 |
Главная |


Метод группового учета аргументов
|
из
5.00
|
Метод группового учета аргументов (МГУА).использует идеи самоорганизации и механизмы живой природы – скрещивание (гибридизацию) и селекцию (отбор).
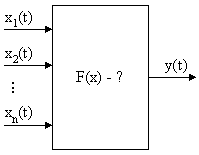
Рисунок 4.3
По результатам наблюдений надо определить F(x). Причем даже структура модели F(x) неизвестна.
Пусть имеется выборка из N наблюдений:
 .
.
Наиболее полная зависимость между входами X(i) и выходами Y(i) может быть представлена с помощью обобщенного полинома Колмогорова-Габора.
Пусть есть  , тогда такой полином имеет вид:
, тогда такой полином имеет вид:
 (4.8)
(4.8)
где все коэффициенты а не известны.
При построении модели (при определении значений коэффициентов) в качестве критерия используется критерий регулярности (точности):
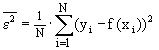 (4.9)
(4.9)
Необходимо, чтобы  .
.
Принцип множественности моделей: существует множество моделей на данной выборке, обеспечивающих нулевую ошибку (достаточно повышать степень полинома модели). Т.е. если имеется N узлов интерполяции, то можно построить целое семейство моделей, каждая из которых при прохождении через экспериментальные точки будет давать нулевую ошибку:
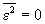 (4.10)
(4.10)
Обычно степень нелинейности берут не выше n-1, если n – количество точек выборки.
Обозначим S – сложность модели (определяется числом членов полинома Колмогорова-Габора).
Значение ошибки 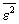 зависит от сложности модели. Причем по мере роста сложности сначала она будет падать, а затем расти. Нам же нужно выбрать такую оптимальную сложность, при которой ошибка будет минимальна. Кроме того, если учитывать действие помех, то можно выделить следующие моменты:
зависит от сложности модели. Причем по мере роста сложности сначала она будет падать, а затем расти. Нам же нужно выбрать такую оптимальную сложность, при которой ошибка будет минимальна. Кроме того, если учитывать действие помех, то можно выделить следующие моменты:
При различном уровне помех зависимость от сложности S будет изменяться, сохраняя при этом общую направленность (имеется ввиду, что с ростом сложности она сначала будет уменьшаться, а затем – возрастать).
При увеличении уровня помех величина 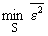 будет расти.
будет расти.
С ростом уровня помех,  будет уменьшаться (оптимальное значение сложности будет смещаться влево) см. рис 4.2 Причем
будет уменьшаться (оптимальное значение сложности будет смещаться влево) см. рис 4.2 Причем 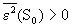 , если уровень помех ненулевой.
, если уровень помех ненулевой.
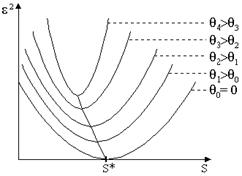
Рисунок 4.4
Теорема неполноты Гёделя: В любой формальной логической системе имеется ряд утверждений и теорем, которые нельзя ни опровергнуть, ни доказать, оставаясь в рамках этой системы аксиом.
В данном случае эта теорема означает, что выборка всегда неполна.
Один из способов преодоления этой неполноты – принцип внешнего дополнения. В качестве внешнего дополнения используется дополнительная выборка (проверочная), точки которой не использовались при обучении системы (т.е. при поиске оценочных значений коэффициентов полинома Колмогорова-Габора).
Поиск наилучшей модели осуществляется таким образом:
1) вся выборка делится на обучающую и проверочную: 
2) на обучающей выборке  определяются значения
определяются значения 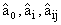 . На проверочной выборке
. На проверочной выборке  отбираются лучшие модели.
отбираются лучшие модели.
3) входной вектор имеет размерность N 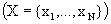 .
.
Принцип свободы выбора (неокончательности промежуточного решения):
Для каждой пары 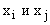 строятся частичные описания (всего
строятся частичные описания (всего  ) или линейного (4.11) или квадратичного (4.12) вида:
) или линейного (4.11) или квадратичного (4.12) вида:
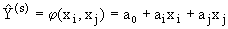 ,
, 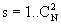 , (4.11)
, (4.11)
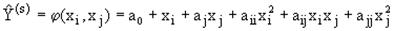 , . (4.12)
, . (4.12)
Определяем коэффициенты этих моделей по МНК, используя обучающую выборку. Т.е. находим  .
.
Далее на проверочной выборке для каждой из этих моделей ищем оценку по формуле (4.13) и определяем F лучших моделей.
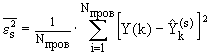 , (4.13)
, (4.13)
где  – действительное значение выходное значение в k-той точке проверочной выборки;
– действительное значение выходное значение в k-той точке проверочной выборки;
а 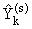 – выходное значение в k-той точке проверочной выборки в соответствии с s-той моделью.
– выходное значение в k-той точке проверочной выборки в соответствии с s-той моделью.

Рисунок 4.5
Выбранные  подаются на второй ряд, где по формуле (4.14) ищем
подаются на второй ряд, где по формуле (4.14) ищем 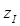 .
.
 (4.14)
(4.14)
Оценка здесь такая же, как на первом ряде. Отбор лучших осуществляется опять так же, но  .
.
Процесс конструирования рядов повторяется до тех, пока средний квадрат ошибки будет падать. Когда на слое m получим увеличение ошибки , то прекращаем.
Если частичные описания квадратичные и число рядов полинома S, то получаем, что степень полинома k=2S.
В отличие от обычных методов статистического анализа, при таком подходе можно получить достаточно сложную зависимость, даже имея короткую выборку.
Есть проблема: на первом ряде могут отсеяться некоторые переменные , которые оказывают влияние на выходные данные.
В связи с этим предложена такая модификация: на втором слое подавать  и
и 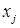 , т.е.:
, т.е.: 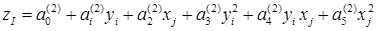 .
.
Это важно при большем уровне помех, чтобы обеспечить несмещенность.
Возникает два способа отбора лучших кандидатов частичных описаний передаваемых на определенном слое.
Критерий регулярности (точности) 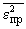 :
:
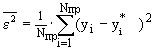 , (4.15)
, (4.15)
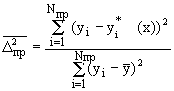 (4.16)
(4.16)
Критерий несмещенности. Берем всю выборку, делим на две части R= 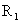 +
+ 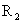
Первый эксперимент: - обучающая выборка, - проверочная; определяем выходы модели 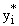 , i=1..R. Второй эксперимент: - обучающая выборка,
, i=1..R. Второй эксперимент: - обучающая выборка,  - проверочная; определяем выходы модели
- проверочная; определяем выходы модели 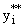 , i=1..R и сравниваем. Критерий несмещенности:
, i=1..R и сравниваем. Критерий несмещенности:
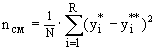 (4.17)
(4.17)
Чем меньше  , тем более несмещенной является модель.
, тем более несмещенной является модель.
Такой критерий определяется для каждого частичного описания первого уровня и затем находится для уровня в целом
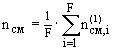 (4.18)
(4.18)
для F лучших моделей. В ряде вариантов F=1. Такое же самое на втором слое 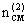 .
.
И процесс селекции осуществляется до тех пор, пока этот критерий не перестанет уменьшаться, т.е. до достижения условия
 . (4.19)
. (4.19)
|
из
5.00
|
Обсуждение в статье: Метод группового учета аргументов |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы