 |
Главная |


Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA)
|
из
5.00
|
Эти методы являются логической противоположностью агломеративным методам. В начале работы алгоритма все объекты принадлежат одному кластеру, который на последующих шагах делится на меньшие кластеры, в результате образуется последовательность расщепляющих групп.
Иерархические методы кластеризации различаются правилами построения кластеров. В качестве правил выступают критерии, которые используются при решении вопроса о "схожести" объектов при их объединении в группу (агломеративные методы) либо разделения на группы (дивизимные методы).
Иерархические методы кластерного анализа используются при небольших объемах наборов данных. Преимуществом иерархических методов кластеризации является их наглядность.
Иерархические алгоритмы связаны с построением дендрограмм (от греческого dendron - "дерево"), которые являются результатом иерархического кластерного анализа. Дендрограмма описывает близость отдельных точек и кластеров друг к другу, представляет в графическом виде последовательность объединения (разделения) кластеров.
22)) Основные способы определения расстояний между объектами. Методы разбиения на кластеры
В системах распознавания образов и классификации соответствующий класс задач обучения без учителя получил название кластер анализа (т.е. самопроизвольного разбиения исходной выборки на компактные полмножества, или кластеры). Пусть задано множество наблюдений  , где
, где  . Требуется разбить выборку
. Требуется разбить выборку  кластеры — на непересекающиеся подмножества
кластеры — на непересекающиеся подмножества  так, чтобы обеспечить минимум (экстремум) некоторого критерия (функционала качества), то есть:
так, чтобы обеспечить минимум (экстремум) некоторого критерия (функционала качества), то есть:
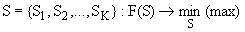
Если эти данные понимать как точки в признаковом пространстве, то задача кластерного анализа формулируется как выделение "сгущений точек" и разбиение исходной совокупности на однородные подмножества объектов. Кластерный анализ можно рассматривать также как метод редукции (сжатия) некоторого множества данных в более компактную классификацию объектов.
Рассмотрим некоторые алгоритмы, основанные на использовании меры расстояния между объектами D. Введение метрики m–мерного пространства (т.е. способа оценки расстояний) является естественным приемом квантификации свойства схожести объектов: чем ближе между собой объекты в данной метрике, тем они более сходны и наоборот. Без этого само понятие "кластер" во многом теряет смысл, поэтому алгоритмы кластерного анализа часто формулируют в терминах дистанций.
Был предпринят ряд попыток разработать аксиоматический подход к введению метрических мер, согласно которым, например, расстоянием Dназывается двухместная действительная функция D(x1, x2), обладающая следующими свойствами:
- D(x1, x2)≠0неотрицательная определенность расстояния (хотя тот же коэффициент корреляции Пирсона принимает и отрицательные значения); —
- D(x1, x2)=0 тогда и только тогда, когда x1=x2неразличимость тождественных объектов; —
- D(x1, x2)=D(x2, x1)симметричность расстояния; —
- D(x1, x2)+D(x2, x3)≠D(x1, x3)неравенство треугольника (длина любой стороны треугольника не больше суммы длин двух оставшихся). —
Более конкретная математическая формулировка не имеет однозначного смысла, поскольку разные субъекты вкладывают в эту аксиоматику неодинаковое содержание.
Естественно попытаться определить сравнительное качество различных способов разбиения заданной совокупности элементов на классы, т. е. определить тот количественный критерий, следуя которому можно было бы предпочесть одно разбиение другому.
С этой целью в постановку задачи кластер-анализа часто вводится понятие так называемого функционала качества разбиения  , определенного на множестве всех возможных разбиений. Функционалом он называется потому, что чаще всего разбиение S задается, вообще говоря, набором дискриминантных функций
, определенного на множестве всех возможных разбиений. Функционалом он называется потому, что чаще всего разбиение S задается, вообще говоря, набором дискриминантных функций  . Тогда под наилучшим разбиением S понимается то разбиение, на котором достигается экстремум выбранного функционала качества. Выбор того или иного функционала качества, как правило, осуществляется весьма произвольно и опирается скорее на эмпирические и профессионально-интуитивные соображения, чем на какую-либо строгую формализованную систему.
. Тогда под наилучшим разбиением S понимается то разбиение, на котором достигается экстремум выбранного функционала качества. Выбор того или иного функционала качества, как правило, осуществляется весьма произвольно и опирается скорее на эмпирические и профессионально-интуитивные соображения, чем на какую-либо строгую формализованную систему.
Приведем примеры наиболее распространенных функционалов качества разбиения и попытаемся обосновать выбор некоторых из них в рамках одной из моделей статистического оценивания параметров.
23))Математические характеристики кластера
Кластер имеет следующие математические характеристики: центр, радиус, среднеквадратическое отклонение, размер кластера
Центр кластера - это среднее геометрическое место точек в пространстве переменных.
Радиус кластера - максимальное расстояние точек от центра кластера
Как было отмечено в одной из предыдущих лекций, кластеры могут быть перекрывающимися. Такая ситуация возникает, когда обнаруживается перекрытие кластеров. В этом случае невозможно при помощи математических процедур однозначно отнести объект к одному из двух кластеров. Такие объекты называют спорными
Спорный объект - это объект, который по мере сходства может быть отнесен к нескольким кластерам
Размер кластера может быть определен либо по радиусу кластера, либо по среднеквадратичному отклонению объектов для этого кластера. Объект относится к кластеру, если расстояние от объекта до центра кластера меньше радиуса кластера. Если это условие выполняется для двух и более кластеров, объект является спорным
· Работа кластерного анализа опирается на два предположения. Первое предположение - рассматриваемые признаки объекта в принципе допускают желательное разбиение пула (совокупности) объектов на кластеры. В начале лекции мы уже упоминали о сравнимости шкал, это и есть второе предположение - правильность выбора масштаба или единиц измерения признаков. Выбор масштаба в кластерном анализе имеет большое значение. Рассмотрим пример. Представим себе, что данные признака х в наборе данных А на два порядка больше данных признака у: значения переменной х находятся в диапазоне от 100 до 700, а значения переменной у - в диапазоне от 0 до 1. Тогда, при расчете величины расстояния между точками, отражающими положение объектов впространстве их свойств, переменная, имеющая большие значения, т.е. переменная х, будет практически полностью доминировать над переменной с малыми значениями, т.е. переменной у. Таким образом, из-за неоднородности единиц измерения признаков становится невозможно корректно рассчитать расстояния между точками. Эта проблема решается при помощи предварительной стандартизации переменных. Стандартизация (standardization) или нормирование (normalization) приводит значения всех преобразованных переменных к единому диапазону значений путем выражения через отношение этих значений к некой величине, отражающей определенные свойства конкретного признака. Существуют различные способы нормирования исходных данных. Два наиболее распространенных способа:
- деление исходных данных на среднеквадратичное отклонение соответствующих переменных;
- вычисление Z-вклада или стандартизованного вклада.
Наряду со стандартизацией переменных, существует вариант придания каждой из них определенного коэффициента важности, или веса, который бы отражал значимость соответствующей переменной. В качестве весов могут выступать экспертные оценки, полученные в ходе опроса экспертов - специалистов предметной области. Полученные произведения нормированных переменных на соответствующие веса позволяют получать расстояния между точками в многомерном пространстве с учетом неодинакового веса переменных
В ходе экспериментов возможно сравнение результатов, полученных с учетом экспертных оценок и без них, и выбор лучшего из них.
Методы кластерного анализа можно разделить на две группы:
- иерархические;
- неиерархические.
Каждая из групп включает множество подходов и алгоритмов.
Используя различные методы кластерного анализа, аналитик может получить различные решения для одних и тех же данных. Это считается нормальным явлением.
Рассмотрим иерархические и неиерархические методы подробно.
Метод Варда (Ward's method). В качестве расстояния между кластерами берется прирост суммы квадратов расстояний объектов до центров кластеров, получаемый в результате их объединения (Ward, 1963). В отличие от других методов кластерного анализа для оценки расстояний между кластерами, здесь используются методы дисперсионного анализа. На каждом шаге алгоритма объединяются такие два кластера, которые приводят к минимальному увеличению целевой функции, т.е. внутригрупповой суммы квадратов. Этот метод направлен на объединение близко расположенных кластеров и "стремится" создавать кластеры малого размера.
|
из
5.00
|
Обсуждение в статье: Иерархические дивизимные (делимые) методы (DIvisive ANAlysis, DIANA) |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы