 |
Главная |


Модуль 3. Задачи математической статистики. Статистические оценки параметров распределения
|
из
5.00
|
Пример 10. При изучении производительности труда X тыс. руб. на одного работника было обследовано 10 предприятий и получены следующие значения:
4,2; 4,8; 4,7; 5,0; 4,9; 4,3; 3,9; 4,1; 4,3; 4,8.
Определить выборочное среднее  , выборочную дисперсию, исправленное среднее квадратическое отклонение.
, выборочную дисперсию, исправленное среднее квадратическое отклонение.
Решение. Находим выборочную среднюю при n=10:
 (тыс.руб)
(тыс.руб)
Найдем выборочную дисперсию. Для этого вычислим  и
и  .
.

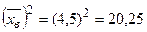 ,
,  .
.
Исправленное среднее квадратическое отклонение:
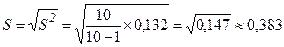 .
.
Смысл полученных результатов заключается в следующем. Величина характеризует среднее значение признака X в пределах рассматриваемой выборки. Средняя производительность труда для изученных предприятий составила =4,5 тыс. руб. на одного работника. Исправленное среднее квадратическое отклонение S описывает абсолютный разброс значений показателя X и в данном случае составляет S=0,383 тыс. руб.
Пример 11. В ходе обследования банковских счетов была проведена случайная выборка записей по вкладам. Из выборки n=100 оказалось, что средний размер вклада составляет 1 837 у.е.; среднее квадратическое отклонение размера вклада равно 280 у.е. Найти с надежностью g=0,95 доверительный интервал для среднего размера а вкладов по всем счетам, если известно, что размер вкладов распределен по нормальному закону.
Решение. По условию =1837; n=100; s=280; g=0,95. По таблице значений функции  находим t из условия Ф(t)=
находим t из условия Ф(t)=  , получаем t=1,96. По формуле (7) находим доверительный интервал:
, получаем t=1,96. По формуле (7) находим доверительный интервал:
 ,
,  ,
,
 .
.
Это означает, что с вероятностью, равной 0,95, можно утверждать, что средний размер вклада генеральной совокупности находится в пределах от 1 782,12 у.е. до 1 891,88 у.е. Интервал ±54,88 составляет примерно ±3% среднего размера вклада в выборке (1 837). Это не очень большое отклонение, поэтому среднее значение выборки можно считать надежной оценкой среднего значения генеральной совокупности. Однако существует вероятность, равная 0,05 того, что можно получить значение вне доверительного интервала.
Пример 12. Выборочно обследовано 100 снабженческо-сбытовых предприятий некоторого региона по количеству работников X и объемам складской реализации Y (у.е.). Результаты представлены в корреляционной таблице (табл.1).
Таблица 1
| X У | ny | |||||
| nх | n=100 |
По данным исследования требуется:
1) в прямоугольной системе координат построить эмпирические ломаные регрессии Y на X и X на Y, сделать предположение в виде корреляционной связи;
2) оценить тесноту линейной корреляционной связи;
3) составить линейные уравнения регрессии Y на X и X на Y, построить их графики в одной системе координат;
4) используя полученные уравнения регрессии, оценить ожидаемое среднее значение признака Y при х=40 чел. Дать экономическую интерпретацию полученных результатов.
Решение.
1. Для построения эмпирических ломаных регрессии вычислим условные средние 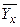 и
и  Вычисляем
Вычисляем  . Так как при х=5 признак Y имеет распределение
. Так как при х=5 признак Y имеет распределение
| Y | |||
| ni |
то условное среднее 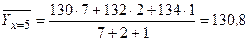 .
.
При х=15 признак Y имеет распределение
| Y | ||||
| ni |
тогда 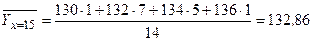 .
.
Аналогично вычисляются все  и
и  .Получим таблицы, выражающие корреляционную зависимость Y от X, (табл.2) и X от Y (табл.3).
.Получим таблицы, выражающие корреляционную зависимость Y от X, (табл.2) и X от Y (табл.3).
Таблица 2

| |||||

| 130,8 | 132,86 | 135,74 | 137,08 | 137,86 |
Таблица 3

| ||||||

| 6,25 | 19,54 | 32,35 | 43,57 |
В прямоугольной системе координат построим точки Аi(хi,  ), соединим их отрезками прямых, получим эмпирическую линию регрессии Y на X (точечная линия). Аналогично строятся точки В i(
), соединим их отрезками прямых, получим эмпирическую линию регрессии Y на X (точечная линия). Аналогично строятся точки В i(  ,yi) и эмпирическая линия регрессии X на Y (сплошная линия) (рис. 1).
,yi) и эмпирическая линия регрессии X на Y (сплошная линия) (рис. 1).

| |
| |



| |
 | |||
| | |||


| |
| | |||
| |
| |
 | |||
| |
| |
| |
 | |||
| |

| |
| |
| |

 |
5 10 15 20 25 30 35 40 45 Х( ) Рис.1
Построенные эмпирические ломаные регрессии Y на X и X на Y свидетельствуют о том, что между количеством работающих (X) и объемом складских реализаций (Y) существует линейная зависимость. Из графика видно, что с увеличением X, также увеличивается, поэтому можно выдвинуть гипотезу о прямой линейной корреляционной зависимости между количеством работающих и объемом складских реализаций.
2. Оценим тесноту связи. Вычислим выборочный коэффициент корреляции.
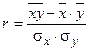 ,
,  ,
,  ,
,
 ,
, 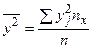 ,
,  ;
;
 ,
,  ;
;
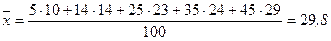 ;
;
 ;
;
 ;
;


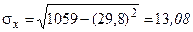 ;
; 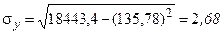 ;
;
 .
.
Полученное значение rB говорит о том, что линейная связь между количеством работников и объемом складских реализаций высокая. Этот вывод подтверждает первоначальное предположение, сделанное исходя из графика.
3. Запишем уравнения регрессии:
 ,
,  .
.
Подставляя в эти уравнения найденные величины, получаем искомые уравнения регрессии:
1) уравнение регрессии Y на X:
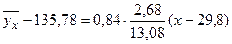 , или
, или  ;
;
2) уравнение регрессии X на Y:
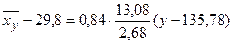 , или
, или  .
.
Построим графики найденных уравнений регрессии.
Зададим координаты двух точек, удовлетворяющих уравнению
 (точечная линия).
(точечная линия).
Пусть х = 10, тогда  .
.
А1(10; 132,41),
Если х = 40, тогда 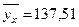 .
.
А2(40; 137,51)
Аналогично находим точки, удовлетворяющие уравнению  (сплошная линия).
(сплошная линия).
В1(10,2; 131), В2(43; 139)
|

|
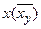
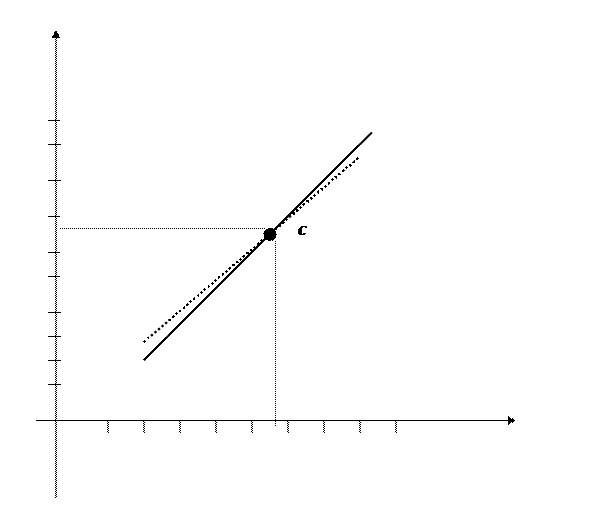
Контроль: точка пересечения прямых линий регрессии имеет координаты  . В нашем примере: С(29,8; 135,78).
. В нашем примере: С(29,8; 135,78).
4. Найдем среднее значение Y при х=40 чел., используя уравнение регрессии Y на X. Подставим в это уравнение х=40, получим  .
.
Ожидаемое среднее значение объема складских реализаций при заданном количестве работников (х=40) составляет 137,51 у.е.
Замечание1. Если в корреляционной таблице даны интервальные распределения, то за значения вариант надо брать середины частичных интервалов.
Замечание2. Если данные наблюдений над признаками X и Y заданы в виде корреляционной таблицы с равноотстоящими вариантами, то целесообразно перейти к условным вариантам:
 ,
, 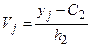 ,
,
где h1 - шаг, т.е. разность между двумя соседними вариантами xi;
С1 - «ложный нуль» вариант xi (в качестве «ложного нуля» удобно принять варианту, которая расположена примерно в середине ряда);
h2 - шаг вариант Y;
С2 - «ложный нуль» вариант Y.
В этом случае выборочный коэффициент корреляции
 , где
, где  ,
,  ,
,
 ,
,  .
.
Зная эти величины, определим
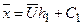 ,
,  ,
,  ,
,  .
.
Так в данном примере С1 =25, h1=10, С2=136, h2=2;  ,
,  .
.
| U V | -2 | -1 | ny | |||
| -3 | ||||||
| -2 | ||||||
| -1 | ||||||
| nx | n=100 |

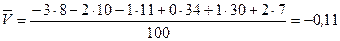 ;
;
 ;
;
 ;
;

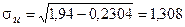 ;
;  ;
;
 ;
;
 ;
;
 ;
;
 ;
;  ;
;
;  .
.
|
из
5.00
|
Обсуждение в статье: Модуль 3. Задачи математической статистики. Статистические оценки параметров распределения |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы