 |
Главная |


Непараметрический подход к анализу данных в теории надежности
|
из
5.00
|
При решении многочисленных прикладных задач анализа надежности химического и нефтеперерабатывающего оборудования большинство исследователей использует статистические методы обработки данных, основанные на предположении, что количественные характеристики надежности имеют закон распределения, принадлежащий к тому или иному параметрическому семейству – Вейбулла, гауссовскому, показательному и т.д. Другая группа методов – непараметрических, базирующихся на более фундаментальных свойствах случайных величин и потому свободных от предпосылок о распределении наблюдений, остается на сегодняшний день, к сожалению, практически не востребованной в переработке отходов. Однако переход к созданию КПТ показывает преимущества непараметрических статистических методов в сравнении с традиционными:
1. Меньшее количество неоправданных математических допущений. Истинные законы распределения характеристик надежности для большинства единиц оборудования на практике, как правило, не известны. Предположение же о принадлежности эмпирической плотности распределения определенному параметрическому семейству очень часто выполняется лишь приближенно. Более того, подобное предположение требует специального теоретического обоснования. Иными словами, нежелательно уже, например, в процессе анализа «подогнать» по выборке некоторый закон распределения, а потом пытаться проверить согласие с полученным законом по той же выборке. Кроме того, исследователям на практике приходится иметь дело и с малыми выборками, для которых практически невозможна эффективная проверка гипотез об их распределении. В связи с этим следует подчеркнуть, что использование параметрических методов для оценки показателей надежности может привести к результатам, не имеющим даже приблизительно правильного характера. Применение непараметрических методов значительно уменьшает подобную опасность. [11]
2. Устойчивость к выбросам и другим резким отклонениям от основной массы наблюдений. При анализе статистических рядов показателей надежности исследователи очень часто сталкиваются с выбросами. Особенно это касается интервалов времени восстановления. Однако, даже одно или несколько грубых наблюдений способны сильно исказить такие выборочные характеристики как: среднее, дисперсия, стандартное отклонение, коэффициенты асимметрии и эксцесса, а также привести к многим другим ошибочным выводам при использовании именно параметрических моделей. Это связано с тем, что большинство традиционных статистических методов, например метод наименьших квадратов, весьма чувствительны к отклонениям от условий их применимости. В таких случаях на практике проводят цензурирование данных, т.е. отбраковку грубых наблюдений, однако подобная процедура, по сути, бесполезна и малоэффективна. Кроме того, это может привести к искажению реальной ситуации, поскольку и количество и величина подобных выбросов случайные величины. Непараметрические методы статистики, гарантируют получение устойчивых (робастных) оценок.
Робастная оценка (robust estimator) – статистическая оценка, нечувствительная к малым изменениям исходной статистической модели. Термин «робастный» введен Дж. Боксом в 1953 году для обозначения методов, устойчивых к малым отклонениям от заданных предположений. Термин получил широкое распространение, и понятие робастная оценка является частным его применением. Основы математической теории робастного оценивания заложены П. Хьюбером.[11]
В свою очередь к недостаткам непараметрических моделей в сравнении с традиционными можно отнести следующие:
1. Меньшая информативность. Поскольку при применении непараметрических методов никаких предположений относительно распределения случайных переменных не дается, исследователи могут использовать только ту информацию об исходных данных, которая не зависит от конкретного вида параметрического закона. В то же в теории надежности часто при решении конкретных задач, например, для описания природы отказов, сроков службы элементов оборудования, при изучении ремонтопригодности и т.д. используются конкретные распределения. В этих условиях проведения анализа только лишь эмпирических плотностей вероятности в ряде случаев может оказаться явно недостаточно.
2. Более низкая точность оценок и выводов. Большинство исследователей в области статистики придерживается подобной точки зрения. В принципе с этим утверждением можно согласиться, однако следует подчеркнуть, что непараметрические методы лишь немного уступают в эффективности наилучшим параметрическим, когда последние можно использовать.
3. Значительная вычислительная сложность. Именно из-за этого, по всей видимости, непараметрические методы до сих пор не получили должного применения на практике, хотя интенсивно развиваются на протяжении нескольких последних десятилетий. Однако широкое распространение современной компьютерной техники, разработка многочисленных программ, предусматривающих обработку больших массивов информации, по сути, нивелируют данный недостаток.
Одним из ключевых понятий в непараметрической статистике является ранг.
Рангом наблюдения называется тот номер, который получит это наблюдение в упорядоченной совокупности всех данных – после упорядочения по определенному правилу. Чаще всего упорядочение чисел производят по величине – от меньших к большим.[11]
Процедура перехода от совокупности наблюдений к последовательности их рангов называется ранжированием. Результат ранжирования называют ранжировкой. [11 ]
Однофакторный анализ
Непараметрические критерии проверки однородности
В зависимости от числа групп исходных данных непараметрические методы однофакторного анализа подразделяются на двухвыборочные и многовыборочные.
Наиболее известными статистиками, применяемыми для проверки отсутствия статистически значимых различий между двумя независимыми выборками  и
и 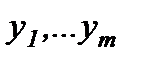 , являются:
, являются:
- Критерий Уилкоксона. Основан на оценке
 , (23)
, (23)
где rj – ранги случайных величин yj в общем вариационном ряду xi и yj, а функция s(r), r = 1, …, n+m, определяется заранее фиксированной подстановкой  , здесь s(1), …, s(n+m) – одна из возможных перестановок чисел 1, 2, …, n+m. При больших m и n пользуются нормальным приближением для распределения W.
, здесь s(1), …, s(n+m) – одна из возможных перестановок чисел 1, 2, …, n+m. При больших m и n пользуются нормальным приближением для распределения W.
- Критерий Манна-Уитни. Построен на оценке:
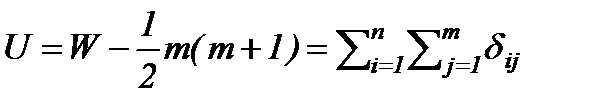 , (24)
, (24)
где W – критерий Уилкоксона, а 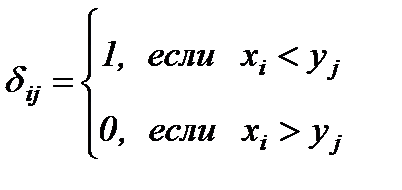 . Для больших выборок применяют нормальную аппроксимацию распределения U.
. Для больших выборок применяют нормальную аппроксимацию распределения U.
- Критерий Ансари-Брэдли. Алгоритм назначения рангов: выборки объединяются; ранг 1 получают два наблюдения – наименьшее и наибольшее; ранг 2 – наименьшее и наибольшее из оставшихся и т.д. Статистика Ансари-Брэдли – сумма рангов одной из выборок.
- Критерий Сиджела-Тьюки. Алгоритм назначения рангов: все наблюдения объединяются в одну совокупность; ранг 1 получает наименьшее из чисел этой совокупности; ранг 2 – наибольшее из оставшихся; ранг 3 – снова наибольшее из оставшихся; ранг 4 – наименьшее из оставшихся и т.д. Последовательность рангов наблюдений, выстроенных в порядке возрастания будет выглядеть так: 1, 4, 5, …, 3, 2. Статистика Сиджела-Тьюки – сумма рангов одной из выборок, распределенная при H0 как статистика Уилкоксона;
- Критерий Ван дер Вардена. Алгоритм назначения рангов: выборки объединяются в и упорядочиваются по величине; рангом наблюдения служит его номер в этом упорядочении (при наличии совпадающих наблюдений используют средние ранги). Пусть r1, …, rn – ранги одной из выборок (m, n – объемы выборок). Статистика Ван дер Вардена равна:
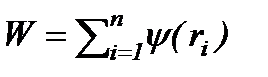 , (25)
, (25)
где  – функция квантилей стандартного нормального распределения. При решении многовыборочных задач получили широкое использование следующие статистики:
– функция квантилей стандартного нормального распределения. При решении многовыборочных задач получили широкое использование следующие статистики:
- Критерий Краскела-Уоллиса. Основан на сравнении средних выборочных рангов и среднего ранга, рассчитанного по всей совокупности данных. Применим при любом числе выборок, не обязательно равных по объему. При k=2 статистика Краскела-Уоллиса по своему действию эквивалентна статистике Уилкоксона.
- Критерий Джонкхиера. Построен на оценке:
 , (26)
, (26)
здесь Uu,v – статистика Манна-Уитни для пары выборок с номерами u и v. При малом объеме выборок распределение J табулировано. Для больших рядов в отношении статистики Джонкхиера действует нормальная аппроксимация. [11 ]
|
из
5.00
|
Обсуждение в статье: Непараметрический подход к анализу данных в теории надежности |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы