преобразование осуществляется по формуле

В результате находим
 .
.
В указанных границах на уровне значимости 0,05 (с надежностью 0,95) заключен генеральный коэффициент корреляции r.
2. Таким образом, между переменными x и y имеет существенная корреляционная зависимость. Будем считать, что эта зависимость является линейной. Модель парной линейной регрессии имеет вид
 ,
,
где y – зависимая переменная (результативный признак), x – независимая (объясняющая) переменная, e – случайные отклонения, b0 и b1 – параметры регрессии. По выборке ограниченного объема можно построить эмпирическое уравнение регрессии:
 ,
,
где b0 и b1 – эмпирические коэффициенты регрессии. Для оценки параметров регрессии обычно используют метод наименьших квадратов (МНК). В соответствие с МНК, сумма квадратов отклонений фактических значений зависимой переменной y от теоретических  была минимальной:
была минимальной:
 ,
,
где 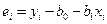 – отклонения yi от оцененной линии регрессии. Необходимым условием существования минимума функции двух переменных
– отклонения yi от оцененной линии регрессии. Необходимым условием существования минимума функции двух переменных  является равенство нулю ее частных производных по неизвестным параметрам b0 и b1. В результате получаем систему нормальных уравнений:
является равенство нулю ее частных производных по неизвестным параметрам b0 и b1. В результате получаем систему нормальных уравнений:

Решая эту систему, найдем
 ,
,  .
.
По данным таблицы находим
 ;
;
 .
.
Получено уравнение регрессии:
 . (5.78)
. (5.78)
Параметр b1 называется коэффициентом регрессии. Его величина показывает среднее изменение результата с изменением фактора на одну единицу. В рассматриваемом случае, с увеличением среднедушевого минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.

Рис. 5.5
Проверка адекватности моделей, построенных на основе уравнений регрессии, начинается с проверки статистической значимости каждого коэффициента регрессии. Найдем стандартную ошибку регрессии:
 и
и  .
.
Значимость коэффициентов регрессии осуществляется с помощью t-критерия Стьюдента:
 ,
,
где  – стандартная ошибка коэффициента регрессии bi.
– стандартная ошибка коэффициента регрессии bi.
Для коэффициента b1 оценку дисперсии можно получить по формуле:
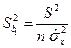 .
.
В нашем случае

Следовательно,
 .
.
Отметим, что для парной линейной регрессии t-критерий для коэффициента корреляции rxy и коэффициента регрессии b1 совпадают.
Для коэффициента b0 оценку дисперсии можно получить по формуле  . Тогда
. Тогда

Критическое значение критерия было уже найдено 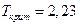 . Поскольку
. Поскольку  и
и  , то коэффициенты регрессии значимо отличаются от нуля. Следовательно, для них можно построить доверительные интервалы.
, то коэффициенты регрессии значимо отличаются от нуля. Следовательно, для них можно построить доверительные интервалы.
Определим предельные ошибки для каждого показателя:  ,
,  , где
, где  . В нашем случае
. В нашем случае
 ,
,  .
.
В результате, получаем следующие доверительные интервалы для коэффициентов регрессии:
 и
и  ,
,
или
 и
и 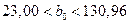 .
.
3. Оценку качества построенной модели дает коэффициент детерминации.
Коэффициент детерминации для линейной модели равен квадрата коэффициента корреляции
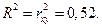
Это означает, что 52% вариации заработной платы (y) объясняется вариацией фактора x – среднедушевого прожиточного минимума.
Значимость уравнения регрессии проверяется при помощи F-критерия Фишера, для линейной парной регрессии он будет иметь вид
 ,
,
где F подчиняется распределению Фишера с уровнем значимости a и степенями свободы k1=1 и k2=n–2. В нашем случае
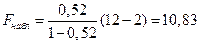 .
.
Поскольку критическое значение критерия равно

и  , то признается статистическая значимость построенного уравнения регрессии. Отметим, что для линейной модели F- и t-критерии связаны равенством
, то признается статистическая значимость построенного уравнения регрессии. Отметим, что для линейной модели F- и t-критерии связаны равенством  , что можно использовать для проверки расчётов.
, что можно использовать для проверки расчётов.
4. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Прогнозное значение yp определяется путем подстановки в уравнение регрессии (1.16) соответствующего (прогнозного) значения xp. В нашем случае прогнозное значение прожиточного минимума составит:  , тогда прогнозное значение прожиточного минимума составит:
, тогда прогнозное значение прожиточного минимума составит:

Средняя стандартная ошибка прогноза вычисляется по формуле:
 .
.
Поскольку , то

Предельная ошибка прогноза, которая в 95% случаев не будет превышена, составит:
 .
.
Доверительный интервал прогноза
 , или
, или  .
.
Выполненный прогноз среднемесячной заработной платы оказался надежным (g=0,95) и относительно точным, т.к. относительная точность прогноза составила 29,4/161,2×100%=18,2%. â
ЛЕКЦИЯ 5 99
§5.2. Анализ точности оценок коэффициентов регрессии 99
5.2.1. Оценка дисперсии случайного отклонения 99
5.2.2. Проверка гипотез относительно коэффициентов регрессии 100
5.2.3. Интервальные оценка коэффициентов регрессии 103
§5.3. Показатели качества уравнения регрессии 104
5.3.1. Коэффициент детерминации 104
5.3.2. Проверка общего качества уравнения регрессии: F-тест 106
5.3.3. Проверка общего качества уравнения регрессии: t-тест 108
§5.4. Интервалы прогноза по уравнению регрессии 108
§5.5. Примеры 112
|
из
5.00
|
Обсуждение в статье: ИНТЕРВАЛЫ ПРОГНОЗА ПО УРАВНЕНИЮ РЕГРЕССИИ |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы