 |
Главная |


Модель сети типа радиально-базисной функции
|
из
5.00
|
Радиально-базисные сети были предложены для аппроксимации функций многих переменных. C помощью радиально-базисных функций можно сколь угодно точно аппроксимировать заданную функцию. Как и многослойный персептрон, радиально-базисная сеть является универсальным аппроксиматором. Математическую основу РБ-сети составляет метод потенциальных функций, разработанный М.А. Айзерманом, Э.М. Браверианом и Л.И. Розоноэром, позволяющий представить некоторую функцию у(х) в виде суперпозиции потенциальных или базисных функций fi(x)
 (4.9)
(4.9)
где ai(t) = (a1, a2,..., aN)T – вектор подлежащих определению параметров; f(x) = (f1(x), f2(x),..., fN(x))T – вектор базисных функций.
В РБС в качестве базисных выбираются некоторые функции расстояния между векторами
 (4.10)
(4.10)
Векторы сi называют центрами базисных функций. Функции fi(x) выбираются неотрицательными и возрастающими при увеличении  . В качестве меры близости векторов х и ci выбираются обычно либо евклидова метрика
. В качестве меры близости векторов х и ci выбираются обычно либо евклидова метрика  либо манхэттенская
либо манхэттенская  где
где 
 (4.11)
(4.11)
Радиально-базисные сети обладают большой скоростью обучения. При их обучении не возникает проблем с «застреванием» в локальных минимумах. Однако в связи с тем, что при выполнении непосредственно классификации проводятся довольно сложные вычисления, возрастает время получения результата.
Структура РБФ
Структура РБФ соответствует сети прямого распространения первого порядка (рисунок 4.10).
Информация об образах передается с входного слоя на скрытый, являющийся шаблонным и содержащий ρ нейронов. Каждый нейрон шаблонного слоя, получая полную информацию о входных сигналах х, вычисляет функцию
 (4.12)
(4.12)
где вектор входных сигналов 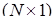 ; ci - вектор центров
; ci - вектор центров  ; R – весовая матрица.
; R – весовая матрица.

Рисунок 4.10 – Структура радиально-базисной сети
Особенностью данных сетей является наличие радиально-симметричного шаблонного слоя, в котором анализируется расстояние  между входным вектором и центром, представленным в виде вектора во входном пространстве. Вектор центров определяется по обучающей выборке и сохраняется в пространстве весов от входного слоя к слою шаблонов.
между входным вектором и центром, представленным в виде вектора во входном пространстве. Вектор центров определяется по обучающей выборке и сохраняется в пространстве весов от входного слоя к слою шаблонов.
Рассмотрим нейрон шаблонного слоя сети. На рисунке 4.11 представлен i-й нейрон шаблонного слоя РБ-сети. Обработку поступающей на него информации условно можно разделить на два этапа: на первом вычисляется расстояние между предъявленным образом х и вектором центров сi с учетом выбранной метрики и нормы матрицы R, на втором это расстояние преобразуется нелинейной активационной функцией f(x). Двойные стрелки на рисунке обозначают векторные сигналы, а тройные - матричный сигнал.

Рисунок 4.11 – Нейрон шаблонного слоя РБС
В качестве функции преобразования  наиболее часто выбираются следующие:
наиболее часто выбираются следующие:
– гауссова функция
 (4.13)
(4.13)
– мультиквадратичная функция
 (4.14)
(4.14)
– обратная мультиквадратичная функция
 (4.15)
(4.15)
– сплайн-функция
 (4.16)
(4.16)
– функция Коши
 (4.17)
(4.17)
Норма матрицы R-1 определяет положение осей в пространстве. В общем виде матрица R-1 может быть представлена следующим образом:
 (4.18)
(4.18)
Весовую матрицу R1 также называют обратной ковариационной матрицей. Элементы этой матрицы равны
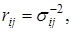
 (4.19)
(4.19)
Здесь  – некоторые управляемые параметры.
– некоторые управляемые параметры.
Часто матрица R-1 выбирается диагональной, т.е.  для i≠j, и более того, принимают
для i≠j, и более того, принимают 
Величина сигнала j-го нейрона выходного слоя уj зависит от того, насколько близок предъявляемый входной сигнал х запомненному этим нейроном центру сj. Значение уj определяется как взвешенная сумма функций (4.9), т.е.
 (4.20)
(4.20)
Обычно выходными сигналами сети являются нормализованные значения  вычисленные по формуле
вычисленные по формуле
 (4.21)
(4.21)
Обучение РБФ
РБ-сеть характеризуют три типа параметров:
– линейные весовые параметры выходного слоя wij входят в описание сети линейно);
– центры ci – нелинейные (входят в описание нелинейно) параметры скрытого слоя;
– отклонения (радиусы базисных функций) σij – нелинейные параметры скрытого слоя.
Обучение сети, состоящее в определении этих параметров, может сводиться к одному из следующих вариантов:
1. Задаются центры и отклонения, а вычисляются только веса выходного слоя.
2. Определяются путем самообучения центры и отклонения, а для коррекции весов выходного слоя используется обучение с учителем.
3. Определяются все параметры сети с помощью обучения с учителем.
Первые два варианта применяются в сетях, использующих базисные функции с жестко заданным радиусом (отклонением). Третий же вариант, являясь наиболее сложным и трудоемким в реализации, предполагает использование любых базисных функций.
Таким образом, обучение сети заключается в следующем:
– определяются центры ci;
– выбираются параметры σi;
– вычисляются элементы матрицы весов W.
Рассмотрим методику выбора параметров центров и отклонений σ. Центры ci определяют точки, через которые должна проходить аппроксимируемая функция. Поскольку большая обучающая выборка приводит к затягиванию процесса обучения, в РБ-сетях широко используется кластеризация образов, при которой схожие векторы объединяются в кластеры, представляемые затем в процессе обучения только одним вектором. В настоящее время существует достаточно большое число эффективных алгоритмов кластеризации.
Использование кластеризации отражается на формулах (4.20), (4.21) следующим образом:
 (4.22)
(4.22)
где mi - число входных векторов в i-м кластере.
В наиболее простом варианте алгоритм кластеризации, алгоритм k-среднего, направляет каждый образ в кластер, имеющий ближайший к данному образу центр. Если количество центров заранее задано или определено, алгоритм, обрабатывая на каждом такте входной вектор сети, формирует в пространстве входов сети центры кластеров. С ростом числа тактов эти центры сходятся к центрам данных. Кандидатами в центры являются все выходы скрытого слоя, однако в результате работы алгоритма будет сформировано подмножество наиболее существенных выходов.
Как уже указывалось, параметр σi, входящий в формулы для функций преобразования, определяет разброс относительно центра сi. Варьируя параметры ci и σi, пытаются перекрыть все пространство образов, не оставляя пустот. Используя метод k-ближайших соседей, определяют k соседей центра ci и, усредняя, вычисляют среднее значение  Величина отклонения
Величина отклонения  от ci служит основанием для выбора параметра σi. На практике часто оправдывает себя выбор
от ci служит основанием для выбора параметра σi. На практике часто оправдывает себя выбор
 (4.23)
(4.23)
где d=max(ci – ck) - максимальное расстояние между выбранными центрами; р - количество нейронов шаблонного слоя (образов).
Если качество аппроксимации является неудовлетворительным, выбор параметров ci и σ, а также определение весов W повторяют до тех пор, пока полученное решение не окажется удовлетворительным.
|
из
5.00
|
Обсуждение в статье: Модель сети типа радиально-базисной функции |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы