 |
Главная |


Диагностирование автокорреляции
|
из
5.00
|
Возможные методы определения автокорреляции:
- Графический метод
- Метод рядов
- Критерий Дарбина-Уотсона
- Тест серий (Бреуша-Годфри)
- Q-тест Льюинга-Бокса
16. Теорема Гаусса-Маркова
Условия Гаусса – Маркова.
теорема ГауССа-Маркова применительно к эконометрики. Достоинства:
1. Наиболее простой метод выбора значений b1 и b2, чтобы остатки были минимальными;
2. При выполнении условий Гаусса-Маркова МНК-оценки будут наилучшими (наиболее эффективными) линейными (комбинации Yi) несмещёнными оценками параметров регрессии (b1 и b2).
Условия Гаусса-Маркова:
- модель линейна по параметрам и правильно специфицирована;
- объясняющая переменная в выборке имеет некоторую вариацию;
- математическое ожидание случайного члена равно нулю;
- случайный член гомоскедастичен;
- значения случайного члена имеют взаимно независимые распределения;
- случайный член имеет нормальное распределение
Недостатки: МНК-оценки являются эффективными линейными несмещёнными ТОЛЬКО при выполнении ВСЕХ условий Гаусса-Маркова, что на практике встречается редко.

Выводы из теоремы:
Эффективность оценки означает, что она обладает наименьшей дисперсией.
Оценка линейна по наблюдениям Y. При увеличении объема выборки надежность оценок увеличивается.
Несмещённость оценки означает, что её математическое ожидание равно истинному значению.
17. Нелинейная регрессия
Нелинейная регрессия — частный случай регрессионного анализа, в котором рассматриваемая регрессионная модель есть функция, зависящая от параметров и от одной или нескольких свободных переменных. Зависимость от параметров предполагается нелинейной.
нелинейными оказываются производственные функции (зависимость между объемом произведенной продукции и основными факторами производства - трудом, капиталом и т. п.), функции спроса (зависимость между спросом на товары или услуги и их ценами или доходом) и др.
Различают два класса нелинейных регрессий:
- регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам;
- регрессии, нелинейные по оцениваемым параметрам.
Примером нелинейной регрессии по включаемым в нее объясняющим переменным могут служить следующие функции:
- полиномы разных степеней;
- равносторонняя гипербола - 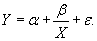
К нелинейным регрессиям по оцениваемым параметрам относятся функции:
- степенная - 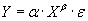 ;
;
- показательная -  ;
;
- экспоненциальная - 
Из нелинейных функций, параметры которых без особых затруднений оцениваются методом наименьших квадратов (МНК), следует назвать хорошо известную в эконометрике равностороннюю гиперболу  Она может быть использована не только для характеристики связи удельных расходов сырья, материалов, топлива с объемом выпускаемой продукции, времени обращения товаров от величины товарооборота, т. е. на микроуровне, но и на макроуровне. Классическим ее примером является кривая Филлипса, характеризующая нелинейное соотношение между нормой безработицы
Она может быть использована не только для характеристики связи удельных расходов сырья, материалов, топлива с объемом выпускаемой продукции, времени обращения товаров от величины товарооборота, т. е. на микроуровне, но и на макроуровне. Классическим ее примером является кривая Филлипса, характеризующая нелинейное соотношение между нормой безработицы 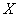 и процентом прироста заработной платы
и процентом прироста заработной платы 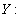
18. Тестирование авткорреляции. Статистика Дарбина-Уотсона
Критерий Дарбина—Уотсона (или DW-критерий) — статистический критерий, используемый для тестирования автокорреляции первого порядка элементов исследуемой последовательности. Наиболее часто применяется при анализе временных рядов и остатков регрессионных моделей.
Чаще всего тестируется наличие в случайных ошибках авторегрессионного процесса первого порядка. Для тестирования нулевой гипотезы, о равенстве коэффициента автокорреляции нулю чаще всего применяют критерий Дарбина-Уотсона. При наличии лаговой зависимой переменной в модели данный критерий неприменим, можно использовать асимптотический h-тест Дарбина. Оба эти теста предназначены для проверки автокорреляции случайных ошибок первого порядка. Для тестирования автокорреляции случайных ошибок большего порядка можно использовать более универсальный асимптотический LM-тест Бройша-Годфри. В данном тесте случайные ошибки не обязательно должны быть нормально распределены. Тест применим также и в авторегрессионных моделях (в отличие от критерия Дарбина-Уотсона).
Критерий Дарбина—Уотсона рассчитывается по следующей формуле:
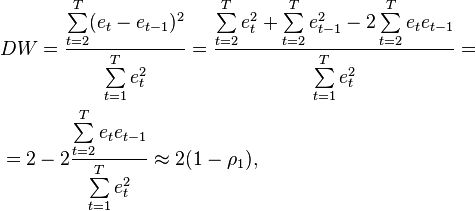
где 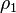 — коэффициент автокорреляции первого порядка.
— коэффициент автокорреляции первого порядка.
Подразумевается, что в модели регрессии 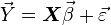 ошибки специфицированы как
ошибки специфицированы как 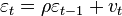 , где
, где 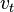 распределено, как белый шум.
распределено, как белый шум. 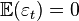 ,
, 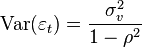 , а
, а 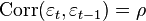 , где
, где 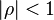 .
.
В случае отсутствия автокорреляции  ; при положительной автокорреляции
; при положительной автокорреляции 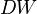 стремится к нулю, а при отрицательной — к 4:
стремится к нулю, а при отрицательной — к 4:
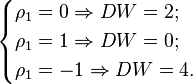
---------------------------------------
Используется для определения наличия/отсутствия автокорреляции между случайными членами  которая выражается коэффициентом корреляции
которая выражается коэффициентом корреляции  .
.
Поскольку значения случайных ошибок 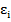 неизвестны, проверяется статистическая некоррелированность остатков
неизвестны, проверяется статистическая некоррелированность остатков 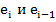 .
.
В тесте Дарбина–Уотсона для оценки корреляции используется статистика вида:
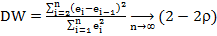
где – остатки, n – количество наблюдений, – коэффициент корреляции.
В случае отсутствия автокорреляции DW=2 (при 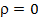 ), при положительной автокорреляции DW стремится к нулю (при
), при положительной автокорреляции DW стремится к нулю (при 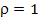 ), а при отрицательной – к 4 (при
), а при отрицательной – к 4 (при 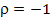 ).
).
На практике проверка гипотезы об отсутствии автокорреляции осуществляется с помощью таблицы критических значений критерия Дарбина-Уотсона:  и
и 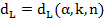 , где n – количество наблюдений, k – количество переменных в модели, α – уровень значимости.
, где n – количество наблюдений, k – количество переменных в модели, α – уровень значимости.
А) 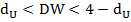 – автокорреляция отсутствует.
– автокорреляция отсутствует.
Б) 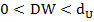 – существует положительная автокорреляция.
– существует положительная автокорреляция.
В) 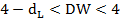 – существует отрицательная автокорреляция.
– существует отрицательная автокорреляция.
Г)  или
или 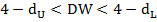 – область неопределенности критерия.
– область неопределенности критерия.
Если фактически наблюдаемое значение DW попадает в зону неопределенности, то на практике предполагают существование автокорреляции.
19. Способы противодействия автокорреляции.
Причиной автокорреляции остатков может быть либо неверная спецификация модели, либо наличие неучтенных факторов. Устранение этих причин не всегда дает нужные результаты. Автокорреляция остатков имеет собственные внутренние причины, связанные с автокорреляционной зависимостью.
Пусть исходное уравнение регрессии 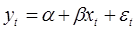 содержит автокорреляцию случайных членов.
содержит автокорреляцию случайных членов.
Допустим, что автокорреляция подчиняется автокорреляционной схеме первого порядка: 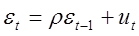 , где
, где 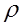 - коэффициент автокорреляции, а
- коэффициент автокорреляции, а 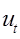 - случайный член, удовлетворяющий предпосылкам МНК.
- случайный член, удовлетворяющий предпосылкам МНК.
Данная схема оказывается авторегрессионой, поскольку 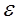 определяется значениями этой же величины с запаздыванием, и схемой первого порядка, потому что в этом случае запаздывание равно единице.
определяется значениями этой же величины с запаздыванием, и схемой первого порядка, потому что в этом случае запаздывание равно единице.
Величина 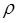 есть коэффициент корреляции между двумя соседними ошибками. Пусть известно. Преобразуем исходное уравнение регрессии следующим образом:
есть коэффициент корреляции между двумя соседними ошибками. Пусть известно. Преобразуем исходное уравнение регрессии следующим образом:
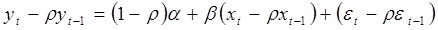 .
.
Обозначим: 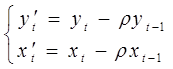 .
.
Это преобразование переменных называется авторегрессионым (AR), или преобразованием Бокса-Дженкинса.
Тогда преобразованное уравнение 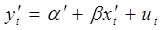 , где
, где 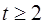 ,
, 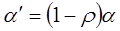 , не содержит автокорреляцию, и для оценки его параметров
, не содержит автокорреляцию, и для оценки его параметров 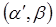 используется обычный МНК.
используется обычный МНК.
Способ вычисления 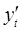 и
и 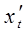 приводит к потере первого наблюдения. Эта проблема при малых выборках обычно преодолевается с помощью поправки Прайса-Винстена:
приводит к потере первого наблюдения. Эта проблема при малых выборках обычно преодолевается с помощью поправки Прайса-Винстена:
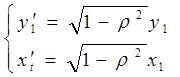
Оценка коэффициента 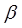 из этой зависимости непосредственно используется и для исходного уравнения, а коэффициент рассчитывается по формуле:
из этой зависимости непосредственно используется и для исходного уравнения, а коэффициент рассчитывается по формуле: 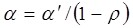 .
.
На практике величина 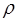 неизвестна, ее оценка получается одновременно с оценками
неизвестна, ее оценка получается одновременно с оценками 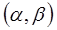 в результате следующих итеративных процедур.
в результате следующих итеративных процедур.
Процедура Кохрейна-Оркатта. Процедура включает следующие этапы:
1. Применяя МНК к исходному уравнению регрессии, получают первоначальные оценки параметров  и
и 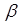 ;
;
2. Вычисляют остатки 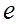 и в качестве оценки
и в качестве оценки 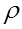 используют коэффициент автокорреляции остатков первого порядка, т.е. полугают
используют коэффициент автокорреляции остатков первого порядка, т.е. полугают 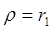 ;
;
3. Применяя МНК к преобразованному уравнению, получают новые оценки параметров 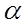 и
и 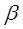 .
.
Процесс обычно заканчивается, когда очередное приближение 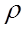 мало отличается от предыдущего. Процедура Кохрейна-Оркатта реализована в большинстве эконометрических компьютерных программах.
мало отличается от предыдущего. Процедура Кохрейна-Оркатта реализована в большинстве эконометрических компьютерных программах.
Процедура Хильдрата-Лу. Эта процедура, также широко применяема в регрессионных пакетах, основана на тех же самых принципах, но использует другой алгоритм вычислений:
1. Преобразованное уравнение оценивают для каждого значения 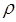 из интервала (-1;1) с заданным шагом внутри его;
из интервала (-1;1) с заданным шагом внутри его;
2. Выбирают значение  , для которого сумма квадратов остатков в преобразованном уравнении минимальна, а коэффициенты регрессии определяются при оценивании преобразованного уравнения с использованием этого значения.
, для которого сумма квадратов остатков в преобразованном уравнении минимальна, а коэффициенты регрессии определяются при оценивании преобразованного уравнения с использованием этого значения.
-----------------------------------
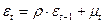 (1)
(1)
Наиболее лучший способ устранения – это определить фактор, который вызывает автокорреляцию остатков и включает его в уравнение регрессии, но это трудно сделать, так как:
- нам неизвестен фактор
- этот фактор трудно измерить
Поэтому используют другие способы. Пусть закономерность, описывающая автокорреляцию и нам известно 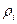 . Для простоты рассмотрим уравнение 1-го порядка:
. Для простоты рассмотрим уравнение 1-го порядка:
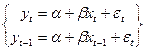 (
( 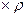 ) (2)
) (2)
Получим 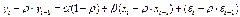
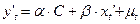 (3), следовательно полностью устранена автокорреляция.
(3), следовательно полностью устранена автокорреляция.
При использовании такого подхода пропадает первое наблюдение. Если выборка маленькая, то потеря 1-го наблюдения может снизить эффективность оценок, вызванную автокорреляцией остатков.
Для возвращения 1-го наблюдения используется следующий подход. Если уравнение (3) имеет случайную составляющую, не связанную с другими случайными остатками в наблюдениях 2,3,4…n, то эти случайные составляющие не коррелируют и с 1-ым остатком, т.е. 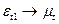 , а значит мы можем использовать 1-ое наблюдение без преобразований:
, а значит мы можем использовать 1-ое наблюдение без преобразований: 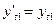
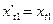

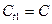 . Однако в этом случае уравнение (1) будет оказывать, при применении МНК, неоправданно большое влияние на определенные оценки параметров.
. Однако в этом случае уравнение (1) будет оказывать, при применении МНК, неоправданно большое влияние на определенные оценки параметров.
Для устранения этого дисбаланса между уравнениями Прайс и Уинстен предложили умножить 1-ое уравнение на поправочный коэффициент  . В этом случае уравнение становится соизмеримым с другими уравнениями.
. В этом случае уравнение становится соизмеримым с другими уравнениями.
Метод Кокрана-Оркатта
Данный метод используется для устранения автокорреляции итерационную процедуру, которую можно представить в виде следующих этапов:
- оцениваем исходное регрессионное уравнение, то есть находим λ и β.
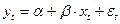
- вычисляем остатки
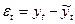
- находим оценку ρ коэффициента автокорреляции (1)
- используя данную оценку ρ находим уравнение (3)
- производим определение параметров уравнения (3) и находим новые значения оценок λ и β
- повторно вычисляем остатки
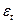 и фактически возвращаемся к этому №3
и фактически возвращаемся к этому №3
Процесс повторяется до тех пор, пока не будет получена требуемая точность сходимости в оценках λ и β
Метод Хилдрета–Лу
В данном методе исследователь задает интервал изменения величины ρ, допустим в пределах 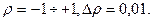 Для каждого значения ρ производится оценка параметров λ и β из уравнения (3). Затем из полученных результатов выбирается такой, который дает минимальную стандартную ошибку для преобразованного уравнения. Используемые в этом уравнении значения ρ, λ и β принимаются за искомые.
Для каждого значения ρ производится оценка параметров λ и β из уравнения (3). Затем из полученных результатов выбирается такой, который дает минимальную стандартную ошибку для преобразованного уравнения. Используемые в этом уравнении значения ρ, λ и β принимаются за искомые.
В случае, когда статистика Дарбина–Уотсона указ.на очень тесную положительную автокорреляцию, можно использовать упрощенную процедуру, в которой принимается ρ=1. В этом случае уравнение (3) принимает следующий вид: 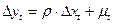
20. Ложные регрессии
Выявить ложную регрессию позволяет анализ остатков. Если коэффициенты автокорреляции остатков велики, то нарушено условие независимости ошибок.
Ошибка ложного регрессионного анализа заключается в том, что стандартная регрессионная модель применяется в ситуации, когда основные предположения регрессии не выполняются.
-Стандартная ошибка оценки может быть занижена
-Нельзя использовать выводы, сделанные на основе t и F
-Стандартные ошибки коэффициентов регрессии занижены => ложное уравнение регрессии
Очень часто экономические процессы бывают нестационарными. В качестве примера можно привести объем производства, уровень цен. Уровень безработицы как процент трудоспособного населения это, с другой стороны, пример стационарной переменной. В данном случае термин “стационарность” употреблен не в строгом смысле. Скорее подразумевается, что дисперсия процесса ограничена.
Стационарность регрессоров является очень важным условием при оценивании регрессионных моделей. Если модель неверно специфицирована, и некоторые из переменных, которые в нее неправильно включены, являются I(1), то полученные оценки будут очень плохими. Они не будут обладать свойством состоятельности, то есть не будут сходиться по вероятности к истинным значениям параметров по мере увеличения размеров выборки. Привычные показатели, такие как коэффициент детерминации R2, t-статистики, F-статистики, будут указывать на наличие связи там, где на самом деле ее нет. Такой эффект называют ложной регрессией.
Показать эффект ложной регрессии можно с помощью метода Монте-Карло. Сгенерируем достаточно много раз два случайных блуждания с независимыми нормально распределенными ошибками (e t,x t ~ NID(0,1)):
Yt = Yt–1 + et, Xt = Xt–1 + x t.

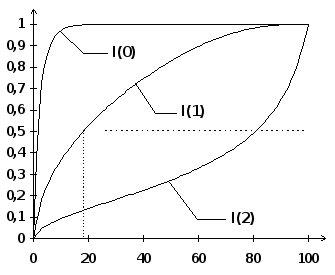
à) á)
â)
Yt = a + bXt + ut I(0) : Xt, Yt ~ NID (0,1)
I(1) : DXt, DYt ~ NID (0,1) I(2) : D2Xt, D2Yt ~ NID (0,1)
а),в) — плотности распределения R2,
б) — (кумулятивные) функции распределения
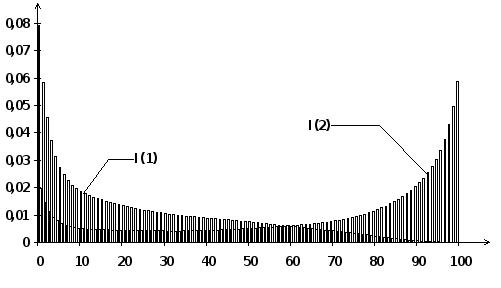
Оценив достаточно много раз регрессию Yt по константе и Xt вида Yt =a +bCt+ut мы получим экспериментальное распределение различных статистик. Например, эксперименты Монте-Карло показывают, что t-статистика для b при 50 наблюдениях и номинальном уровне значимости 5% в действительности отвергает верную гипотезу об отсутствии связи примерно в 75% случаев. Вместо того, чтобы использовать 5%-ю критическую границу t5% » 2 нужно использовать t5% = 11,2.
На рисунке показаны распределения коэффициента детерминации R (в процентах) при длине выборки в 50 наблюдений. Хотя процессы независимы, но регрессия с большой вероятностью дает высокий коэффициент детерминации из-за нестационарности. Два независимых I(1)-процесса примерно в половине случаев дают коэффициент детерминации превышающий 20%. Для I(2)-процессов примерно в половине случаев коэффициент детерминации превышает 80% !
То же самое, хотя и в меньшей степени, можно наблюдать и в случае двух стационарных AR(1)-процессов с коэффициентом автокорреляции r близким к 1. Отличие заключается в том, что здесь ложная связь асимптотически (при стремлении размеров выборки к бесконечности) исчезает, а в случае I(1)-процессов — нет. Все же проблема остается серьезной, поскольку на практике экономист имеет дело с конечными и часто довольно малыми выборками.
О процессе типа случайного блуждания без дрейфа говорят как о стохастическом тренде, поскольку влияние каждой ошибки не исчезает со временем.
Наличие обычного детерминированного тренда также может приводить к появлению ложной регрессии. Пусть, например Yt и Xtпорождаются процессами Yt = a + b t +et, Xt = c + d t +xt, где et, xt — независимые, одинаково распределенные ошибки. Регрессия Yt по константе и Xt может иметь высокий коэффициент детерминации и этот эффект только усиливается с ростом размера выборки. К счастью, с “детерминированным” вариантом ложной регрессии достаточно легко бороться. В рассматриваемом случае достаточно добавить в уравнение тренд в качестве регрессора, и эффект ложной регрессии исчезает.
21. Предположение о нормальном распределении случайной ошибки в рамках классической линейной регрессии и его следствия
Предложение об ошибках в классической модели формируются наиболее жестким и не всегда реалистичным путем:
Предполагается, что ошибка ( (e = 1 … N)) образует так называемый слабый белый шум – последовательность центрированных () и не коррелированных случайных величин с одинаковыми дисперсиями
Свойство центрированности практически не является ограничением, так как при наличии постоянного регрессора среднее значение ошибки можно было бы включить в соответствующий коэффициент ()
В ряде случаев сделанные предложения об ошибках будут дополняться свойствами нормальности – случайный вектор e имеет нормальное распределение. Эту модель мы будем называть классической моделью с нормально распределительными ошибками.
Многомерное нормальное распределение задается своим вектором и матрицей ковариации – здесь она имеет вид , где 1 – единичная матрица. Если компоненты вектора корелированы, следовательно, автоматически независимы, следовательно, ошибки в модели образуют последовательность независимых одинаково нормально распределенных случайных величин N (0;).
Если каждая из величин нормально распределена, то вектор e, из них составленный, ну обязан быть нормально распределенным.
Доверительные интервалы оценок параметров и проверка гипотез об их значимости.
Доверительные интервалы параметров регрессии определяются следующим образом.
Здесь td - значение t-статистики для выбранного уровня значимости d. Величина p=1-d называется доверительной вероятностью или уровнем надежности, нередко выражаемым в процентах. Это показатель, характеризует вероятность того, что теоретическое значение параметра регрессии будет находиться в полученном доверительном интервале.
Тестирование на нормальность остатков. Тесты χ2 Пирсона и Харке–Бера.
Классическая модель линейной регрессии.
Доверительные интервалы оценок параметров и проверка гипотез об их значимости.
Прогнозирование по регрессионной модели и его точность. Доверительные и интервалы прогноза.
Проверка значимости коэффициентов и адекватности регрессии для множественной линейной регрессионной модели. Критерий Стьюдента.
После того как уравнение линейной регрессии найдено, проводится оценка значимости как уравнения в целом, так и отдельных ее параметров.
Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза, что коэффициент регрессии равен нулю, т.е. b=0, и, следовательно, фактор x не оказывает влияния на результат y.
22. Авторегрессионные модели со скользящими средними в остатках
Модель авторегрессии — скользящего среднего (АРСС, autoregressive moving-average model, ARMA) — одна из математических моделей, использующихся для анализа и прогнозирования стационарных временных рядов в статистике. Модель ARMA обобщает две более простые модели временных рядов — модель авторегрессии (AR) и модель скользящего среднего (MA).
Моделью ARMA(p, q), где p и q — целые числа, задающие порядок модели, называется следующий процесс генерации временного ряда:
xk=c+εk+∑i=1paixk−i+∑i=1qbiεk−i,
где ai и bi — параметры модели (действительные числа, соответственно, авторегрессионные коэффициенты и коэффициенты скользящего среднего); c — константа; εk — белый шум.
Такая модель может интерпретироваться как линейная модель множественной регрессии, в которой в качестве объясняющих переменных выступают прошлые значения самой зависимой переменной, а в качестве регрессионного остатка — скользящие средние из элементов белого шума.
ARIMA (autoregressive integrated moving average; модель Бокса — Дженкинса; модель авторегрессии и проинтегрированного скользящего среднего, АРПСС) — модель и методология анализа временных рядов. Является расширением моделей ARMA для нестационарных временных рядов, которые можно сделать стационарными взятием разностей некоторого порядка от исходного временного ряда (так называемые интегрированные или разностно-стационарные временные ряды). Модель ARIMA(p, d, q) означает, что разности временного ряда порядка d подчиняются модели ARMA(p, q).
23. моделирование стационарных временных рядов
После удаления тенденции (тренда) из временного ряда мы получим стационарный временной ряд. Его можно рассматривать как выборку Т последовательных наблюдений через равные промежутки времени из существенно более продолжительной (генеральной последовательности случайных величин. При этом статистические выводы делаются относительно вероятностной структуры генеральной последовательности. Такую последовательность удобно считать простирающейся неограниченно в будущее и, возможно, в прошлое. Последовательность случайных величин у1, у2, . . . или . . ., у-1, у0, у1, . . . называется случайным процессом с дискретным параметром времени.
Несмотря на полную произвольность вероятностных моделей последовательностей случайных величин, полезно отличать случайные процессы от множества случайных величин этого процесса, учитывая понятие времени. Грубо говоря, в случайном процессе наблюдения, разделённые небольшими промежутками времени, близки по значениям в отличие от наблюдений, далеко отстоящих друг от друга во времени. Более того, модель значительно упрощается после расширения конечной последовательности наблюдений до бесконечной.
Одним из таких упрощений является свойство стационарности. Будем считать, что поведение множества случайных величин с вероятностной точки зрения не зависит от времени.
Случайный процесс y(t) с непрерывным параметром времени можно определить для 0 ≤ t < ∞ или -∞ < t < ∞ и рассматривать с привлечением вероятностной меры на пространстве функций y(t). Выборка из такого процесса состоит из наблюдений в конечном числе точек времени , или из непрерывных наблюдений в интервале времени.
Наблюдение процесса, часто называемое реализацией, есть точка в соответствующем бесконечномерном пространстве, где определена вероятностная мера. Вероятность определяется на некоторых множествах, называемых измеримыми. Этот класс множеств включает вместе с любым множеством его дополнение, а также объединение и пересечение счётного числа множеств этого класса; вероятностная мера на этом классе множеств определяется таким образом, что вероятность объединения непересекающихся множеств равна сумме вероятностей отдельных множеств.
Практически мы интересуемся вероятностями, которые связаны с конечным числом случайных величин. Эти вероятности включают в себя функцию совместного распределения.
24. Классическая модель линейной регрессии

25. Авторегрессионные модели


Модель авторегрессии — скользящего среднего (англ. autoregressive moving-average model, ARMA) — одна из математических моделей, использующихся для анализа и прогнозирования стационарных временных рядов в статистике. Модель ARMA обобщает две более простые модели временных рядов — модель авторегрессии (AR) и модель скользящего среднего (MA).
Известно несколько видов авторегрессионных моделей:
- собственно модели авторегрессии (AR - auto regressive);
- модели скользящего среднего (MA - moving average);
- авторегрессии - скользящего среднего (ARMA – autoregressive moving average);
- модели авторегрессии - проинтегрированного скользящего среднего (ARIMA - autoregressive integrated moving average);
- модели авторегрессии с условной гетероскедастичностью (ARCH - autoregressive conditional heteroscedasticity);
- расширения указанных выше авторегрессионных моделей: обобщенная авторегрессионная условно гетероскедастическая модель (GARCH – generalized autoregressive conditional heteroscedasticity model), интегрированная обобщенная авторегрессионная условно гетероскедастическая модель (IGARCH - integrated generalized autoregressive conditional heteroscedasticity model) и др.
26.Понятие об одновременных уравнениях
Систему взаимосвязанных тождеств и регрессионных уравнений, в которой переменные могут одновременно выступать как результирующие в одних уравнениях и как объясняющие в других, принято называть системой одновременных (эконометрических) уравнений. При этом в соотношения могут входить переменные, относящиеся не только к моменту t, но и к предшествующим моментам. Такие переменные называются лаговыми (запаздывающими). Тождества отражают функциональную связь переменных. Техника оценивания параметров системы эконометрических уравнений имеет свои особенности. Это связано с тем, что в регрессионных уравнениях системы независимые переменные и случайные ошибки оказываются коррелированы между собой. Достаточно хорошо изучены статистические свойства и вопросы оценивания систем линейных уравнений. Будем рассматривать линейную модель следующего вида:
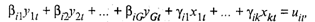
где i = 1, 2, ..., G; t = 1, 2, ..., n;
yit — значение эндогенной (результирующей) переменной в момент t;
xit — значение предопределенной переменной, т.е. экзогенной (объясняющей) переменной в момент t или лаговой эндогенной переменной;
uit —случайные возмущения, имеющие нулевые средние.
Совокупность равенства (53.60) называется системой одновременных уравнений в структурной форме. Наличие априорных ограничений, связанных, например, с тем, что часть коэффициентов считаются равными нулю, обеспечивает возможность статистического оценивания оставшихся. В матричном виде систему уравнений можно представить как
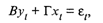
где В — матрица порядка G х G, состоящая из коэффициентов при текущих значениях эндогенных переменных;
Г — матрица порядка G х К, состоящая из коэффициентов экзогенных переменных.
27. Модели скользящего среднего в остатках
Модель скользящего среднего (Moving-average model) q-го порядка MA(q) — это модель временного ряда следующего вида:
xk=μ+εk+∑i=1qbiεk−i,
где bi — параметры модели (без ограничения общности параметр b0 можно считать равным 1); μ — константа; εk — белый шум.
Процесс белого шума формально можно считать процессом скользящего среднего нулевого порядка MA(0) при нулевом значении константы μ.
Процесс скользящего среднего первого порядка MA(1):
xk=μ+εk+bεk−1.

28. Проверка значимости коэффициентов регрессии для множественной линейной регрессии.
При проверке качества модели в первую очередь стоит обращать внимание на то, соответствует ли она логике экономического процесса, т.е. мы должны смотреть, реалистичны ли знаки коэффициентов перед независимыми переменными и реалистична ли их величина.
Традиционно качество регрессии оценивается с помощью: ,
t-статистики
t-статистика соизмеряет значение коэффициента с его стандартной ошибкой. Фактически же мы проверяем гипотезу о том, равен нулю коэффициент при рассматриваемой переменной или нет. Т.е:
Ho: коэффициент=0. Если эта гипотеза верна, то коэффициент не значим.
Ha: коэффициент не равен 0. Если эта гипотеза верна, то коэффициент значим.
F-статистики,
F-статистика представляет собой отношение объясненной суммы квадратов (в расчете на одну независимую переменную) к остаточной сумме квадратов (в расчете на одну степень свободы).
Фактически проверяем гипотезу:
Но: все коэффициенты при независимых переменных равны нулю ( )
На: хотя бы один из них нулю не равен.
R2 (коэффициент детерминации). Коэффициент детерминации показывает объясняющую способность регрессии.
Значимость уравнения множественной регрессии в целом, так же как и в парной регрессии, оценивается с помощью F-критерия Фишера:
 , где Dфакт - факторная сумма квадратов на одну степень свободы;
, где Dфакт - факторная сумма квадратов на одну степень свободы;
Dост - остаточная сумма квадратов на одну степень свободы;
R2 - коэффициент (индекс) множественной детерминации;
m – число параметров при переменных х
n – число наблюдений.
Частный F-критерий построен на сравнении прироста факторной дисперсии, обусловленного влиянием дополнительно включенного фактора, с остаточной дисперсией на одну степень свободы по регрессионной модели в целом. Предположим, что оцениваем значимость влияния х1 как дополнительно включенного в модель фактора. Используем следующую формулу:
 , где
, где 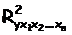 - коэффициент множественной детерминации для модели с полным набором факторов;
- коэффициент множественной детерминации для модели с полным набором факторов;
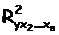 - тот же показатель, но без включения в модель фактора х1;
- тот же показатель, но без включения в модель фактора х1;
n – число наблюдений
m – число параметров в модели (без свободного члена).
Если оцениваем значимость влияния фактора хn после включения в модель факторов x1,x2, …,xn-1, то формула частного F-критерия определится как
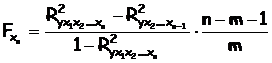
В общем виде для фактора xi частный F-критерий Фишера определится как
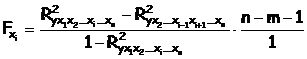
Фактическое значение F-критерия Фишера сравнивается с табличным при 5%-ном или 1%-ном уровне значимости и числе степеней свободы: m и n-m-1. Если Fфакт>Fтабл(a,n,n-m-1), то дополнительное включение фактора xi в модель статистически оправданно и коэффициент чистой регрессии bi при факторе xi статистически значим. Если же Fфакт<Fтабл(a,n,n-m-1), то дополнительное включение фактора xi в модель существенно не увеличивает долю объясненной вариации признака y, следовательно, нецелесообразно его включение в модель; коэффициент регрессии при данном факторе в этом случае статистически незначим.
С помощью частного F-критерия Фишера можно проверить значимость всех коэффициентов регрессии в предположении, что каждый соответствующий фактор xi вводился в уравнение множественной регрессии последним.
Если уравнение содержит больше двух факторов, то соответствующая программа ПК дает таблицу дисперсионного анализа, показывая значимость последовательного добавления к уравнению регрессии соответствующего фактора. Так, если рассматривается уравнение
y=a+b1x1+b2x2+ b3x3+ε,
то определяются последовательно F-критерий для уравнения с одним фактором х1, далее F-критерий для дополнительного включения в модель фактора х2, т.е. для перехода от однофакторного уравнения регрессии к двухфакторному, и, наконец, F-критерий для дополнительного включения в модель фактора х3 после включения в модель фактора х1 и х2. В этом случае F-критерий для дополнительного включения фактора х1 после х2 является последовательным в отличие от F-критерия для дополнительного включения в модель фактора х3, который является частным F-критерием, ибо оценивает значимость фактора в предположении, что он включен в модель последним.
29. Модель arima
ARIMA (autoregressive integrated moving average; модель Бокса — Дженкинса; модель авторегрессии и проинтегрированного скользящего среднего, АРПСС) — модель и методология анализа временных рядо
|
из
5.00
|
Обсуждение в статье: Диагностирование автокорреляции |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы