 |
Главная |


Кодеры стандарта D-AMPS
|
из
5.00
|
Цифровой стандарт мобильной радиосвязи D-AMPS (Digital Advanced Mobile Phone Service), принятый в США в 1990 г., по своим функциональным возможностям и предоставляемым услугам приближается к стандарту GSM. Стандарт D-AMPS не принят в европейских странах, за исключением России, где он в основном ориентирован на региональное использование.
Блок предварительной обработки выполняет следующие функции:
предварительную цифровую фильтрацию входного сигнала с целью подъема верхних частот, на долю которых в спектре речевого сигнала приходится меньшая мощность;
«нарезание» сигнала на сегменты по 160 выборок (20 мс).
Для каждого 20-мс сегмента оцениваются параметры фильтра кратковременного линейного предсказания – 10 коэффициентов частичной корреляции 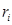 ,
, 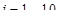 (порядок предсказания М = 10), которые непосредственно кодируются для передачи в канал связи без каких-либо дополнительных преобразований, и оценивается амплитудный множитель р, определяющий энергию сегмента речи.
(порядок предсказания М = 10), которые непосредственно кодируются для передачи в канал связи без каких-либо дополнительных преобразований, и оценивается амплитудный множитель р, определяющий энергию сегмента речи.
Сигнал с выхода предварительной обработки фильтруется фильтром-анализатором кратковременного линейного предсказания A(z), имеющего форму трансверсального линейного фильтра, для чего коэффициенты частичной корреляции 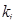 преобразуются в коэффициенты линейного предсказания
преобразуются в коэффициенты линейного предсказания  .
.
Выходной сигнал фильтра кратковременного предсказания (остаток предсказания 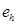 ) используется для оценки параметров фильтра
) используется для оценки параметров фильтра 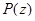 долговременного предсказания – задержки τ и коэффициента предсказания
долговременного предсказания – задержки τ и коэффициента предсказания  , причем параметры долговременного предсказания оцениваются в отдельности для каждого из четырех подсегментов по 40 выборок, на которые разделяется сегмент из 160 выборок.
, причем параметры долговременного предсказания оцениваются в отдельности для каждого из четырех подсегментов по 40 выборок, на которые разделяется сегмент из 160 выборок.
Для каждого из подсегментов определяются параметры сигнала возбуждения. Для этого в составе кодера используется схема, аналогичная входящей в состав декодера, которая включает фильтры-синтезаторы кратковременного 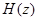 и долговременного
и долговременного 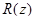 предсказания и две кодовые книги и реализует метод «анализа-через-синтез». Каждая из кодовых книг сигнала возбуждения содержит 128 кодовых векторов, по 40 элементов в каждом.
предсказания и две кодовые книги и реализует метод «анализа-через-синтез». Каждая из кодовых книг сигнала возбуждения содержит 128 кодовых векторов, по 40 элементов в каждом.
Все кодовые векторы одной книги являются элементами 7-мерного линейного подпространства в 40-мерном пространстве. Каждая кодовая книга, содержащая 128 векторов, задается семью базисными векторами и 128 кодовыми словами (7-элементными векторами коэффициентов линейных комбинаций) с однобитовыми элементами.
Сигнал возбуждения фильтр синтезатора кратковременного предсказания, в соответствии со схемой декодера рис. 5.4, является суммой векторов возбуждения из двух кодовых книг и вектора с выхода фильтра синтезатора долговременного предсказания. Векторы возбуждения из кодовых книг до подачи на сумматор умножаются на соответствующие коэффициенты усиления 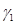 и
и 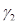 , а входным сигналом фильтра-синтезатора долговременного предсказания является, в зависимости от участка сегмента, выходной сигнал того же фильтр или суммарный сигнал возбуждения фильтра-синтезатора кратковременного предсказания. Параметры сигнала возбуждения – номера векторов возбуждения
, а входным сигналом фильтра-синтезатора долговременного предсказания является, в зависимости от участка сегмента, выходной сигнал того же фильтр или суммарный сигнал возбуждения фильтра-синтезатора кратковременного предсказания. Параметры сигнала возбуждения – номера векторов возбуждения 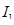 и
и 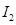 из первой и второй кодовых книг и соответствующие коэффициенты усиления и
из первой и второй кодовых книг и соответствующие коэффициенты усиления и 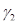 – определяются по критерию минимума среднеквадратичной ошибки на выходе фильтра-синтезатора кратковременного предсказания, входящего в состав кодера. Предварительно базисные векторы обеих кодовых книг ортогонализируются: для первой книги – по отношению к выходному вектору фильтра-синтезатора долговременного предсказания, для второй книги – по отношению к тому же выходному вектору и к базисным векторам первой книги.
– определяются по критерию минимума среднеквадратичной ошибки на выходе фильтра-синтезатора кратковременного предсказания, входящего в состав кодера. Предварительно базисные векторы обеих кодовых книг ортогонализируются: для первой книги – по отношению к выходному вектору фильтра-синтезатора долговременного предсказания, для второй книги – по отношению к тому же выходному вектору и к базисным векторам первой книги.
В результате выходная информация кодера речи для 20-мс сегмента включает:
• параметры фильтра кратковременного линейного предсказания – 10 коэффициентов частичной корреляции , 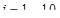 , и амплитудный множитель р – один набор на весь сегмент;
, и амплитудный множитель р – один набор на весь сегмент;
• параметры фильтра долговременного линейного предсказания – коэффициент предсказания 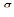 и задержку τ – для каждого из четырех подсегментов;
и задержку τ – для каждого из четырех подсегментов;
• параметры сигнала возбуждения – номера 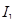 и векторов возбуждения из двух кодовых книг и соответствующие коэффициенты усиления и – для каждого из четырех подсегментов.
и векторов возбуждения из двух кодовых книг и соответствующие коэффициенты усиления и – для каждого из четырех подсегментов.
В табл. 5.2 приведено содержание выходной информации кодера с указанием числа бит, используемых для кодирования.
Таблица 5.2
Кодирование выходной информации кодера речи стандарта D-AMPS
| Передаваемые параметры | Число бит | Примечание |
Параметры кратковременного предсказания (коэффициенты частичной корреляции 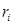 , ,  ) )
| 38 | 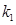 – 6 бит; – 6 бит;
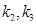 – по 5 бит; – по 5 бит;
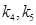 – по 4 бита; – по 4 бита;
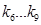 – по 3 бита; – по 3 бита;
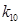 – 2 бита – 2 бита
|
| Амплитудный множитель (энергия сегмента) р | 5 | |
| Задержка фильтра долговременного предсказания τ (для каждого из четырех подсегментов) | 28 | 7 бит на каждый подсегмент |
Номера векторов возбуждения 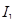 и из двух кодовых книг (для каждого из четырех подсегментов и из двух кодовых книг (для каждого из четырех подсегментов
| 56 | h и i2 по 7 бит |
| Коэффициенты усиления , и (для каждого из четырех подсегментов)
| 32 | 8 бит на каждый подсегмент; векторному квантованию и кодированию подвергаются некоторые функции от 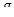 , и , и 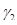
|
| Всего на 20-мс сегмент | 159 |
Общий объем информации, выдаваемой для 20-мс сегмента речи, составляет 159 бит. Поскольку исходный объем информации на входе кодера составляет 1280 бит (160 выборок по 8 бит), кодер осуществляет сжатие информации более чем в 8 раз. Перед передачей в канал связи выходная информация кодера речи подвергается дополнительному канальному кодированию, причем разные параметры в зависимости от их важности для обеспечения качества речи кодируются с различной степенью избыточности.
Функционирование декодера осуществляется по следующему алгоритму. Сигнал возбуждения фильтра-синтезатора кратковременного предсказания формируется таким же образом, как и в синтезирующей схеме кодера:
по номерам 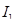 и из кодовых книг выбираются векторы возбуждения, которые умножаются соответственно на коэффициенты усиления и и складываются с выходным вектором фильтра-синтезатора долговременного предсказания, определяемого параметрами и τ.
и из кодовых книг выбираются векторы возбуждения, которые умножаются соответственно на коэффициенты усиления и и складываются с выходным вектором фильтра-синтезатора долговременного предсказания, определяемого параметрами и τ.
Окончательно сигнал возбуждения фильтруется фильтром-синтезатором кратковременного предсказания, выполненного в форме трансверсального фильтра, т.е. параметры фильтра преобразуются из коэффициентов частотной корреляции 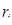 в коэффициенты предсказания
в коэффициенты предсказания 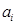 . Для улучшения субъективного качества синтезированной речи выходной сигнал фильтра-синтезатора подвергается цифровой адаптивной постфильтрации и с выхода постфильтра получается восстановленный цифровой речевой сигнал.
. Для улучшения субъективного качества синтезированной речи выходной сигнал фильтра-синтезатора подвергается цифровой адаптивной постфильтрации и с выхода постфильтра получается восстановленный цифровой речевой сигнал.
Кодеры TETRA
TETRA (Trans-European Trunked Radio) представляет собой стандарт цифровой транкинговой радиосвязи, состоящий из ряда спецификаций, разработанных Европейским институтом телекоммуникационных стандартов ETSI.
TETRA — открытый стандарт, т.е. доступ к спецификациям TETRA свободен для всех заинтересованных сторон. В связи с этим оборудование различных производителей должно быть совместимо.
Стандарт TETRA создавался как единый общеевропейский цифровой стандарт. Стандарт разработай на основе технических решений и рекомендаций стандарта GSM и ориентирован на создание систем связи, эффективно и экономично поддерживающих совместное использование сетей различными группами пользователей с обеспечением секретности и защищенности информации.
Речевой кодер TETRA основан на модели кодирования CELP – с линейным предсказанием с кодовым возбуждением. В этой модели блок из N речевых выборок синтезируется путем фильтрации соответствующей обновленной последовательности из кодовой книги, масштабированной коэффициентом усиления 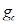 , с помощью двух изменяющихся во времени фильтров.
, с помощью двух изменяющихся во времени фильтров.
Первый фильтр является фильтром долгосрочного предсказания (фильтром основного тона), цель которого – моделирование псевдопериодического речевого сигнала, а второй – фильтр краткосрочного предсказания – моделирует огибающую речевого спектра.
Передаточная характеристика долгосрочного фильтра (или фильтра синтеза основного тона) определяется формулой
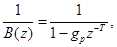
где Т – задержка основного тона; 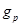 – коэффициент усиления основного тона. Фильтр синтеза основного тона выполнен как адаптивная кодовая книга, где для задержек, меньших чем длина подфрейма, повторяется последнее возбуждение.
– коэффициент усиления основного тона. Фильтр синтеза основного тона выполнен как адаптивная кодовая книга, где для задержек, меньших чем длина подфрейма, повторяется последнее возбуждение.
Краткосрочный фильтр синтеза определяется формулой
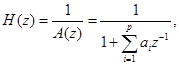
где , 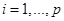 , – параметры линейного предсказания; р – порядок предсказателя. В кодере TETRA порядок р = 10.
, – параметры линейного предсказания; р – порядок предсказателя. В кодере TETRA порядок р = 10.
При способе анализа-через-синтез синтезированная речь вычисляется для всех кандидатов – последовательностей, составляя особую последовательность, которая и формирует выходной сигнал, наиболее близкий к исходному, в соответствии с взвешенной величиной измеренных искажений. Фильтр взвешивания, корректирующий ошибку предыскажений в области форманты спектра речи, определяется формулой
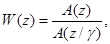 (5.1)
(5.1)
где 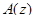 – обратный (инверсный) фильтр линейного предсказания;
– обратный (инверсный) фильтр линейного предсказания; 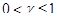 (используется значение
(используется значение 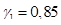 ). Для взвешивающего фильтра
). Для взвешивающего фильтра 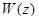 и фильтра синтеза формант
и фильтра синтеза формант 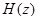 используются квантованные параметры линейного предсказания.
используются квантованные параметры линейного предсказания.
В алгебраическом CELP (ACELP) используется специальная кодовая книга, имеющая алгебраическую структуру. Эта алгебраическая структура имеет некоторые преимущества в отношении сохранения, сложности поиска и устойчивости (робастности). Кодер TETRA использует специальную динамическую алгебраическую кодовую книгу возбуждения, посредством которой, а также динамической матрицы формы образуются фиксированные векторы возбуждения. Матрица формы – это функция модели A(z) линейного предсказания. Главная ее роль – формировать векторы возбуждения в частотной области так, чтобы их энергии были сконцентрированы в наиболее важных частотных полосах. Используемая матрица формы является триангулярной Теплицевой матрицей низшего порядка, сформированной из импульсного отклика фильтра:
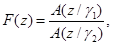 (5.2)
(5.2)
где A(z) — инверсный фильтр линейного предсказания (в конкретных реализациях 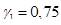 и
и 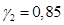 ).
).
В кодере TETRA используются фреймы речи по 30 мс. Это требуется для того, чтобы параметры краткосрочного предсказания вычислялись и передавались в каждом речевом фрейме. Речевой фрейм разделен на четыре подфрейма по 7,5 мс (60 выборок). Основной тон и параметры алгебраической кодовой книги также передаются в каждом подфрейме. В табл. 5.3 представлено распределение бит для кодера TETRA. Должно быть сформировано 137 бит для каждого фрейма по 30 мс, что в результате дает скорость 4567 бит/с.
Таблица 5.3
| Параметр | Номер сегмента | Всего в кадре | |||
| 1 | 2 | 3 | 4 | ||
| Коэффициенты линейного предсказания | 26 | ||||
| Период основного тона | 8 | 5 | 5 | 5 | 23 |
| Индекс алгебраической кодовой книги | 16 | 16 | 16 | 16 | 64 |
| Коэффициенты усиления | 6 | 6 | 6 | 6 | 24 |
| Всего | 137 | ||||
|
из
5.00
|
Обсуждение в статье: Кодеры стандарта D-AMPS |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы