 |
Главная |


Оценка адекватности и точности моделей
|
из
5.00
|
Независимо от вида и способа построения экономико-математической модели вопрос о возможности ее применения в целях анализа и прогнозирования экономического явления может быть решен только после установления адекватности, т.е. соответствия модели исследуемому процессу или объекту. Так как полного соответствия модели реальному процессу или объекту быть не может, адекватность - в какой-то мере условное понятие. При моделировании имеется в виду адекватность не вообще, а по тем свойствам модели, которые считаются существенными для исследования.
Трендовая модель 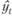 , конкретного временного ряда yt, считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента
, конкретного временного ряда yt, считается адекватной, если правильно отражает систематические компоненты временного ряда. Это требование эквивалентно требованию, чтобы остаточная компонента  (t = 1, 2, ..., п) удовлетворяла свойствам случайной компоненты временного ряда, указанным в параграфе 4.1: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. Рассмотрим, каким образом осуществляется проверка этих свойств остаточной последовательности.
(t = 1, 2, ..., п) удовлетворяла свойствам случайной компоненты временного ряда, указанным в параграфе 4.1: случайность колебаний уровней остаточной последовательности, соответствие распределения случайной компоненты нормальному закону распределения, равенство математического ожидания случайной компоненты нулю, независимость значений уровней случайной компоненты. Рассмотрим, каким образом осуществляется проверка этих свойств остаточной последовательности.
Проверка случайности колебаний уровней остаточной последовательности означает проверку гипотезы о правильности выбора вида тренда. Для исследования случайности отклонений от тренда мы располагаем набором разностей

Характер этих отклонений изучается с помощью ряда непараметрических критериев. Одним из таких критериев является критерий серий,основанный на медиане выборки. Ряд из величин е, располагают в порядке возрастания их значений и находят медиану εт полученного вариационного ряда, т.е. срединное значение при нечетном п, или среднюю арифметическую из двух срединных значений, при п четном. Возвращаясь к исходной последовательности εt и сравнивая значения этой последовательности с εт, будем ставить знак "плюс", если значениеεt превосходит медиану, и знак "минус", если оно меньше медианы; в случае равенства сравниваемых величин соответствующее значение εtопускается. Таким образом, получается последовательность, состоящая из плюсов и минусов, общее число которых не превосходит п.Последовательность подряд идущих плюсов или минусов называется серией. Для того чтобы последовательность е, была случайной выборкой, протяженность самой длинной серии не должна быть слишком большой, а общее число серий - слишком малым.
Обозначим протяженность самой длинной серии через Кmax, а общее число серий - через ν. Выборка признается случайной, если выполняются следующие неравенства для 5%-ного уровня значимости:

 (5.8)
(5.8)
где квадратные скобки означают целую часть числа.
Если хотя бы одно из этих неравенств нарушается, то гипотеза о случайном характере отклонений уровней временного ряда от тренда отвергается и, следовательно, трендовая модель признается неадекватной.
Другим критерием для данной проверки может служить критерий пиков (поворотных точек). Уровень последовательности εt считается максимумом, если он больше двух рядом стоящих уровней, т.е. εt-1 < εt > εt+1, и минимумом, если он меньше обоих соседних уровней, т.е. εt-1 >εt < εt+1. В обоих случаях εt считается поворотной точкой; общее число поворотных точек для остаточной последовательности εt обозначим через р. В случайной выборке математическое ожидание числа точек поворота р и дисперсия σ2р выражаются формулами:

Критерием случайности с 5%-ным уровнем значимости, т.е. с доверительной вероятностью 95%, является выполнение неравенства
 (5.9)
(5.9)
где квадратные скобки означают целую часть числа. Если это неравенство не выполняется, трендовая модель считается неадекватной.
16)) Основные характеристики описательной статистики, анализ и выводы на их основе, вычисления в ППП STATISTICA.
Система «STATISTICA», разработанная компанией StatSoft, является одной из наиболее популярных статистических программ для поиска закономерностей, прогнозирования, классификации, визуализации данных. Может применяться в экономике, промышленности, медицине, научных исследованиях и других сферах человеческой деятельности. Клиентами StatSoft являются крупнейшие компании с мировым именем. В системе существует возможность проводить классические и новейшие методы проведения анализа данных: кластерный, факторный, корреляционный, дисперсионный анализ, линейную и нелинейную регрессии, нейронные сети и др. Визуализация исходных, промежуточных, выходных данных может быть осуществлена выбором из большого числа различных графиков, пиктографиков и диаграмм
Создание файлов данных Для создания файла, содержащего таблицу 1´50
1. выберите команду: File - New Data –
2. укажите имя файла в окне File Name : (например) descript - OK. На экране появится сетка-таблица вновь созданного файла descrip.stat; в заголовке таблицы будут указаны название и размеры по умолчанию: 10v * 10c - ( 10 переменных ( variables ) - столбцов по 10 наблюдений ( cases ) - строк.
3. преобразуем таблицу к размерам 1´50: Для этого, в строке меню щелкнем по кнопке Vars и выбирем комнаду- Delete; окно Delete Variables: укажем какие переменные- столбцы убрать : From variable : var 2, To variable : var 10 - OK По кнопке Cases в строке меню выберем команду Add ( добавление ) - окно Add Cases: укажем, сколько строк добавить и куда : Number of Cases to Add : 40, Insert after Case : 1 ( например ) - OK.
Если данных не много, то можно вводить их с клавиатуры, но большие таблицы данных лучше копировать с Microsoft Excel.
Замечание: Не стоит забывать, что в пакете STATISTICA 6.0 можно производить непосредственные расчеты в ячейках таблица, также как в Microsoft Excel.
Сохранение файла данных. Для сохранения созданного файла нажмите мышью на панели управления кнопку  Сохранить либо наберите на клавиатуре CTRL+S. Созданный файл сохранится и всегда будет доступен.
Сохранить либо наберите на клавиатуре CTRL+S. Созданный файл сохранится и всегда будет доступен.
17)) Создание файлов данных. Элементы описательной статистики в ППП STATISTICA
Создание файлов данных Для создания файла, содержащего таблицу 1´50
4. выберите команду: File - New Data –
5. укажите имя файла в окне File Name : (например) descript - OK. На экране появится сетка-таблица вновь созданного файла descrip.stat; в заголовке таблицы будут указаны название и размеры по умолчанию: 10v * 10c - ( 10 переменных ( variables ) - столбцов по 10 наблюдений ( cases ) - строк.
6. преобразуем таблицу к размерам 1´50: Для этого, в строке меню щелкнем по кнопке Vars и выбирем комнаду- Delete; окно Delete Variables: укажем какие переменные- столбцы убрать : From variable : var 2, To variable : var 10 - OK По кнопке Cases в строке меню выберем команду Add ( добавление ) - окно Add Cases: укажем, сколько строк добавить и куда : Number of Cases to Add : 40, Insert after Case : 1 ( например ) - OK.
Если данных не много, то можно вводить их с клавиатуры, но большие таблицы данных лучше копировать с Microsoft Excel.
Замечание: Не стоит забывать, что в пакете STATISTICA 6.0 можно производить непосредственные расчеты в ячейках таблица, также как в Microsoft Excel.
Сохранение файла данных. Для сохранения созданного файла нажмите мышью на панели управления кнопку Сохранить либо наберите на клавиатуре CTRL+S. Созданный файл сохранится и всегда будет доступен.
«STATISTICA 8.0»
Данные для обработки вносятся в табличном виде как случаи (cases) и переменные (variables). Cлучаи представляют собой строки заполняемой таблицы данных (spreadsheet). Таблицы данных можно импортировать, изменять, сохранять и экспортировать для работы в других программных пакетах.
Каждый случай таблицы данных характеризуется набором параметров. Номера случаев представляются в соответствующем столбце данных, значения параметров для каждого случая — в соответствующих пронумерованных столбцах таблицы, неактивная область переменных обозначена темно-серым цветом.
Для удобства рассмотрения возможностей «Statistica» по расчету параметров описательной статистики создадим таблицу данных для 100 случаев, по 2 параметра для каждого, пусть это будут, например, рост и вес. Чтобы создать таблицу данных нажмем File – New и в открывшейся форме Create New Document зададим значения соответствующих полей: Number of variables – 2 и Number of cases – 100. Жмем ОК. Получим пустую таблицу 2 × 100.
Изменим названия переменных, для чего сделаем двойной щелчок левой кнопкой на имени переменной var1. Откроется форма Variable 1, в ней в поле name введем значение «Рост», нажмем ОК. Название переменной изменится на «Рост».
Программа «Statistica» поставляется в виде набора модулей для анализа, который может сильно варьировать в зависимости от версии и типа лицензии. Модуль описательной статистики входит в «базовый набор» и содержится во всех версиях. Для того чтобы запустить данный модуль нажмем Statistica – Basic Statistics/Tables. Откроется форма Basics Statistics/Tables: Spreadsheet1, в которой сделаем двойной щелчок на пункте списка Descriptive Statistics. В результате проведенных манипуляций будет запущена форма модуля описательной статистики. Перейдем на вкладку Advanced.
Проставим галочки напротив рассмотренных ранее параметров описательной статистики, которые могут быть использованы для описания количественных данных. Теперь следует выбрать переменные, по которым будут производиться расчеты: нажмем кнопку Variables. Откроется форма диалога выбора переменных Select variables for analysis. В открывшейся форме удерживая клавишу ctrl щелчком левой кнопки мыши выделим «Рост» и «Вес», после чего жмем ОК
Чтобы произвести расчеты параметров описательной статистики нажмем Summary. Вывод данных в программе Statistica осуществляется в так называемые рабочие книги (workbook). В рабочих книгах приведены данные о результатах расчетов, в них же выводятся графики и результаты статистических тестов. Рабочие книги можно сохранять, изменять и экспортировать для повторного использования в других программах. В данном конкретном случае мы получим рабочую книгу с названием Workbook1
18)) Представление многомерных данных в пакете STATISTICA Стандартизация данных.
Многомерные статистические методы среди множества возможных вероятностно-статистических моделей позволяют обоснованно выбрать ту, которая наилучшим образом соответствует исходным статистическим данным, характеризующим реальное поведение исследуемой совокупности объектов, оценить надежность и точность выводов, сделанных на основании ограниченного статистического материала.
Социально-экономические процессы и явления зависят от большого числа параметров, их характеризующих, что обуславливает трудности, связанные с выявлениемструктуры взаимосвязей этих параметров. В подобных ситуациях, т.е. когда решения принимаются на основании анализа стохастической, неполной информации,использование методов многомерного статистического анализа является не толькооправданным, но и существенно необходимым.
Многомерные статистические методы среди множества возможных вероятностно-статистических моделей позволяют обоснованно выбрать ту, которая наилучшим образомсоответствует исходным статистическим данным, характеризующим реальное поведение исследуемой совокупности объектов, оценить надежность и точность выводов, сделанных на основании ограниченного статистического материала.
К области приложения математической статистики могут быть отнесены задачи, связанные с исследованием поведения индивидуума, семьи или другой социально-экономической или производственной единицы, как представителя большой совокупностиобъектов.
Многомерный экономико-статистический анализ опирается на широкий спектр методов. В учебном пособии рассматриваются некоторые из наиболее используемых методов, а именно: факторный, кластерный и дискриминантный анализы.
Методы многомерной классификации, которые предназначены разделять рассматриваемые совокупности объектов, субъектов или явлений на группы в определенном смысле однородные. Необходимо учитывать, что каждый из рассматриваемых объектов характеризуется большим количеством разных и стохастически связанных признаков. Для решения столь сложных задач классификации применяют кластерный и дискриминантный анализ. Наличие множества исходных признаков, характеризующих процесс функционирования объектов, заставляет отбирать из них наиболее существенные и изучать меньший набор показателей. Чаще исходные признаки подвергаются некоторому преобразованию, которое обеспечивает минимальную потерю информации. Такое решение может быть обеспечено методами снижения размерности, куда относятся факторный анализ. Этот метод позволяет учитывать эффект существенной многомерности данных, дает возможность лаконичного и более простого объяснения многомерных структур. Вскрывает объективно существующие, непосредственно не наблюдаемые закономерности при помощи полученных факторов или главных компонент.
Это дает возможность достаточно просто и точно описать наблюдаемые исходные данные, структуру и характер взаимосвязей между ними. Сжатие информации получается за счет того, что число факторов или главных компонент – новых единиц измерения – используется значительно меньше, чем исходных признаков.
Все перечисленные методы наиболее эффективны при активном применении статистических пакетов прикладных программ. При помощи этих пакетов предоставляется возможным даже восстанавливать пропущенные данные и др. Стандартные статистические методы обработки данных включены в состав электронных таблиц, таких как Excel, Lotus 1-2-3, QuattroPro, и в математические пакеты общего назначения, например Mathсad. Но гораздо большими возможностями обладают специализированные статистические пакеты, позволяющие применять самые современные методы математической статистики для обработки данных. По официальным данным Международного статистического института, число статистических программных продуктов приближается к тысяче. Среди них есть профессиональные статистические пакеты, предназначенные для пользователей, хорошо знакомых с методами математической статистики, и есть пакеты, с которыми могут работать специалисты, не имеющие глубокой математической подготовки; есть пакеты отечественные и созданные зарубежными программистами; различаются программные продукты и по цене.
Среди программных средств данного типа можно выделить узкоспециализированные пакеты, в первую очередь статистические - STATISTICA, SPSS, STADIA, STATGRAPHICS, которые имеют большой набор статистических функций: факторный анализ, регрессионный анализ, кластерный анализ, многомерный анализ, критерии согласия и т. д. Данные программные продукты обычно содержат и средства для визуальной интерпретации полученных результатов: различные графики, диаграммы, представление данных на географической карте.
При анализе данных пользователю статистического программного пакета приходится выполнять вычисления широкого спектра статистик, передавать и преобразовывать данные для их анализа, а также представлять полученные результаты в наглядном виде. Поэтому при выборе того или иного статистического пакета, для сравнения пакетов, необходимо прежде всего обращать внимание на такие характеристики, как:
удобство управления данными (экспорт/импорт данных, их реструктуризация);
статистическое разнообразие (количество статистических модулей);
графические возможности (наличие встроенного графического редактора, возможность показа отдельных элементов графика, возможности экспорта графиков).
Кроме того, большое значение имеет удобство работы с пакетом, легкость его освоения (наличие встроенной системы помощи, руководства пользователя, степень удобства управления данными, результатами вычислений, таблицами и графиками), а также скорость произведения вычислений.
Существуют также нестатистические пакеты, решающие задачи классификации(PolyAnalyst, ДА-система, АРГОНАВТ, ЛОРЕГ, пакет ОТЭКС и разнообразные нейросетевые пакеты).
Основные понятия многомерной статистики (кратко). Случайные векторы. Нормальные случайные векторы. Линейные преобразования нормальных случайных векторов. Оценки максимального правдоподобия вектора средних и матрицы ковариаций нормального случайного вектора. Многомерное обобщение хи-квадрат распределения: распределение Вишарта (Wishart). Многомерное обобщение распределения Стьюдента: Т2-распределение Хотеллинга (Hotelling). Связь с распределением Фишера-Снедекора. Многомерный тест проверки гипотезы о равенстве средних заданным значениям. Расстояние Махаланобиса между двумя выборками. Распределение расстояния Махаланобиса. Проверка многомерной гипотезы о равенстве средних двух выборок. Общий принцип оптимального многомерного статистического теста – тест отношения правдоподобия. Теорема Вилкса (Wilk’s theorem). Примеры. Специфика многомерного случая. Вычислительные аспекты применения теста отношения правдоподобия. Процедура оптимизации отношения правдоподобия. Численная реализация. Достоинства и недостатки тестов отношения правдоподобия. Проблема выделения причины отклонения основной гипотезы. Альтернативный подход. Проекция многомерного случайного вектора на одномерные подпространства. Теорема Крамера-Вольда (Cramer-Wold). Проверка гипотезы для проекций. Общий вывод. Выделение направления уклонения наблюдений от основной гипотезы. Тест объединение-пересечение (Union-Intersection). Достоинства и недостатки. Вычислительные проблемы. Имитационное моделирование (метод Монте-Карло) как средство решения вычислительных проблем. Проверка гипотезы о равенстве средних для k независимых векторных выборок размерности p. Тест отношения правдоподобия (Λ-тест Вилкса). Тест Объединение-пересечение. Связь с анализом вариаций (дисперсионный анализ). Реализация тестов в компьютерных пакетах анализа данных. Преимущества системы MatLab.
19)) Определение и экономическая интерпретация коэффициентов корреляции и детерминация Построение корреляционной матрицы в пакете STATISTICA и её анализ, средствами пакета
Коэффициент корреляции - это корреляцинное отношение, математическая мера корреляции двух случайных величин. В случае, если изменение одной случайной величины не ведёт к закономерному изменению другой случайной величины, но приводит к изменению другой статистической характеристики данной случайной величины, то подобная связь не считаетсякорреляционной, хотя и является статистической.
Корреляция может быть положительной и отрицательной (возможна также ситуация отсутствия статистической взаимосвязи — например, для независимых случайных величин). Отрицательная корреляция — корреляция, при которой увеличение одной переменной связано с уменьшением другой переменной, при этом коэффициент корреляции отрицателен. Положительная корреляция — корреляция, при которой увеличение одной переменной связано с увеличением другой переменной, при этом коэффициент корреляции положителен.
Автокорреляция — статистическая взаимосвязь между случайными величинами из одного ряда, но взятых со сдвигом, например, для случайного процесса — со сдвигом по времени.
Метод обработки статистических данных, заключающийся в изучении коэффициентов (корреляции) между переменными, называется корреляционным анализом.
Коэффицие́нт корреля́ции или парный коэффицие́нт корреля́ции в теории вероятностей и статистике — это показатель характера изменения двух случайных величин. Коэффициент корреляции обозначается латинской буквой R и может принимать значения между -1 и +1. Если значение по модулю находится ближе к 1, то это означает наличие сильной связи (при коэффициенте корреляции равном единице говорят о функциональной связи), а если ближе к 0, то слабой.
|
из
5.00
|
Обсуждение в статье: Оценка адекватности и точности моделей |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы