 |
Главная |


Проверка на гетероскедастчность данных
|
из
5.00
|
а) Тест Голдфелда-Квандта (применим, если выполняется условия (5) МНК).
Для проверки на гетероскедастичности оценивают дисперсию фактической ошибки  которую сравнивают с χ-квадрат распределением (χ-квадрат –распределение для оценки берется потому, что на него похожа величина, которой границу (критический уровень) доверительного интервала для оценки дисперсии). Если, например, дисперсия ошибки уложилась в 95-99% -ный доверительный интервал , то условие гомоскедастичности считается выполненным. Доверит. интервал находят по формуле:
которую сравнивают с χ-квадрат распределением (χ-квадрат –распределение для оценки берется потому, что на него похожа величина, которой границу (критический уровень) доверительного интервала для оценки дисперсии). Если, например, дисперсия ошибки уложилась в 95-99% -ный доверительный интервал , то условие гомоскедастичности считается выполненным. Доверит. интервал находят по формуле:
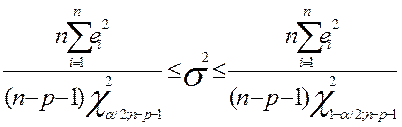
где критическое значение χ –квадрат определяется с учетом уровня значимости α и степеней свободы (n-p-1) по таблице χ-распределения, ei=Y(xi)-Yi.
б) можно для оценки дисперсии σ2 использовать двусторонний критерий Фишера (выборку разбивают на 3 интервала (1 и 3 – одинакового размера) (или просто пополам - (по индексам, например, так:
от 1- до m; ;от m+1 до n
и вычисляют дисперсию ошибки для 1-го и 2-го кусков выборки по отдельности. Потом делят дисперсию ошибки для последнего куска на дисперсию ошибки для 1-го куска и проверяют, попадает ли полученная величина в доверит. диапазон, образованный значениями распределения Фишера: для нижней границы диапазона по таблице распред. Фишера ищут значение с заданной доверит. вероятностью и числом стпеней свобoды (n-p-1), для верхней границы доверит диапазона знач. распр. Фишера с той же доверит вероятностью, но числом степеней свободы (n-m-p-1). Если отношение 2-х дисперсий ошибок на кусках выборки попала в этот доверит. интервал, то считается, что условие (11) соблюдено, т.е. нет проблемы. гетероскедастичности.
Если число n очень велико, то для проверки постоянства дисперсии ошибки (т.е. проверки на отсутствие гетероскедастичности) может быть использован критерий Бартлета (отличается тем, что выборку разбивают на k>3 участков, чтобы анализ был точнее.
в) Тест корреляции Спирмена – ищут т.н. коэффициент ранговой корреляции
Если имеют дело с переменными, выражающими не количество, а качество (степень выраженности какого-нибудь качества), то можно искусственно ввести ранги – условное численное обозначение для степени выраженности качества. Ранговые переменные тоже могут коррелировать друго с другом и другми переменными и их надо как-то сравнивать. Для этого применяют коэфф. ранговой корреляции, а для проверки на гетероскедастичность для ранговых переменных можно использовать такой прием. По формуле
 , где di – разность между рангами i-го объекта по переменной xi и ошибке ei , затем вычисляют величину |t|=
, где di – разность между рангами i-го объекта по переменной xi и ошибке ei , затем вычисляют величину |t|=  .
.
Эту величину |t| сравнивают с табличным значением t-распределения Стьюдента 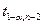 (при уровне значимости α (обычно 0,05) и если она будет больше критического
(при уровне значимости α (обычно 0,05) и если она будет больше критического  , значит имеется, возможно, гетероскедастичность.
, значит имеется, возможно, гетероскедастичность.
г) Тест Уайтана гетероскедастичность – дисперсию ошибки регрессии оценивают, строя уравнение регрессии ошибки к переменным Х (т.е. строят обычное уравнение регрессии, но вместо Y – квадрат ошибки

Затем эту регрессию анализируют - например, вычисляют коэффициент детерминации. Если коэфф. детерминации R2 оказался близок к нулю, т.е. f(x) оказалась незначима для ошибки (т.е. ошибка не зависит от Х), значит нет гетероскедастичности.
5) Тест Глейзера на гетероскедастичность – почти то же самое, только вместо  берут модуль |
берут модуль |  | - а дальше также.
| - а дальше также.
2)Еще одно условие для применения МНК для оценки параметров множественной регрессии - отсутствие автокорреляции между ошибками регрессии, взятыми в разные моменты:
Cov( ε i , ε j )=0 для любых i,j=1..n
или то же самое, но в матричной форме: М(ε εт) =σ2 En , где М(ε εт) – это матриц размера (n x n), состоящая из матожиданий произведений возмущений, ε и εт – строка и столбец ошибок регрессии ε = (ε 1, ..., ε n )
σ2 - дисперсия ошибок,
En - единичная матрица размера n x n. Т.е. условие отсутствия автокорреляции остатков в матричной записи выглядит так:
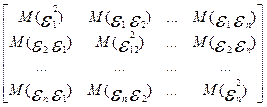 =
= 
Автокорреляция проявляется в том, что предыдущие значения наблюдений влияют на последующие (например, для временных рядов для ошибки это влияние выражается как-нибудь так:  ). Автокорреляция возникает из-за неудачной формы функции регрессии (например, вместо квадратичной зависимости Y от одного из переменных в функции использована линейная зависимость), или из-за того, что на разных частях выборки (например, для временного ряда) надо было взять разные модели, а не одну (т.е. различные, а не одну функции регрессии). Еще одна причина автокорреляции ошибок – неучет каких-то значимых факторов (переменных) в модели, на которую и приходится автокорреляция.
). Автокорреляция возникает из-за неудачной формы функции регрессии (например, вместо квадратичной зависимости Y от одного из переменных в функции использована линейная зависимость), или из-за того, что на разных частях выборки (например, для временного ряда) надо было взять разные модели, а не одну (т.е. различные, а не одну функции регрессии). Еще одна причина автокорреляции ошибок – неучет каких-то значимых факторов (переменных) в модели, на которую и приходится автокорреляция.
Есть ли автокорреляция или нет, можно узнать тестом Дарбина-Уотсона, Q-тест Льюинга_Бокса, тест серий Бреуша-Годфри (рассмотрим когда будет идти речь о динамических моделях).
Например, уже упоминавшийся тест Дарбина –Уотсона оценивает, есть ли корреляция между εt и εt+1:
 , где et=
, где et= 
 . Надо убедиться, что d далек от критических крайних значений.
. Надо убедиться, что d далек от критических крайних значений.
3) Проверка на отсутствие мультиколлинеарности - между переменными есть зависимость, корреляция, а тогда МНК даст плохую модель (грубую регрессию).
Выполняется одним из следующих способов:
(I) можно обнаружить мультиколлинеарность, проверив не велики ли множественные коэффициенты детерминации D=R2 (только не для набора Х + Y, а для наборов: отдельный факторов Х + все остальные Х). Если для некоторых переменных Х коэфф. детерминации окажется около 1 (и вообще больше 0,6), то есть подозрение на мультиколлинеарность этих переменных Х.
Вместо точечной оценки коэффициента детерминации при этом можно использовать и интервальную оценку (критерий Фишера – см. выше): если коэффициент Фишера (для выяснения мультиколлинеарности)
Fi= 
где n – число наблюдений, р – число факторов, i – номер фактора, для которого вычисляется множественный коэфф. детерминации Ri. Величина Fi затем сравнивается с соответствующим критическим значением  распределения Фишера для уровня значимости α (берут оычно число от 0,01 до 0,05) и количества наблюдений n и числе факторов р. Если окажется, что
распределения Фишера для уровня значимости α (берут оычно число от 0,01 до 0,05) и количества наблюдений n и числе факторов р. Если окажется, что
Fi > 
- это значит, что существует мультиколлинеарность для i-й переменной.
(II) Второй способ - посчитать определитель матрицы ХТХ – обычно когда определитель матрицы =0, то матрица необратима. В случае det (ХТХ)=0 нельзя будет вычислить методом МНК параметры модели по формуле – в этом и состоит проблема мультиколлинеарности.
Поэтому даже если det (ХТХ) не ноль, но близок к нулю (или одного порядка с накапливающимися ошибками вычисления), то невозможно будет найти обратную матрицу к ХТХ при подсчете параметров модели, а значит и коэффициенты регрессионной модели b не вычислишь по обычному МНК.
(III) Третий способ - вычисляют коэффициенты парной корреляции  (формула 15) для разных пар переменных (факторов) Х. Если для некоторых пар коэффициент корреляции окажется близок к 1 (обычно больше 0,8), то это может говорить о мультиколлениарности этих факторов (корреляции).
(формула 15) для разных пар переменных (факторов) Х. Если для некоторых пар коэффициент корреляции окажется близок к 1 (обычно больше 0,8), то это может говорить о мультиколлениарности этих факторов (корреляции).
Этот метод проверки на мультиколлинеарность имеет смысл вот почему. У вырожденных матриц рангменьше min(р, n), т.к. некоторые строки или столбцы вырожденных матриц линейно зависимы друг от друга или (что тоже самое) состоят из одних нулей. Учитывая это, можно сформулировать требование:
матрица ХТХ =  должна быть невырожденной, а для этого любые факторы Хi в модели не должны коррелировать (быть зависимы друг от друга), а это, в свою очередь означает, что парные коэффициенты корреляции rij любых 2-х переменных Xi Xj не превышают некоторого порогового значения, т.е.
должна быть невырожденной, а для этого любые факторы Хi в модели не должны коррелировать (быть зависимы друг от друга), а это, в свою очередь означает, что парные коэффициенты корреляции rij любых 2-х переменных Xi Xj не превышают некоторого порогового значения, т.е.
 некоторое пороговое значение (обычно менее 0,8)
некоторое пороговое значение (обычно менее 0,8)
Если  = 1 или близок к 1, значит между переменными есть зависимость, корреляция, а тогда МНК даст плохую модель (грубую регрессию).
= 1 или близок к 1, значит между переменными есть зависимость, корреляция, а тогда МНК даст плохую модель (грубую регрессию).
Пояснение: парным коэффициентом корреляции двух переменных (Хi и Хj, например) называют число:  где
где  - алгебраическое дополнение элемента
- алгебраическое дополнение элемента 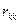 из матрицы вида:
из матрицы вида:  , где элементы вида
, где элементы вида  (s – среднекватратическое отклонение соотвествующей отдельной переменной от своего средневыборочного).
(s – среднекватратическое отклонение соотвествующей отдельной переменной от своего средневыборочного).
Можно использовать и интервальную оценку коэффициента корреляции - можно сравнивать 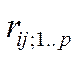 с критическим значением t-распределения Стьюдента (критич. значение ищут по таблицам распределения Стьюдента с учетом уровня значимости α (обычно 0,05) и числа степеней свободы n-p-1). Если t-оценка коэффициента корреляции для какой-то пары переменных будет больше критического (табличного), то корреляция (мультиколлинеарность этих 2-х переменных) имеет место (знак при r тоже имеет значение – прямая или обратная связь переменных подразумевается, в зависимости от знака).
с критическим значением t-распределения Стьюдента (критич. значение ищут по таблицам распределения Стьюдента с учетом уровня значимости α (обычно 0,05) и числа степеней свободы n-p-1). Если t-оценка коэффициента корреляции для какой-то пары переменных будет больше критического (табличного), то корреляция (мультиколлинеарность этих 2-х переменных) имеет место (знак при r тоже имеет значение – прямая или обратная связь переменных подразумевается, в зависимости от знака).
4) Проверка отсутствия корреляции между остатками ei,i=1,2,…n., например, тестом Дарбина-Уотсона:  Величина должна укладываться к критические границы d1 и d2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n и количества объясняющих переменных m.
Величина должна укладываться к критические границы d1 и d2 определяются на основе специальных таблиц для требуемого уровня значимости α, числа наблюдений n и количества объясняющих переменных m.
5) Нормальность распределения случайной величины ε (ε – ошибка регрессии). Иначе говоря, ε должна себя вести как истинная случайная величина, как белый шум, а не быть увязанной со значениями факторов Х, т.е. Cov( х ij, ε) = 0
|
из
5.00
|
Обсуждение в статье: Проверка на гетероскедастчность данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы