 |
Главная |


Кодеры стандарта АРСО 25
|
из
5.00
|
АРСО 25 – стандарт транкинговой радиосвязи, описывающий структуру цифровой транкинговой системы и некоторые ее интерфейсы. Для цифровой передачи речи стандарт АРСО 25 предусматривает использование кодера IMBE (Improved MultiBand Excitation, модифицированный метод многополосного возбуждения). Кодер формирует цифровой поток со скоростью 4,4 кбит/с. Для исправления ошибок в цифровом речевом сигнале используется избыточное кодирование, порождающее дополнительный цифровой поток со скоростью 2,8 кбит/с.
Цифровой речевой сигнал передается кадрами длительностью 180 мс. Два речевых кадра образует суперкадр длительностью 360 мс. Перед передачей речи следует преамбула длительностью 82,5 мс, которая содержит синхропакет (48 бит), идентификатор сети (64 бита), служащий для предотвращения конфликтов между радиостанциями, работающими на одной частоте; информацию для алгоритма шифрования, идентификатор ключа алгоритма шифрования и другие служебные идентификаторы (всего 126 бит). Кадры речи, кроме собственно речевой информации, содержат дополнительную информацию (управления связью, канала сигнализации и т.д.)
Речевой IMBE-кодер основан на модели речи, которая относится к моделям с многополосным возбуждением (МВЕ). Основная идея работы кодера состоит в разделении цифрового речевого входного сигнала на перекрывающиеся речевые сегменты (или фреймы) с использованием окна Кайзера. Затем для определенного фрейма оценивается набор параметров.
Речевой MBE-кодер является вокодером, т.е. он не кодирует входной речевой сигнал выборка за выборкой, а синтезирует сигнал, который содержит ту же информацию для восприятия человеком, что и исходный речевой сигнал. Заметим, что когда речь не является вокализованнной, исходный и синтезированный сегменты речи могут не иметь никакого сходства во временной области.
Речевой MBE-кодер имеет два основных преимущества перед ранее используемыми вокодерами: во-первых, он основан на МВЕ речевой модели, которая является более устойчивой, чем традиционные речевые модели в рассмотренных вокодерах; во-вторых, данный метод использует более сложный алгоритм оценки параметров модели речевого синтеза речевого сигнала из параметров модели.
Главное отличие речевых традиционных вокодеров от модели МВЕ состоит в сигнале возбуждения. В обычных речевых моделях для каждого речевого сегмента используется единственное решение вокал/невокал. В отличие от этого речевая модель МВЕ разделяет сигнал возбуждения на несколько неперекрывающихся частотных полос и принимает решение вокал/невокал для каждой частотной полосы. Это позволяет представить сигнал возбуждения для определенного речевого сегмента в виде смеси периодической (вокализованной) энергии и шумоподобной (невокализованной) энергии. Из-за этих множественных определений вокал/невокал эта модель называется моделью с многополосным возбуждением. Такая речевая модель позволяет синтезировать речь с более качеством, чем традиционные модели. Кроме того, речевая модель МВЕ более устойчива к фоновому шуму.
В речевой модели MBE сигнал возбуждения формируется из сигнала основного тона (или основной частоты) и решений вокал/невокал. Для вокализованной речи сигнал возбуждения является периодической импульсной последовательностью, в которой расстояние между импульсами определяется периодом основного тона 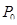 . Для невокализованной речи сигнал возбуждения представляет собой белый шум. Периодический спектр создается из взвешенной периодической последовательности импульсов, которая полностью определяется окном взвешивания и периодом основного тона. Его спектр формируется из взвешенной последовательности случайного шума.
. Для невокализованной речи сигнал возбуждения представляет собой белый шум. Периодический спектр создается из взвешенной периодической последовательности импульсов, которая полностью определяется окном взвешивания и периодом основного тона. Его спектр формируется из взвешенной последовательности случайного шума.
Обычно алгоритмы для оценки параметров возбуждения и алгоритмы для оценки параметров огибающей спектра работают независимо. Эти параметры оцениваются на основе нескольких критериев без ясных оснований, насколько синтезированная речь должна быть близка к исходной. Это может проявиться в том, что синтезированный спектр будет слегка отличаться от исходного.
В речевом IMBE-кодере параметры возбуждения и огибающей спектра оцениваются одновременно так, что синтезированный спектр является самым близким к исходному речевому спектру.
Блок-схема алгоритма анализа показана на рис. 5.7.

Рисунок 5.7
Параметры МВЕ модели речи, которые должны быть оценены для каждого речевого фрейма следующие:
период основного тона (или основная частота);
решение вокал/невокал;
спектральные амплитуды, характеризующие огибающую спектра.
В декодере вокализированная и невокализированная компоненты синтезируются отдельно и на заключительной стадии объединяются для получения полного речевого сигнала. Алгоритмы, которые используются для синтеза вокализированных и невокализированных частей речи, основаны на двух различных способах.
Невокализованная часть речи генерируется из гармоник, которые объявлены невокализованными. Для каждого фрейма речи блок случайного шума взвешивается и преобразуется с помощью быстрого преобразования Фурье. Области спектра, которые соответствуют вокализованным гармоникам, принимаются равными нулю.
Так как вокализованная речь моделируется ее индивидуальными гармониками в частотной области, на стороне декодера она восстанавливается как совокупный сигнал регулируемых генераторов. Каждой гармонике вокализованной области фрейма поставлен в соответствие генератор, который характеризуется частотой и фазой. Однако из-за того, что вокализованная часть речи не является периодической на интервалах, состоящих нескольких фреймов анализа, отклонения от ожидаемых параметров соседних фреймов могут вызвать скачки по концам фреймов, что приведет к значительному ухудшению качества речи. Для разрешения этой проблемы во время синтеза проверяются параметры текущего и предыдущего фреймов для уверенности, что на границе фреймов происходит плавный переход. Это делается для того, чтобы на границах фреймов вокализированная речь была непрерывной. Для обеспечения непрерывности в начале и конце фрейма речи функция амплитуды линейно интерполируется между значениями оценок для текущего и предыдущего фреймов.
Синтез речи в IMBE-декодере требует информации об основной частоте, решении вокал/невокал, величине спектральных составляющих и фазе вокализованных гармоник. Так как фазы вокализованных гармоник можно предсказать, информация о фазе не передается между кодером и декодером. Основная частота (основой тон) квантуется с половинной точностью выборки во временной области, причем возможный диапазон тона перекрывается восемью битами. Peшение вокал/невокал является двоичным числом и не требует квантования. Общее распределение бит для каждого фрейма приведено в табл. 5.4.
Таблица 5.4.
Распределение бит IMBE-кодера в системе АРСО 25
| Параметр | Число бит |
| Основная частота | 8 |
| Информация вокал/невокал | b |
| Спектральные амплитуды | 79 – b |
| Синхронизация | 1 |
Число полос, на которые разбивается речевой фрейм в частотной области, зависит от основного тона фрейма, но не превышает 12.
Таким образом, в кодере IMBE фрейм речи имеет длительность 20 мс, содержит 144 бита, из которых 56 используются для канального кодирования, 88 – для кодирования параметров речевой модели. Кодер работает на скорости 4,4 кбит/с. Скорость передачи в канале – 7,2 кбит/с.
|
из
5.00
|
Обсуждение в статье: Кодеры стандарта АРСО 25 |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы