 |
Главная |


Раздел 2. Логическое программирование
|
из
5.00
|
Лабораторная работа № 4.ЯЗЫК ЛОГИКИ ПРЕДИКАТОВ
Рассмотрим некоторую формальную систему, включающую:
1. алфавит системы — счетное множество символов;
2. формулы системы — некоторое подмножество всех слов, которые можно образовать из символов, входящих в алфавит;
3. аксиомы системы — выделенное множество формул системы;
4. правила вывода системы — конечное множество отношений между формулами системы.
Зададим логику первого порядка, на которой основывается Пролог, являющегося одним из формальных языков, наиболее приближенных к человеческому языку. Рассмотрим алфавит логики первого порядка, включающий:
1. переменные (будем обозначать u, v, x, y, z);
2. константы (будем обозначать a, b, c, d);
3. функциональные символы (используем для их обозначения буквы f и g);
4. предикатные символы (обозначим p, q и r);
5. пропозициональные константы истина и ложь (true и false);
6. логические связки: (отрицание), ∧ (конъюнкция), ∨ (дизъюнкция), → (импликация);
7. кванторы:∃ (существования),∀ (всеобщности);
8. вспомогательные символы (, ), !, [, ] ;.
Всякий предикатный и функциональный символ имеет определенное число аргументов. Если предикатный или функциональный символ имеет n аргументов, он называется n-местным предикатным (функциональным) символом.
Термом будем называть выражение, образованное из переменных и констант, возможно, с применением функций, а точнее:
1. всякая переменная или константа есть терм;
2. если t1,...,tn - термы, а f - n-местный функциональный символ,то f(t1,...,tn) - терм;
3. других термов нет.
Все объекты в программе на Прологе представляются именно в виде термов. Если терм не содержит переменных, то он называется основным или константным термом.
Атомная или элементарная формула p(t1,...,tn)получается путем применения предиката к термам, где p - n-местный предикатный символ, а t1,...,tn - термы.
Формулы логики первого порядка соответствуют следующим условиям:
1. всякая атомная формула есть формула;
2. если A и B - формулы, а x — переменная, то выражения A, A∧B, A ∨ B, A→B, ∃хA и ∀xA - формулы;
3. других формул нет.
В случае если формула имеет вид ∀xA или ∃хA, ее подформула A называется областью действия квантора ∀x или ∃х соответственно. Если вхождение переменной x в формулу находится в области действия квантора ∀x или ∃х, то оно называется связанным вхождением. В противном случае вхождение переменной в формулу называется свободным.
Литералом будем называть атомную формулу или отрицание атомной формулы. Атом называется положительным литералом, а его отрицание - отрицательным литералом.
Дизъюнкт - это дизъюнкция конечного числа литералов. Если дизъюнкт не содержит литералов, его называют пустым дизъюнктом и обозначают посредством символа ℵ.
Рассмотрим каким образом формула приводится к множеству дизъюнктов, с которым работает метод резолюций. Для этого введем некоторые определения нормальных форм.
Говорят, что формула находится в конъюнктивной нормальной форме,если это конъюнкция конечного числа дизъюнктов. Имеет место теорема о том, что для любой бескванторной формулы существует формула, логически эквивалентная исходной и находящаяся в конъюнктивной нормальной форме.
Формула находится в предваренной (или пренексной) нормальной форме, если она представлена в виде Q1x1,...,QnxnA, где Qi - это квантор ∀ или ∃, а формула A не содержит кванторов. Выражение Q1x1,...,Qnxn называют префиксом, а формулу A - матрицей.
Формула находится в сколемовской нормальной форме, если она находится в предваренной нормальной форме и не содержит кванторов существования.
Для применения метода резолюций множество формул необходимо привести к множеству дизъюнктов. Рассмотрим алгоритм.
Шаг 1. Приводим исходную формулу к предваренной нормальной форме. Для этого:
1. пользуясь эквивалентностью A → B ≡ A ∨ B исключим импликацию;
2. перенесем все отрицания внутрь формулы, чтобы они стояли только перед атомными формулами, используя следующие эквивалентности:
· (A ∨ B) ≡ A ∧ B
· (A ∧ B) ≡ A ∨ B
· (∃xA) ≡ ∀xA
· (∀xA) ≡ ∃xA
· A ≡ A
3. переименовываем связанные переменные так, чтобы ни одна переменная не входила в нашу формулу одновременно связанно и свободно;
4. выносим кванторы в начало формулы, используя эквивалентности:
· QxA(x) ∨ B ≡ Qx(A(x) ∨ B), если B не содержит переменной x, а Q ∈ {∀, ∃}
· QxA(x) ∧ B ≡ Qx(A(x) ∧ B), если B не содержит переменной x, а Q ∈ {∀, ∃}
· ∀xA(x) ∧ ∀xB(x) ≡ ∀x(A(x) ∧ B(x))
· ∃xA(x) ∨ ∃xB(x) ≡ ∃x(A(x) ∨ B(x))
· Q1xA(x) ∨ Q2xB ≡ Q1xQ2y(A(x) ∨ B(y)), где Q∈{∀,∃}
· Q1xA(x) ∧ Q2xB ≡ Q1xQ2y(A(x) ∧ B(y)), где Q∈{∀,∃}.
Шаг 2. Приводим преобразованную формулу к сколемовской нормальной форме. Для этого для каждого квантора существования выполним следующие действия.
· Если устраняемый квантор существования — самый левый квантор в префиксе формулы, заменим все вхождения в формулу переменной, связанной этим квантором, на новую константу и вычеркнем квантор из префикса формулы.
· Если левее этого квантора существования имеются кванторы всеобщности, заменим все вхождения в формулу переменной, связанной этим квантором, на новый функциональный символ от переменных, которые связаны левее стоящими кванторами всеобщности, и вычеркнем квантор из префикса формулы.
Шаг 3. Элиминируем кванторы всеобщности.
Четвертый шаг. Приведем формулу к конъюнктивной нормальной форме, для чего воспользуемся эквивалентностями, выражающими дистрибутивность:
· A ∨ (B ∧ C) ≡ (A ∨ B) ∧ (A ∨ C)
· A ∧ (B ∨ C) ≡ (A ∧ B) ∨ (A ∧ C)
Пятый шаг. Элиминируем конъюнкции, представляя формулу в виде множества дизъюнктов.
Рассмотрим пример. Приведем формулу
∀x(P(x)→∃y(P(y)∨Q(x,y)))
в эквивалентное ей множество дизъюнктов.
Шаг 1. Приведем исходную формулу к предваренной нормальной форме. Элиминировав импликацию, получим формулу
∀x(P(x)∨∃y(P(y)∨Q(x,y))).
Вынесем переменную y за скобки: ∀x∃y(P(x)∨(P(y)∨Q(x,y))). Это можно сделать, потому что формула P(x) не зависит от переменной y. В противном случае требовалось бы переименование связанной переменной.
Второй шаг. Проведем сколемизацию полученной формулы. Левее квантора существования стоит квантор всеобщности, значит, нужно заменить все вхождения переменной y новым унарным функциональным символом, зависящим от x. Получим формулу, находящуюся в сколемовской нормальной форме:
∀x(P(x)∨(P(f(x)∨Q(x,f(x)))).
Третий шаг. Элиминируем квантор всеобщности:
P(x)∨(P(f(x))∨Q(x,f(x))).
В четвертом и пятом шагах необходимости нет, поскольку формула уже представляет собой дизъюнкт: P(x)∨P(f(x))∨Q(x,f(x)).
Доказательство теорем сводится к доказательству того, что некоторая формула G (гипотеза теоремы), является логическим следствием множества формул F1,...,Fk (допущений). Т.е. сам текст теоремы может быть сформулирован следующим образом "если F1,...,Fk истинны, то истинна и G". Такой метод доказательства теорем называется методом резолюций.
Как было показано ранее, задача о логическом следствии может быть сведена к задаче о выполнимости. Формула G есть логическое следствие формул F1,F2,...,Fk тогда и только тогда, когда множество формул {F1,F2,...,Fk,G} невыполнимо. Метод резолюций устанавливает невыполнимость такого множества формул. Робинсоном предложено, что правила вывода, используемые компьютером при автоматическом выводе, не обязательно должны совпадать с правилами вывода, используемыми при «человеческом» выводе. В частности, он предложил вместо правила вывода «modus ponens» использовать его обобщение, правило резолюции, которое эффективно реализуется на компьютере. Правило резолюции для логики высказываний можно сформулировать следующим образом.
Если для двух дизъюнктов существует атомная формула, которая в один дизъюнкт входит положительно, а в другой отрицательно, то, вычеркнув соответственно из одного дизъюнкта положительное вхождение атомной формулы, а из другого - отрицательное, и объединив эти дизъюнкты, мы получим дизъюнкт, называемый резольвентой. Исходные дизъюнкты в таком случае называются родительскими или резольвируемыми, а вычеркнутые формулы - контрарными литералами. Другими словами, резольвента - это дизъюнкт, полученный из объединения родительских дизъюнктов вычеркиванием контрарных литералов.
Это правило выгядет следующим образом:
(A ∨B, P ∨ P)/A ∨ B
Здесь A ∨ P и B ∨ P — родительские дизъюнкты, P и P — контрарные литералы, A ∨ B — резольвента.
Например, если первый дизъюнкт AÚ C, второй CÚ D, то резольвентой будет формула AÚ D. Если первый дизъюнкт состоит из одного литерала А, а второй из литерала A, т.е. родительские дизъюнкты состояли только из контрарных литералов то их резольвентой будет тождественно- ложный дизъюнкт - пустой дизъюнкт.
Введем понятие вывода. Пусть S - множество дизъюнктов. Выводом из S называется последовательность дизъюнктов D1,D2,...,Dn такая, что каждый дизъюнкт этой последовательности принадлежит S или следует из предыдущих по правилу резолюций. Дизъюнкт D выводим из S, если существует вывод из S, последним дизъюнктом которого является D.
Применение метода резолюций основано на следующем утверждении, которое называется теоремой о полноте метода резолюций.
Теорема. Множество дизъюнктов логики высказываний S невыполнимо тогда и только тогда, когда из S выводим пустой дизъюнкт.
Сам метод резолюций можно сформулировать таким образом.
Метод резолюций. Для доказательства того, что формула G является логическим следствием множества формул F1,...,Fk метод резолюций применяется следующим образом. Сначала составляется множество формул {F1,...,Fk, G}. Затем каждая из этих формул приводится к конъюнктивной нормальной форме (конъюнкция дизъюнктов) и в полученных формулах зачеркиваются знаки конъюнкции. Получается множество дизъюнктов S. И, наконец, ищется вывод пустого дизъюнкта из S. Если пустой дизъюнкт выводим из S, то формула G является логическим следствием формул F1,...,Fk. Если из S нельзя вывести ℵ, то G не является логическим следствием формул F1,...,Fk.
Рассмотрим пример доказательства методом резолюций. Пусть у нас есть следующие утверждения:
· "Яблоко красное и ароматное."
· "Если яблоко красное, то яблоко вкусное."
Докажем утверждение, что "яблоко вкусное".
Введем множество формул, описывающих простые высказывания, соответствующие вышеприведенным утверждениям. Пусть:
· X1 - "Яблоко красное."
· X2 - "Яблоко ароматное."
· X3 - "Яблоко вкусное."
Тогда сами утверждения можно зависать в виде формул.
· X1 & X2 - "Яблоко красное и ароматное."
· X1 → X3 - "Если яблоко красное, то яблоко вкусное."
Следовательно утверждение, которое надо доказать выражается формулой X3.
Докажем, что X3 является логическим следствием (X1 & X2) и (X1 → X3). Сначала составляем множество формул с отрицанием доказываемого высказывания; получаем {(X1 & X2), (X1 → X3), X3}.
Теперь приводим все формулы к конъюнктивной нормальной форме и зачеркиваем конъюнкции. Получаем следующее множество дизъюнктов:
{X1, X2, (X1 v X3), X3}.
Ищем вывод пустого дизъюнкта (в этом выводе третий и последний элементы получены по правилу резолюции, остальные являются элементами исходного множества дизъюнктов):
Резольвента X1 и (X1 v X3): X3
Резольвента X3 и X3: ℵ
Получили пустой дизъюнкт, значит утверждение о том, что яблоко вкусное верно.
Рассмотрим более сложный пример [19].
Рассматривается дело, в котором четверо подсудимых: A,B,C и D. Инспектор полиции стремится при помощи логических рассуждений установить истину.
1. Если A виновен, то B был соучастником (и, следовательно, виновен);
2. Если B виновен, то либо C был соучастником, либо A не виновен;
3. Если D не виновен, то A виновен и C не виновен;
4. Если D виновен, то A виновен.
Спрашивается, виновен ли D?"
Предположим, что через A обозначается высказывание "A- виновен"; через B: "B- виновен"; через С: "C- виновен"; и, наконец, через D: "D- виновен". Запишем каждое из утверждений формулой исчисления высказываний:
F1: AÞ B
F2: BÞ ~AÚ C
F3: ~DÞ A&C
F4: DÞ A
Требуется выяснить, следует ли утверждение D: "D виновен" из этих четырех. По теореме2 нам достаточно исследовать на противоречивость следующую формулу F: (AÞB)&(BÞAÚC)&(~DÞA&C)&(DÞ A)&D.
Приведем формулу F к КНФ. Получим множество S, состоящее из шести дизъюнктов S1,S2,S3,S4,S5 и S6.
S: {~AÚ B, ~BÚ ~AÚ C, AÚ D, ~CÚ D, ~DÚ A, ~D}.
По теореме о полноте метода резолюций для того, чтобы установить противоречивость S достаточно построить опровержение в S. Одно из опровержений может быть следующим:
S7: ~AÚ C, резольвента S1 и S2;
S8: A, резольвента S3 и S6;
S9: ~C, резольвента S4 и S6;
S10: C, резольвента S7 и S8;
S11: ℵ, резольвента S9 и S10.
Метод резолюций является обобщением метода «доказательства от противного». Вместо того чтобы пытаться вывести некоторую формулу-гипотезу из имеющегося непротиворечивого множества аксиом, мы добавляем отрицание нашей формулы к множеству аксиом и пытаемся вывести из него противоречие. Если нам удается это сделать, мы приходим к выводу, что исходная формула была выводима из множества аксиом. При этом возможны три случая реализации метода резолюций:
1. этот процесс никогда не завершается;
2. среди текущего множества дизъюнктов не окажется таких, к которым можно применить правило резолюции. Это означает, что множество дизъюнктов выполнимо, и, значит, исходная формула не выводима;
3. на очередном шаге получена пустая резольвента. Это означает, что множество дизъюнктов невыполнимо и, следовательно, начальная формула выводима.
Имеет место теорема, утверждающая, что описанный выше процесс обязательно завершится за конечное число шагов, если множество дизъюнктов было невыполнимым.
С другой стороны, мы опираемся на результат, что формула выводима из некоторого множества формул тогда и только тогда, когда описанное множество дизъюнктов невыполнимо. А также на то, что множество дизъюнктов невыполнимо тогда и только тогда, когда из него применением правила резолюции можно вывести пустой дизъюнкт.
В сущности, метод резолюций несовершенен и может привести к «комбинаторному взрыву». Однако некоторые его разновидности (или стратегии) довольно эффективны. Одной из самых удачных стратегий является линейная или SLD-резолюция для хорновских дизъюнктов, содержащих не более одного положительного литерала, например A1∨A2...An ∨ B. Их называют предложениями или клозами.
В языке логического программирования Пролог фактом называется дизъюнкт состоящий только из одного положительного литерала. Дизъюнкт, состоящий только из отрицательных литералов, называется вопросом. Если дизъюнкт содержит один позитивный, и негативные литералы, он называется правилом. Правило вывода выглядит примерно следующим образом A1 ∨ A2...An ∨ B. Это эквивалентно формуле A1 ∧ A2... ∧An → B, которая на Прологе записывается в виде
B:–A1,A2,...,An.
Логической программой называется конечное, непустое множество хорновских дизъюнктов, т.е. фактов и правил.
При выполнении программы к множеству фактов и правил добавляется отрицание вопроса, после чего реализуется линейная резолюция. Ее специфика в том, что правило резолюции применяется не к произвольным дизъюнктам из программы. Берется самый левый литерал цели (подцель) и первый унифицируемый с ним дизъюнкт. К ним применяется правило резолюции. Полученная резольвента добавляется в программу в качестве нового вопроса. И так до тех пор, пока не будет получен пустой дизъюнкт, что будет означать успех, или до тех пор, пока очередную подцель будет невозможно унифицировать ни с одним дизъюнктом программы, что будет означать неудачу.
В последнем случае включается так называемый бэктрекинг — механизм возврата, который осуществляет откат программы к той точке, в которой выбирался унифицирующийся с последней подцелью дизъюнкт. Для этого точка, где выбирался один из возможных унифицируемых с подцелью дизъюнктов, запоминается в специальном стеке, для последующего возврата к ней и выбора альтернативы в случае неудачи. При откате все переменные, которые были означены в результате унификации после этой точки, опять становятся свободными.
В итоге выполнение программы может завершиться неудачей, если одну из подцелей не удалось унифицировать ни с одним дизъюнктом программы, и может завершиться успешно, если был выведен пустой дизъюнкт, а может и просто зациклиться.
Как указывалось метод резолюции применяется к подмножеству предложений, называемых фразами Хорна. Фразы Хорна – это предложения, построенные из положительных и отрицательных литералов при помощи связок “&” и “ Ú ”, причем положительный литерал, если он присутствует в предложении, должен быть единственным. Примерами фраз Хорна являются:
A Ú Ø B Ú Ø C Ú Ø D;
A;
Ø BÚ Ø CÚ Ø D.
в результате тождественных преобразований пример может быть переписан в удобном для прочтения виде:
A:- B, C, D;
A;
Ø (B, C, D).
Где: A:- B, C, D – правило; положительный литерал А – факт; выражение Ø(B, C, D) - это запрос.
Задание. Методом резолюций доказать теоремы:
1) ├ 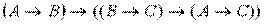 .
.
2) ├ 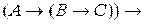
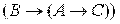 .
.
3) ├ 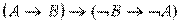 .
.
4) ├ 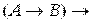
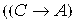
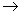
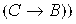 .
.
5) ├ 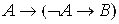 .
.
6) ├  .
.
7) ├ 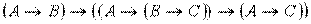 .
.
8) ├ 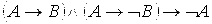 .
.
9) ├  .
.
10) ├ 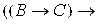

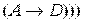 .
.
11) ├ 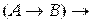
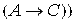 .
.
12) ├ 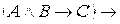
 .
.
13) ├ 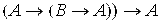 .
.
14) ├ 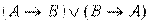 .
.
Лабораторная работа № 3.
Регулярные выражения.
Цель работы: Изучить приемы работы с регулярными выражениями в PHP.
Базовые сведения:
Общая информация
Регулярное выражение (regular expression, regexp, регэксп) - механизм, позволяющий задать шаблон для строки и осуществить поиск данных, соответствующих этому шаблону в заданном тексте. Кроме того, дополнительные функции по работе с regexp'ами позволяют получить найденные данные в виде массива строк, произвести замену в тексте по шаблону, разбиение строки по шаблону и т.п. Однако главной их функцией, на которой основаны все остальные, является именно функция поиска в тексте данных, соответствующих шаблону, описанному в синтаксисе регулярных выражений.
Очень часто регулярные выражения используются для того, чтобы проверить, является ли данная строка строкой в необходимом формате. Например следующий regexp предназначен для проверки того, что строка содержит корректный e-mail адрес:
/^\w+([\.\w]+)*\w@\w((\.\w)*\w+)*\.\w{2,3}$/Регулярные выражения пришли к нам из Unix и Perl. В PHP существует два различных механизма для обработки регулярных выражений: POSIX-совместимые и Perl-совместимые. Их синтаксис во многом похож, однако Perl-совместимые регулярные выражения более мощные и, к тому же, работают намного быстрее (в некоторых случаях до 10 раз быстрее). Поэтому здесь мы будем вести речь только о Perl-совместимых регулярных выражениях.
Кстати, необходимо заметить, что полное описание синтаксиса регулярных выражений, имеющееся в PHP Manual, занимает более 50 килобайт и, естественно, здесь мы не будем рассматривать весь синтаксис. Нам необходимы только основы, которые помогут вам понять, как именно пишутся регулярные выражения.
Сутью механизма регулярных выражений является то, что они позволяют задать шаблон для нечеткого поиска по тексту. Например, если перед вами стоит задача найти в тексте определенное слово, то с этой задачей хорошо справляются и обычные функции работы со строками. Однако если вам нужно найти "то, не знаю что", о чем вы можете сказать только то, как приблизительно это должно выглядеть - то здесь без регулярных выражений просто не обойтись. Например, вам необходимо найти в тексте информацию, про которую вам известно только то, что это "3 или 4 цифры после которых через пробел идет 5 заглавных латинских букв", то вы сможете сделать это очень просто, возпользовавшись следующим регулярным выражением:
/\d{3,4}\s[A-Z]{5}/|
из
5.00
|
Обсуждение в статье: Раздел 2. Логическое программирование |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы