 |
Главная |


Коэффициент корреляции Пирсона
|
из
5.00
|
Для метрических величин применяется коэффициент корреляции Пирсона, точная формула которого была введена Фрэнсисом Гальтоном:
Пусть X,Y — две случайные величины, определённые на одном вероятностном пространстве. Тогда их коэффициент корреляции задаётся формулой:
где cov обозначает ковариацию, а D — дисперсию, или, что то же самое,
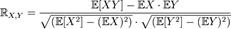
, где символ 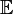 обозначает математическое ожидание.
обозначает математическое ожидание.
Для графического представления подобной связи можно использовать прямоугольную систему координат с осями, которые соответствуют обеим переменным. Каждая пара значений маркируется при помощи определенного символа. Такой график называется «диаграммой рассеяния».
Коэффициент детерминации:
Статистический показатель, отражающий объясняющую способность уравнения регрессии и равный отношению суммы квадратов регрессии SSR к общей вариацииSST:
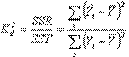 ,
,
где  – уровень ряда,
– уровень ряда,  – смоделированное значение,
– смоделированное значение,  – среднее по всем уровням ряда.
– среднее по всем уровням ряда.
Данный показатель является статистической мерой согласия, с помощью которой можно определить, насколько уравнение регрессии соответствует реальным данным.
Коэффициент детерминации изменяется в диапазоне от 0 до 1. Если он равен 0, это означает, что связь между переменными регрессионной модели отсутствует, и вместо нее для оценки значения выходной переменной можно с таким же успехом использовать простое среднее ее наблюдаемых значений. Напротив, если коэффициент детерминации равен 1, это соответствует идеальной модели, когда все точки наблюдений лежат точно на линии регрессии, т.е. сумма квадратов их отклонений равна 0. На практике, если коэффициент детерминации близок к 1, это указывает на то, что модель работает очень хорошо (имеет высокую значимость), а если к 0, то это означает низкую значимость модели, когда входная переменная плохо "объясняет" поведение выходной, т.е. линейная зависимость между ними отсутствует. Очевидно, что такая модель будет иметь низкую эффективность.
Эта процедура предназначена для проведения корреляционного анализа, установления тесноты линейной связи между переменными.
Установим тесноту взаимосвязей между таксационными показателям дубовых древостоев. Фрагмент окна файла данных представлен на рис. 14. Данные представляют собой таксационные показатели древостоев 93 пробных площадей, заложенных в низкоствольных дубравах 4 класса бонитета. По названию переменных понятно какие таксационные показатели они содержат.
В стартовом окне этой процедуры "Pearson Product-Moment Correla-tion" (Корреляция Пирсона) (рис. 15) для расчета квадратной матрицы используется кнопка One variable list (square matrix).
В списке переменных выбирают переменные, между которыми будут рассчитаны парные коэффициенты корреляции Пирсона. После нажатия на кнопку OK или Correlationes на экране появится корреляционная матрица (рис. 16).
Процедура Correlation matrices сразу же дает возможность проверить достоверность рассчитанных коэффициентов корреляции. Значение коэффициента корреляции может быть высоким, но не достоверным, случайным. Чтобы увидеть вероятность нулевой гипотезы (p), гласящей о том что коэффициент корреляции равен 0, нужно в опции Display окна Pearson Product-Moment Correlation (рис. 15) установить переключатель на вторую строку Corr. matrix (display p & N). Но даже если этого не делать и оставить переключатель в первом положении Corr. matrix (highlight p), статистически значимые на 5-% уровне коэффициенты корреляции будут выделены в корреляционной матрице на экране монитора цветом, а при распечатке помечены звездочкой. Третье положение переключателя опции Display - Detail table of results позволяет просмотреть результаты корреляционного анализа в деталях (рис. 17). Флажок опции Casewise deletion of MD устанавливается для исключения из обработки всей строки файла данных, в которой есть хотя бы одно пропущенное значение.
20)) Многомерный регрессионный анализ в пакете STATISTICA: Определение коэффициентов уравнения регрессии, оценка адекватности уравнения и оценка параметров и остатков
Коэффициенты регрессии показывают интенсивность влияния факторов на результативный показатель. Если проведена предварительная стандартизация факторных показателей, то b0 равняется среднему значению результативного показателя в совокупности. Коэффициенты b1, b2, ..., bn показывают, на сколько единиц уровень результативного показателя отклоняется от своего среднего значения, если значения факторного показателя отклоняются от среднего, равного нулю, на одно стандартное отклонение. Таким образом, коэффициенты регрессии характеризуют степень значимости отдельных факторов для повышения уровня результативного показателя. Конкретные значения коэффициентов регрессии определяют по эмпирическим данным согласно методу наименьших квадратов (в результате решения систем нормальных уравнений).
Аналитические достоинства регрессионных моделей заключаются в том, что, во-первых, точно определяется фактор, по которому выявляются резервы повышения результативности хозяйственной деятельности; во-вторых, выявляются объекты с более высоким уровнем эффективности; в-третьих, возникает возможность количественно измерить экономический эффект от внедрения передового опыта, проведения организационно-технических мероприятий.
Рассмотрим пример построения регрессионной модели в пакете Statistica 6.0. Для этих целей обычно используется модуль Multiple Regressions (Множественная регрессия), который позволяет предсказать зависимую переменную по нескольким независимым переменным. В стартовом диалоговом окне этого модуля (рис.1) при помощи кнопки Variables указываются зависимая (dependent) и независимые(ая) (independent) переменные. В поле Input file указывается тип файла с данными: Raw Data - данные в виде строчной таблицы; Correlation Matrix - данные в виде корреляционнойматрицы.
В поле MD deletion указывается способ исключения из обработки недостающих данных: Casewise - игнорируется вся строка, в которой есть хотя бы одно пропущенное значение; Mean Substitution - взамен пропущенных данных подставляются средние значения переменной; Pairwise - попарное исключение данных с пропусками из тех переменных, корреляция которых вычисляется.
На первом этапе исследований учтем, что при наличии одной зависимой переменной (rost) и двух независимых переменных (vozrast и rost) можно предложить различные модели линейной регрессии: № Модели Вид зависимости Комментарии 1 rost= одномерная 2 rost= одномерная 3 rost= многомерная О качестве предложенной модели регрессии будем судить по величине коэффициента детерминации.
После выбора всех опций стартового диалогового окна регрессионного анализа и нажатия кнопки ОК появляется окно результатов регрессионного анализа Multiple Regressions Results (см. рис. 4). Детально проанализируем полученные результаты регрессионной модели. В верхней части окна приведены наиболее важные параметры полученной регрессионной модели: Multiple R - коэффициент множественной корреляции, который характеризует тесноту линейной связи между зависимой и всеми независимыми переменными. Может принимать значения от 0 до 1. - коэффициент детерминации. Численно выражает долю вариации зависимой переменной, объясненную с помощью регрессионного уравнения. Чем больше , тем большую долю вариации объясняют переменные, включенные в модель. adjusted R - скорректированный коэффициент множественной корреляции. Включение новой переменной в регрессионное уравнение увеличивает не всегда, а только в том случае, когда частный F-критерий при проверке гипотезы о значимости включаемой переменной больше или равен 1. В противном случае включение новой переменной уменьшает значение и adjusted R.
F - F-критерий используется для проверки значимости регрессии. В данном случае в качестве нулевой гипотезы проверяется гипотеза: между зависимой и независимыми переменными нет линейной зависимости; df - числа степеней свободы для F-критерия; p - вероятность нулевой гипотезы для F-критерия; Standard error of estimate - стандартная ошибка оценки (уравнения); Эта оценка является мерой рассеяния наблюденных значений относительно регрессионной прямой; Intercept – оценка свободного члена уравнения; Std.Error - стандартная ошибка оценки свободного члена уравнения; t - t-критерий для оценки свободного члена уравнения; p - вероятность нулевой гипотезы для свободного члена уравнения. Beta - β-коэффициенты уравнения. Это стандартизированные регрессионные коэффициенты, рассчитанные по стандартизированным значениям переменных. По их величине можно оценить значимость зависимых переменных. Коэффициент показывает, на сколько единиц стандартного отклонения изменится зависимая переменная при изменении на одно стандартное отклонение независимой переменной, при условии постоянства остальных независимых переменных. Свободный член в таком уравнении равен 0.
Проверка качества уравнения регрессии осуществлялась с помощью статистики . По статистическим таблицам Фишера – Снедекора с данными степенями свободы гипотезу (линейная зависимость отсутствует) можно принять с вероятностью ; при уровне значимости α = 0.05 принимаем альтернативную гипотезу – линейная зависимость значима. Одновременно проверялась статистическая значимость коэффициентов множественной регрессии (критерий Стьюдента). Видно (см. рис. 5), что коэффициенты и значимо отличаются от нуля, коэффициент незначимо отличается от нуля.
В таблицу включены все случаи (м), приведены исходные данные (Observed), данные модели (Predicted) и остатки (Residual). Остатки – это разность исходных и предсказанных данных.
21)) Понятие кластерного анализа и области его применения
Термин кластерный анализ, впервые введенный Трионом (Tryon) в 1939 году, включает в себя более 100 различных алгоритмов. В отличие от задач классификации, кластерный анализ не требует априорных предположений о наборе данных, не накладывает ограничения на представление исследуемых объектов, позволяет анализировать показатели различных типов данных (интервальным данным, частотам, бинарным данным). При этом необходимо помнить, что переменные должны измеряться в сравнимых шкалах. Кластерный анализ позволяет сокращать размерность данных, делать ее наглядной. Кластерный анализ может применяться к совокупностям временных рядов, здесь могут выделяться периоды схожести некоторых показателей и определяться группы временных рядов со схожей динамикой. Кластерный анализ параллельно развивался в нескольких направлениях, таких как биология, психология, др., поэтому у большинства методов существует по два и более названий. Это существенно затрудняет работу при использовании кластерного анализа.
Задачи кластерного анализа можно объединить в следующие группы:
1. Разработка типологии или классификации.
2. Исследование полезных концептуальных схем группирования объектов.
3. Представление гипотез на основе исследования данных.
4. Проверка гипотез или исследований для определения, действительно ли типы (группы), выделенные тем или иным способом, присутствуют в имеющихся данных.
Как правило, при практическом использовании кластерного анализа одновременно решается несколько из указанных задач. Критерием для определения схожести и различия кластеров является расстояние между точками на диаграмме рассеивания. Это сходство можно "измерить", оно равно расстоянию между точками на графике. Способов определения меры расстояния между кластерами, называемой еще мерой близости, существует несколько. Наиболее распространенный способ - вычисление евклидова расстояния между двумя точками i и j на плоскости, когда известны их координаты X и Y:
 (1)
(1)
Когда осей больше, чем две, расстояние рассчитывается таким образом: сумма квадратов разницы координат состоит из стольких слагаемых, сколько осей (измерений) присутствует в нашем пространстве. Например, если нам нужно найти расстояние между двумя точками в пространстве трех измерений), формула (1) приобретает вид:
 (2) в пространстве трех измерений
(2) в пространстве трех измерений
Кластер имеет следующие математические характеристики: центр, радиус, среднеквадратическое отклонение, размер кластера
Центр кластера - это среднее геометрическое место точек в пространстве переменных.
Радиус кластера - максимальное расстояние точек от центра кластера
Как было отмечено в одной из предыдущих лекций, кластеры могут быть перекрывающимися. Такая ситуация возникает, когда обнаруживается перекрытие кластеров. В этом случае невозможно при помощи математических процедур однозначно отнести объект к одному из двух кластеров. Такие объекты называют спорными
Спорный объект - это объект, который по мере сходства может быть отнесен к нескольким кластерам
Размер кластера может быть определен либо по радиусу кластера, либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера. Если это условие выполняется для двух и более кластеров, объект является спорным
- Работа кластерного анализа опирается на два предположения. Первое предположение - рассматриваемые признаки объекта в принципе допускают желательное разбиение пула (совокупности) объектов на кластеры. В начале лекции мы уже упоминали о сравнимости шкал, это и есть второе предположение - правильность выбора масштаба или единиц измерения признаков. Выбор масштаба в кластерном анализе имеет большое значение. Рассмотрим пример. Представим себе, что данные признака х в наборе данных А на два порядка больше данных признака у: значения переменной х находятся в диапазоне от 100 до 700, а значения переменной у - в диапазоне от 0 до 1. Тогда, при расчете величины расстояния между точками, отражающими положение объектов впространстве их свойств, переменная, имеющая большие значения, т.е. переменная х, будет практически полностью доминировать над переменной с малыми значениями, т.е. переменной у. Таким образом, из-за неоднородности единиц измерения признаков становится невозможно корректно рассчитать расстояния между точками. Эта проблема решается при помощи предварительной стандартизации переменных. Стандартизация (standardization) или нормирование (normalization) приводит значения всех преобразованных переменных к единому диапазону значений путем выражения через отношение этих значений к некой величине, отражающей определенные свойства конкретного признака. Существуют различные способы нормирования исходных данных. Два наиболее распространенных способа:
- деление исходных данных на среднеквадратичное отклонение соответствующих переменных;
- вычисление Z-вклада или стандартизованного вклада.
Наряду со стандартизацией переменных, существует вариант придания каждой из них определенного коэффициента важности, или веса, который бы отражал значимость соответствующей переменной. В качестве весов могут выступать экспертные оценки, полученные в ходе опроса экспертов - специалистов предметной области. Полученные произведения нормированных переменных на соответствующие веса позволяют получать расстояния между точками в многомерном пространстве с учетом неодинакового веса переменных.
В ходе экспериментов возможно сравнение результатов, полученных с учетом экспертных оценок и без них, и выбор лучшего из них.
Методы кластерного анализа можно разделить на две группы:
- иерархические;
- неиерархические.
Каждая из групп включает множество подходов и алгоритмов.
Используя различные методы кластерного анализа, аналитик может получить различные решения для одних и тех же данных. Это считается нормальным явлением. Рассмотрим иерархические и неиерархические методы подробно.
Иерархические методы кластерного анализа
|
из
5.00
|
Обсуждение в статье: Коэффициент корреляции Пирсона |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы