 |
Главная |


Рекомендации G.723.1 и G.729
|
из
5.00
|
Рекомендация G.723.1 определяет кодовое представление, которое может использоваться на очень низких скоростях для компрессии речевых или других аудиосигналов в средствах мультимедиа. В кодере, реализующем рекомендации G.723.1, принципиальным приложением является низкоскоростная видеотелефония как часть общего семейства стандартов Н.324.
Кодер обеспечивает работу на двух скоростях — 5,3 и 6,3 кбит/с. Более высокая скорость обеспечивает лучшее качество. Тем не менее, и более низкая скорость обеспечивает хорошее качество и предоставляет разработчикам систем связи дополнительные возможности. И кодер и декодер должны обязательно поддерживать обе скорости. Существует возможность переключения скоростей. Возможно также изменение рабочей скорости с использованием прерывистой передачи и заполнение шумом пауз.
Кодер G.723.1 оптимизирован для сжатия речи с высоким качеством на установленной скорости при ограниченной полосе. Музыка и другие аудиосигналы также могут быть подвергнуты компрессии с использованием этого кодера, однако, не с таким же высоким качеством, как речь.
Кодер G .723.1 преобразует речь или другие аудиосигналы во фреймы длительностью 30 мс. Кроме того, существует возможность просмотра фреймов на скорости 7,5 мс, что приводит к общей алгоритмической задержке 37,5 мс. Дополнительные задержки возникают из-за:
времени, затрачиваемого на обработку данных в кодере и декодере;
времени передачи по линии связи;
дополнительной буферной задержки протокола мультиплексирования.
Кодер G.723.1 предназначен для работы с цифровыми сигналами после предварительной фильтрации полосы аналогового телефонного канала (рекомендации G.712), дискретизации с частотой 8 кГц и преобразования в 16-битную линейную ИКМ последовательность для передачи на вход кодера. Выходной сигнал декодера преобразуется обратно в аналоговый сигнал аналогичным образом. Другие характеристики входа/выхода такие же, как и определенные рекомендациями G.711 для 64-битной ИКМ. Перед кодированием данные должны быть преобразованы в 16-битную ИКМ последовательность или в соответствующий формат после декодирования из 16-битной ИКМ.
Кодер, основанный на принципах кодирования методом «анализ через синтез» с линейным предсказанием, минимизирует взвешенный сигнал ошибки, работает с блоками (фреймами) по 240 выборок каждый, что в частоте дискретизации 8 кГц эквивалентно длительности 30 мс. Каждый фрейм проходит через фильтр верхних частот для удаления постоянной составляющей, а затем разделяется на четыре субфрейма по 60 выборок в каждом. Для каждого субфрейма используется фильтр десятого порядка кодера с линейным предсказанием. Для последнего субфрейма коэффициенты LPC-фильтра квантуются с использованием прогнозирующего квантизатора вектора разбиения (PSVQ). Квантованные LPC-коэффициенты используются для создания кратковременного взвешивающего фильтра, который применяется для фильтрации всего фрейма и для получения взвешенной оценки речевого сигнала. На основе этой оценки для каждых двух субфреймов (120 выборок) вычисляется период основного тона 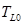 . Оценка тона представляется блоками по 120 выборок. Период основного тона лежит в диапазоне от 18 до 142 выборок.
. Оценка тона представляется блоками по 120 выборок. Период основного тона лежит в диапазоне от 18 до 142 выборок.
С помощью вычисленной заранее оценки периода тона создается фильтр формы гармонического шума. Комбинация из фильтра синтеза LPC, фильтра взвешивания формант, фильтра формы гармонического шума используется для синтеза импульсной характеристики, необходимой для дальнейших вычислений.
Оценки периода основного тона  и импульсного отклика используются при работе предсказателя тона пятого порядка. Период тона вычисляется как приращение относительной оценки периода основного тона. На декодер передаются тоновый период и разностные величины. На следующем этапе аппроксимируются непериодические составляющие возбуждения. Для высокой скорости используется многоимпульсное возбуждение с квантованием и алгоритмом максимального правдоподобия (MP-MLQ), а для низких скоростей – алгебраическое кодовое возбуждение.
и импульсного отклика используются при работе предсказателя тона пятого порядка. Период тона вычисляется как приращение относительной оценки периода основного тона. На декодер передаются тоновый период и разностные величины. На следующем этапе аппроксимируются непериодические составляющие возбуждения. Для высокой скорости используется многоимпульсное возбуждение с квантованием и алгоритмом максимального правдоподобия (MP-MLQ), а для низких скоростей – алгебраическое кодовое возбуждение.
Рекомендации ITU-T G.729 содержат описание алгоритма кодирования речевых сигналов на скорости 8 кбит/с с использованием алгебраического линейного предсказания с кодовым возбуждением с сопряженной структурой (CS-ACELP).
Подобный кодер создан для работы с цифровыми сигналами, полученными после предварительной обработки аналогового входного сигнала фильтром низкой частоты, дискретизации с частотой 8 кГц и дальнейшем преобразованием в линейную ИКМ для подачи на вход кодера. Выходной сигнал декодера конвертируется обратно в аналоговый сигнал подобным же образом. Другие характеристики входа/выхода определяются аналогично рекомендациями G.711 для ИКМ последовательностей со скоростью 64 кбит/с. После декодирования данные должны быть преобразованы из 16-битовой линейной ИКМ в требуемый формат.
Кодер CS-ACELP основан на модели с линейным предсказанием с кодовым возбуждением (CELP) и работает с фреймами речи по 10 мс, соответствующих 80 выборкам. Каждый фрейм речевого сигнала длительностью 10 мс анализируется для выделения параметров CELP-модели (коэффициенты фильтра линейного предсказания, индексы адаптивной и фиксированной кодовых книг и коэффициенты усиления). Эти параметры кодируются и передаются на приемную сторону. Распределение бит параметров кодера показано в табл. 3.1.
Таблица 3.1
Распределение бит для алгоритма CS-ACELP на скорости 8 кбит/с (фреймы по 10 мс)
| Параметр | Кодовое слово | Субфрейм 1 | Субфрейм 2 | В целом на фрейм |
| Пары линейного спектра | LU, L1, L2, L3 | |||
| Задержка адаптивной кодовой книги | P1, Р2 | 8 | 5 | 13 |
| Проверка задержки тона | Р0 | 1 | 1 | |
| Индекс фиксированной кодовой книги | CT, С2 | 13 | 13 | 26 |
| Запись фиксированной кодовой книги | S1, S2 | 4 | 4 | 8 |
| Усиления кодовой книги (этап 1) | GA1, GA2 | 3 | 3 | 6 |
| Усиления кодовой книги (этап 2) | GBl, GB2 | 4 | 4 | 8 |
| Всего | 80 |
На стороне декодера эти параметры используются для восстановления параметров возбуждения и фильтра синтеза. Как показано на рис. 3.3, речь восстанавливается при фильтрации этого возбуждения фильтром кратковременного синтеза, который основан на фильтре линейного предсказания десятого порядка. Долговременный фильтр (или фильтр синтеза тона) выполняется с использованием адаптивной кодовой книги. После синтеза речи происходит дополнительное сглаживание в постфильтре.
Входной сигнал поступает на фильтр высоких частот и масштабируется в блоке предварительной обработки, после чего подвергается последующему анализу. Анализ с линейным предсказанием (LP-анализ) выполняется один раз для фрейма длительностью 10 мс с целью вычисления коэффициентов фильтра линейного предсказания, которые затем преобразуются в пары линейного спектра (Line Spectrum Pairs, LSP) и квантуются (18 бит) с использованием двухэтапного векторного квантования с предсказанием.
Сигнал возбуждения выбирается с использованием поисковой процедуры «анализ через синтез», при которой ошибка между исходной и восстанавливаемой речью минимизируется в соответствии с измерением взвешенных искажений. Это выполняется путем фильтрации сигнала ошибки фильтром взвешивания, коэффициенты которого извлечены из неквантованного LP-фильтра.
Параметры возбуждения (параметры фиксированной и адаптивной кодовых книг) определены для субфрейма длительностью 5 мс (40 выборок). Коэффициенты квантованного и неквантованного фильтра с линейным предсказанием используются для второго субфрейма, в то время как в первом субфрейме используются интерполированные коэффициенты LP-фильтра.
Задержка основного тона оценивается один раз для фрейма длиной 10 мс на основе взвешенного речевого сигнала. Затем для каждого субфрейма повторяются следующие операции. Искомый сигнал  вычисляется при фильтрации остаточного линейного предсказания во взвешивающем фильтре синтеза
вычисляется при фильтрации остаточного линейного предсказания во взвешивающем фильтре синтеза  . При фильтрации ошибки начальные состояния этих фильтров обновляются. Это эквивалентно результату выделения нулевого входного отклика взвешивающего фильтра синтеза из взвешенного речевого сигнала. Вычисляется импульсная характеристика
. При фильтрации ошибки начальные состояния этих фильтров обновляются. Это эквивалентно результату выделения нулевого входного отклика взвешивающего фильтра синтеза из взвешенного речевого сигнала. Вычисляется импульсная характеристика  взвешивающего фильтра синтеза, после чего выполняется анализ тона для нахождения задержки адаптивной кодовой книги путем анализа значения задержки вблизи основного тона с использованием искомого сигнала
взвешивающего фильтра синтеза, после чего выполняется анализ тона для нахождения задержки адаптивной кодовой книги путем анализа значения задержки вблизи основного тона с использованием искомого сигнала  и импульсной характеристики
и импульсной характеристики  . Задержка тона кодируется восемью битами в первом субфрейме и пятью битами во втором субфрейме. Искомый сигнал
. Задержка тона кодируется восемью битами в первом субфрейме и пятью битами во втором субфрейме. Искомый сигнал  используется при поиске фиксированной кодовой книги для нахождения оптимального возбуждения. Семнадцатибитовая алгебраическая кодовая книга используется для возбуждения фиксированной кодовой книги. Коэффициенты усиления вкладов адаптивной и фиксированной кодовых книг — это векторы, квантованные семью битами.
используется при поиске фиксированной кодовой книги для нахождения оптимального возбуждения. Семнадцатибитовая алгебраическая кодовая книга используется для возбуждения фиксированной кодовой книги. Коэффициенты усиления вкладов адаптивной и фиксированной кодовых книг — это векторы, квантованные семью битами.
Индексы параметров кодовых книг выделяются из принятого потока бит и декодируются для получения следующих параметров кодера, соответствующих речевому фрейму длиной 10 мс: LP-коэффициенты (коэффициенты линейного предсказания), две частичные задержки тона, два вектора фиксированной кодовой книги и два набора коэффициентов адаптивной и фиксированной кодовых книг. Коэффициенты LSP интерполируются и преобразуются в коэффициенты LP-фильтра для каждого субфрейма. Для каждого субфрейма выполняются следующие шаги:
восстанавливается возбуждение путем добавления векторов адаптивной и фиксированной кодовых книг с соответствующими им коэффициентами усиления;
восстанавливается речь путем пропускания через фильтр LP-синтеза;
восстанавливаемый речевой сигнал пропускается через ступень постобработки, которая включает адаптивный постфильтр, состоящий из долговременного и кратковременного постфильтров синтеза, фильтр высоких частот и операцию масштабирования.
Кодер кодирует речь и другие аудиосигналы по фреймам длительностью 10 мс. В результате осуществляется задержка 5 мс, что приводит в результате к общей алгоритмической задержке 15 мс. Все дополнительные задержки при практическом исполнении такого кодера обусловлены следующими причинами:
временем обработки, необходимым для операции кодирования и декодирования;
временем передачи по линиям связи;
задержкой мультиплексирования, когда аудиоданные объединяются с другими данными.
Таким образом, рекомендация G.729 предусматривает фреймы возбуждения по 5 мс и формирует четыре импульса. Фрейм из 40 выборок разделяется на четыре части. Первые три имеют восемь возможных позиций для импульсов, четвертая — шестнадцать. Из каждой части выбирается по одному импульсу. В результате образуется четырехимпульсный ACELP возбуждения кодовой страницы (табл. 3.2).
Таблица 3.2
Параметры кодеров
| Параметры кодера | Кодер | ||
| G.729 | G.729A | G.723.1 | |
| Скорость бит, кбит/с | 8 | 8 | 5,3…6,3 |
| Размер фрейма, мс | 10 | 10 | 30 |
| Размер подфрейма, мс | 5 | 5 | 7,5 |
| Алгебраическая задержка, мс | 15 | 15 | 37,5 |
| Быстродействие, млн. оп./с | 20 | 10 | 14…20 |
| Объем ПЗУ, байт | 5,2 К | 4 К | 4,4 К |
| Качество | Хорошее | Хорошее | Хорошее |
Для режима 5,3 кбит/с рекомендация G.723.1 предусматривает фреймы возбуждения длительностью 7,5 мс и также использует четырехимпульсное ACELP-возбуждение кодовой страницы. Для скорости 6,3 кбит/с используется технология многоимпульсного возбуждения с квантованием и алгоритмом максимального правдоподобия (MP-MLQ). В этом случае позиции фреймов группируются в подгруппы с четными и нечетными номерами. Для определенного номера импульса из четной последовательности (пятый или шестой в зависимости от того, является ли сам фрейм четным или нечетным) используется последовательный многоимпульсный поиск. Похожий поиск повторяется для подфреймов с нечетными номерами. Для возбуждения выбирается группа с минимальными общими искажениями.
На стороне декодера информация кодера с линейным предсказанием (LPC) и информация адаптивной и фиксированной кодовой книг демультиплексируется и используется для реконструкции выходного сигнала. Для этих целей используется адаптивный постфильтр. В случае кодера G.723.1 сигнал возбуждения перед прохождением через фильтр синтеза LPC пропускается через LT (long-term — долговременный) постфильтр и ST (short-term — кратковременный) постфильтр.
|
из
5.00
|
Обсуждение в статье: Рекомендации G.723.1 и G.729 |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы