 |
Главная |


Методы Изоляции элементов друг от друга в микросхемах 9 страница
|
из
5.00
|
Если транзистор Т1 в выбранном элементе проводит, что соответствует состоянию 1, ток идет через верхний эмиттер, поскольку на нижний эмиттер подан высокий потенциал. Этот ток, проходя через линию данных и усилитель считывания, даст логическую 1 на линии «:выходные данные». Если же выбранный элемент хранит 0, то Т не проводит, и отсутствие тока через усилитель устанавливает логический 0 в линии «выходные данные».
Подведем итоги. Чтобы выполнить операцию записи в рассматриваемом модуле памяти, прежде всего нужно задать адрес для выборки строки. Затем нужно установить логическую 1 на линии «запись» и подать записываемые данные на линию «входные данные». При этом элемент в выбранной строке примет состояние, соответствующее записываемым данным. Состояние элементов в невыбранных строках не изменится. Для выполнения операции чтения нужно поддерживать логический 0 на линии «запись» и задать адрес для выборки строки. Откликнется только элемент в выбранной строке. Состояние этого элемента будет определено по току транзистора Т . Соответствующее логическое значение при этом появится на линии «выходные данные».
Статическое ОЗУ на МОП-схемах
На рис. 21 показана некоторая конфигурация модуля статической памяти на МОП- схемах. Как и в предыдущем примере, каждый запоминающий элемент является бистабильной схемой, или триггером. В нем два соединенных крест-накрест транзисторных каскада, но транзисторы, естественно, не биполярные, а полевые, Транзисторы на рисунке нормально закрытые n-канальные (работающие в режиме обогащения), хотя выпускаются ЗУ и с другими типами транзисторов. Показанный на схеме нагрузочный резистор обычно реализуется также в виде транзистора по аналогии с тем, как это делалось для МОП-вентилей.
Основное отличие между схемами, изображенными на рис. 20 и 21, помимо различия в типах транзисторов, заключается в способе доступа к запоминающим элементам. В памяти с МОП-элементами для передачи информации к элементу и от элемента выбранной строки в каждом столбце используются две линии, работающие в противофазе, или парафазно. Элементы в столбцах подключаются к линиям данных через n-канальные, нормально закрытые МОП-транзисторы. Эти подключающие транзисторы выполняют функции двусторонних ключей в том смысле, что как ток, так и информация может течь в обоих направлениях. Это возможно, поскольку подложки транзисторов подсоединены к земле, а не к истоку. Когда на затвор подано достаточное положительное напряжение, между истоком и стоком возникает проводимость. Транзистор в этом случае проводит в обоих направлениях, поскольку симметрия транзистора позволяет истоку, и стоку при необходимости меняться ролями.
Затворы подключающих транзисторов соединены с соответствующими линиями выборки строк, которые, как и прежде, являются выходами адресного дешифратора. Следовательно, открытыми оказываются подключающие транзисторы только в выбранной строке, определенной поданным на дешифратор адресом. Таким образом обеспечивается связь между линиями данных и выбранными элементами в каждом столбце.
Запись осуществляется подачей низкого потенциала на одну из двух парафазных линий в каждом столбце в соответствии со значением на линии входных данных. Благодаря этому в запоминающем элементе выбранной строки устанавливается нужное состояние. Парафазные линии данных управляются МОП-транзисторами. Затворы этих транзисторов соединены с выходами вентилей И, определяющих условия, при которых транзисторы должны быть открыты. Линия «запись» соединена со входами обоих вентилей, а линия «входные данные» соединена с правым вентилем непосредственно, а с левым через инвертор.
Лшя

Таким образом, когда на линии «запись» логическая 1 и на линии «входные данные» логическая 1, на затворе правого транзистора будет высокий потенциал, и транзистор будет открыт. В результате правая половина запоминающего элемента окажется под низким потенциалом, а левая — под высоким. Это стабильное состояние соответствует запомненной логической 1. Если же на линии «входные данное» будет логический 0, а на линии «запись» — логическая 1, то открытым окажется левый транзистор, благодаря чему в выбранном запоминающем элементе устанавливается стабильное состояние, соответствующее логическому 0.
Если на линии «запись» логический 0, то оба управляющих транзистора закрыты, и состояние запоминающих элементов не меняется. На линиях данных в столбце при этом будут значения, соответствующие состоянию элемента в выбранной строке, поскольку подключающие транзисторы этого элемента открыты. В частности, значение на левой линии будет равно запомненному в элементе значению. Следовательно, операция чтения сводится к определению значения на левой линии, когда сигнал «запись» равен логическому 0.
Динамические ОЗУ на МОП-схемах
На рис. 22 показан модуль динамической памяти на МОП-схемах. В основе запоминающего элемента лежит конденсатор и один МОП-транзистор (Т2). На схеме конденсатор показан в виде отдельного прибора, включенного между затвором и истоком транзистора Т2, хотя фактически его функции и выполняет емкость затвор-подложка, которая существует и любом МОП-транзисторе за счет параллельного расположении электрода затвора по отношению к подложке. Хранение данных в таком запоминающем элементе связано с состоянием проводимости Т2, которое определяется зарядом конденсатора. Если заряд конденсатора обеспечивает достаточный положительный потенциал на затворе Т2 , то Т2 проводит. Это состояние ассоциируется с логическим 0 и не является самоподдерживающимся, поскольку конденсатор постепенно саморазряжается. Если же заряд конденсатора мал или отсутствует, то Т2 не проводит. Это состояние ассоциируется с логической 1 и является самоподдерживающимся.
Кроме конденсатора и транзистора Т2, в каждом запоминающем элементе присутствуют два транзистора для подключения элемента к линиям данных. В каждом столбце две такие линии: одна для записи данных в выбранный элемент («запись данных»), другая для считывания данных из выбранного элемента («чтение данных»). Транзистор Т2 выполняет функции двустороннего ключа для подключения линии «запись данных» к конденсатору элемента. Если Т2 активирован, то конденсатор можно зарядить или разрядить через эту линию. Транзистор Т3 подключает линию «чтение данных» к стоку Т2. Если Т3 открыт, то состояние запоминающего элемента опрашивается через линию «чтение данных». Управляются транзисторы Т1 и Т3 соответствующими линиями выборки строк от дешифратора адреса строки.
В процессе функционирования данные передаются на конденсатор элемента независимо от вида обращения, т. е. и при записи, и при чтении. При записи данные на конденсаторе поступают по линии «входные данные», и в этом случае они замещают, данные, которые были раньше. При чтении данные на конденсатор поступают от самого элемента по линии чтения. Таким образом, как можно видеть на рис. 22, при чтении возникает цепь обратной связи для данных.
Выбор данных, посылаемых на конденсатор, осуществляется селектором данных из четырех вентилей, работающим на линию «запись данных». Сигнал в линии «запись» управляет селектором, переключая его либо на «входные данные», либо на «чтение данных». Причем при любом источнике данных сигнал инвертируется, поскольку высокое напряжение на конденсаторе соответствует логическому 0, и это противоречит обычным соглашениям и отношении линий данных.
Линия
tlbtfopm

АДрЕС
Состояние проводимости транзистора Т2 в выбранном элементе преобразуется и напряжение на линии «чтение данных» при помощи нагрузочного резистора. Если Т2
проводит, что соответствует состояний 0, на линии будет низкий потенциал. В противном случае благодаря резистору линия будет под высоким потенциалом.
Как мы отмечали, состояние момента, хранящего логический 0, не является самоподдерживающимся, поскольку конденсатор из-за утечек постепенно разряжается. Через некоторое время заряд достигает такого уровня, что состояние становится неотличимым от состояний логической 1. До того как это произойдет, нужно регенерировать элемент, выполнив операцию чтения. Следовательно, модули динамической памяти требуют, чтобы каждая строка периодически регенерировались через определенный промежуток времени, Период регенерации обычно составляет несколько миллисекунд. Чтобы число строк было небольшим, в модулях динамической памяти обычно используется двумерная адресация и двунаправленный селектор выборки столбцов для разных слов. При таком подходе регенерация занимает меньше времени, поскольку регенерируются все слова в строке одновременно.
На практике в запоминающих устройствах, состоящих из нескольких модулей, процессом регенерации управляет специальная логическая схема. Эта схема циклически перебирает строки во всех модулях и регенерирует их. При этом, если модуль находится в процессе регенерации, могут возникнуть задержки при обращении к памяти от процессора.
По сравнению со статической памятью динамическая, очевидно, сложнее и требует больше внешних схем. Однако для некоторых приложений эти недостатки вполне окупаются целым рядом достоинств. Главное достоинство — это более высокая плотность упаковки информации (число битов на модуль) благодаря меньшему числу электронных компонентов в динамическом запоминающем элементе по сравнению со статическим. Второе преимущество связано с тем, что динамический запоминающий элемент не потребляет тока, за исключением тех относительно коротких отрезков времени, когда к нему обращаются. Благодаря этому резко снижается общая рассеиваемая ЗУ мощность. Довольно часто максимальная рассеиваемая мощность оказывается главным фактором, ограничивающим плотность упаковки запоминающих элементов, и в таких случаях динамическая память имеет несомненные преимущества.
3 ПРОГРАММИРУЕМЫЕ ЛОГИЧЕСКИЕ ИНТЕГРАЛЬНЫЕ СХЕМЫ
История развития программируемой логики начинается с появления программируемых постоянных запоминающих устройств (ППЗУ - Programmable Read Only Memory - PROM) в начале 70-х годов. Первое время PROM использовались исключительно для хранения данных, позже их стали применять для реализации логических функций. Неудобство использования PROM в качестве логических преобразователей заключается в том, что логические функции перед записью в PROM необходимо приводить к совершенной дизъюнктивной нормальной форме (СДНФ), кроме того, емкость PROM не позволяла реализовать функции большого числа переменных.
Специально для реализации систем булевых функций (СБФ) большого числа переменных были разработаны и с 1971 г. стали выпускаться промышленностью программируемые логические матрицы (ПЛМ - Programmable Logic Arrays - PLAs). Именно PLA можно считать первыми программируемыми логическими устройствами (Programmable Logic Devices - PLD). PLA получили очень широкое распространение в качестве универсальной элементной базы.
Совершенствование архитектуры PLA привело к появлению программируемых матриц логики (Programmable Array Logics - PALs), которые на долгие годы определили наиболее популярную архитектуру PLD. Первые PAL были разработаны фирмой Monolithic Memories в 1976 году. Позже фирма Monolithic Memories вошла в состав фирмы Advanced Micro Devices (AMD), которая начала производить PAL c 1977 года. Сейчас аббревиатура PAL является торговой маркой фирмы AMD.
С момента своего появления PAL стали успешно конкурировать с PLA и в настоящее время благодаря ряду присущих им положительных свойств практически полностью вытеснили программируемые пользователем PLA.
Дальнейшее совершенствование технологии производства интегральных схем, повышение степени интеграции, успехи в создании корпусов с большим числом внешних выводов в начале 90-х годов привели к возможности реализации на одном кристалле нескольких PAL, объединяемых программируемыми соединениями. Подобные архитектуры получили название сложных PLD (Complex PLD - CPLD), соответственно все разработанные ранее PLD стали называть стандартными PLD (Standart PLD - SPLD) или классическими PLD (Classic PLD).
Основу всех рассмотренных выше устройств составляют программируемые матрицы. Поэтому эти устройства еще называют программируемыми логическими устройствами, имеющими матричную структуру.
Параллельно с PLD также развивались архитектуры вентильных матриц (Gate Array - GA) или матриц логических ячеек (Logic Cell Array - LCA), в русскоязычной литературе получившие название базовых матричных кристаллов (БМК). Первые вентильные матрицы были полузаказными, т.е. программировались во время изготовления, что сдерживало их широкое практическое использование. Однако в 1985 году фирма Xilinx выпустила программируемую пользователем вентильную матрицу (Field Programmable Gate Array - FPGA). Это дало сильный толчок к широкому распространению вентильных матриц и конкуренции их с PLD.
В русскоязычной литературе нет четкого разделения между PLD, PAL, PLA, SPLD, CPLD и FPGA. Чаще всего все эти устройства называют программируемыми логическими интегральными схемами (ПЛИС). Кроме того, в русскоязычной литературе можно встретить следующую терминологию: программируемые логические устройства (ПЛУ) - для обозначения PLD, программируемые логические матрицы (ПЛМ) - для обозначения PLA, программируемые матрицы логики (ПМЛ) - для обозначения PAL,
программируемые логические интегральные схемы (ПЛИС) - для обозначения CPLD.
Таблица 5 - Тенденции развития CPLD и FPGA
| Параметры | ||||
| Стоимость | — | >500$ | <50$ | <5$ |
| Число вентилей | 5.000 | 50.000 | 500.000 | |
| Число выводов | ||||
| Число транзисторов | 85k | 2M | 6M | 225M |
| Задержка (min) | 40 нс | 15 нс | 3,5 нс | 1,5 нс |
В настоящее время наблюдается бурное развитие архитектур CPLD и FPGA (каждый год появляются новые поколения этих устройств), сближение их архитектур, приобретение ряда общих свойств, снижения стоимости, повышение быстродействия и функциональной мощности (табл.5). Анализ тенденции развития архитектур программируемой логики позволяет предположить, что в ближайшие пять лет основу элементной базы цифровых систем будут составлять CPLD и FPGA. Преимущество использования программируемой логики в цифровых системах становится особенно очевидным, когда необходимо быстро разработать опытный образец изделия или предполагаются частые корректировки проекта в процессе его разработки.
КЛАССИФИКАЦИЯ PLD
Прежде, чем рассматривать возможные классификации программируемой логики, покажем ее место в общей структуре элементной базы цифровых систем (рис.23). Все выпускаемые в настоящее время интегральные схемы (ИС - Integrated Circuits - ICs) можно разделить на два противоположных класса: стандартные (Standard Products) и специализированные (Application Specific Integrated Circuits - ASIC). Стандартные ИС, как правило, разрабатываются по инициативе производителя и выпускаются большими тиражами. Это микросхемы памяти, микропроцессорные комплекты и др. К ним также можно отнести элементы малой и средней степени интеграции: вентили, регистры, шифраторы, дешифраторы, мультиплексоры и т.д.
Однако, как бы не была широка номенклатура стандартных ИС, последние не могут охватить все потребности разработчиков цифровой техники. Поэтому значительный объем производства составляют специализированные ИС. Их принято делить на три класса: полностью заказные (Full Custom), полузаказные (Semi-Custom) и
программируемые пользователем(Field Programmable).

Рисунок 23 - Общая классификация современной элементной базы цифровых систем
Разработка полностью заказных ИС охватывает полный цикл проектирования. При этом наблюдается наибольшая степень использования площади кристалла и достигаются наилучшие характеристики устройства. Время разработки и подготовка производства полностью заказной ИС может составлять несколько лет, что влечет значительное удорожание изделия (рис.24), компенсируемое большими объемами его производства.
Стоимость __
Полностью заказные микросхемы
Стандартные
ячейки
Вентильные
матрицы
Программируемая логика
Стандартная
логика
Дни Недели Месяцы Годы Время
Рисунок 24 - Зависимость стоимости и времени разработки проекта от элементной базы
Базовые структуры полузаказных ИС производятся массовыми тиражами, а их специализация выполняется на последних этапах изготовления ИС. Это позволяет значительно снизить стоимость устройства. Однако, поскольку разработка полузаказных ИС неизбежно связана с передачей информации с описанием устройства от пользователя производителю, время разработки цифровых устройств (ЦУ) колеблется от нескольких недель до нескольких месяцев. Типичными представителями полузаказных ИС являются микросхемы стандартных ячеек (Standard Cells - SC) и вентильных матриц (Gate Arrays - GA).
Наибольшей оперативностью и гибкостью использования характеризуются ИС, программируемые пользователем. Стоимость и время разработки при этом минимальны. К недостаткам проектирования ЦУ на программируемых пользователем ИС следует отнести не всегда рациональное использование площади кристалла, отсутствие эффективных методов проектирования сложных устройств и др. Однако не смотря на указанные недостатки в настоящее время программируемые пользователем ИС считаются наиболее перспективной элементной базой. Это подтверждается многочисленными статистическими исследованиями и неизменным увеличением объема их производства.
В свою очередь программируемые пользователем ИС можно разделить на микропрограммные ИС и программируемую логику (ПЛИС), в соответствии с двумя основными подходами к проектированию ЦУ: микропрограммным и аппаратным. Первый подход предполагает построение ЦУ на базе некоторого универсального элемента (микропроцессора, микрокомпьютера, микроконтроллера и др.), который специализируется загружаемой в ОЗУ или зашиваемой в ППЗУ программой (микропрограммой). Недостатком такого подхода является невысокая скорость работы устройства, однако последнее может быть легко перенастроено на другой алгоритм работы путем замены программы в ОЗУ или в ППЗУ.
Характерной особенностью ПЛИС является возможность их настройки на заданный алгоритм функционирования путем изменения своей внутренней структуры. Проектирование ЦУ на основе ПЛИС заключается в определении настройки по заданным спецификациям и программировании микросхемы на специальном оборудовании, называемом программатором (programmer). Построенные на основе ПЛИС устройства отличает прежде всего высокая скорость работы, низкая стоимости и малые сроки проектирования. Первые промышленные ПЛИС характеризовались однократностью настройки, которая осуществлялась путем пережигания плавких перемычек (fuse-link). Однако с появлением перепрограммируемых ПЛИС с электрическим и ультрафиолетовым стиранием этот недостаток устраняется и по способу своего использования они ничем не уступают микропрограммным ИС.

Рисунок 25 - Классификация PLD по структурной организации
В общем случае строгой границы между микропрограммными и логическими ИС нет, свидетельством чего могут служить программируемые пользователем контроллеры (Field Programmable Controller - FPC).
В настоящее время ПЛИС принято делить на три (рис. 25) больших класса: стандартные PLD (Standart PLD - SPLD) или классические PLD (Classic PLD), сложные PLD (Complex PLD - CPLD) и программируемые пользователем вентильные матрицы (Field Programmable Gate Array - FPGA).
Структуру большинства стандартных PLD условно можно представить в виде совокупности двух матриц взаимнортогональных проводников: матрицы И и матрицы ИЛИ. Входные сигналы обычно поступают на парафазные входы матрицы И, которая на ортогональных шинах позволяет реализовать любые конъюнкции входных переменных. Выходы матрицы И соединены со входами матрицы ИЛИ, которая на выходах реализует дизъюнкции поступающих сигналов. Совокупность выходных шин матрицы И и входных шин матрицы ИЛИ образует множество промежуточных шин PLD (product terms).
В зависимости от того, какая матрица программируется, матрица И или матрица ИЛИ, SPLD принято делить на три класса: программируемые логические матрицы (ПЛМ - Prgrammable Logic Arrays - PLAs), программируемые постоянные запоминающие устройства (ППЗУ - Programmable Read Only Memory - PROM) и программируемые матрицы логики (ПМЛ - Programmable Array Logics - PALs). В PLA (рис.26) программируются обе матрицы: матрица И и матрица ИЛИ. В PROM (рис.27) матрица И постоянно настроена на функции полного дешифратора. В структуре PAL (рис.28), наоборот, матрица ИЛИ имеет фиксированную настройку, а программируется только матрица И.
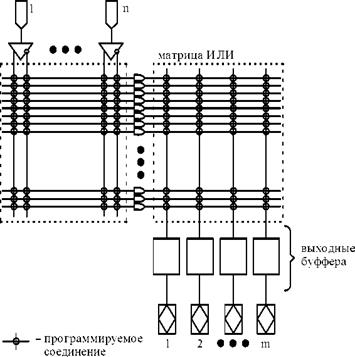
Рисунок 26 - Структура PLA

Рисунок 27- Структура PROM
У У
м ••• м
матрица ИЛИ
i Н ►
<1 IHI
1Н>
• • •
• • •
< И I 1 И I 1 И ►
JHt
< н У
<М1 IMI О-G'
(Ml
/А /Ч • • • /Ч
матрица И
МЯ
МЯ
МЯ
МЯ
выходные
буффера
(макро
ячейки)
с.
| п | п | п | п | |||
| V | V | у | V | |||
| • • • | m |
обратные связи
фиксированное соединение
^ программируемое соединение
Рисунок 28 - Структура PAL
Безусловно, приведенная классификация не охватывает всего разнообразия SPLD. Например, структуру, очень напоминающую PLA, имеют программируемые логические секвенсоры (Programmable Logic Sequencers - PLSs), и обобщенные матрицы логики (Generig Array Logics - GAL) подобны PAL.
Сложными PLD принято называть микросхемы высокой степени интеграции, структура которых представляет собой совокупность нескольких PAL, объединяемых программируемыми межсоединениями (рис.29). Многими фирмами выпускаются различные структуры CPLD. Например, фирма Advanced Micro Devices (AMD) свои CPLD назвала КМОП-макроматрицы высокой плотности (Macro Array CMOS High-density - MACH). Фирма Altera выпускает несколько видов CPLD: многократные матричные таблицы (Multiple Array Matrix - MAX) и FLASH-устройства, названные по способу перепрограммирования настраиваемых элементов.

Рисунок 29 - Обобщенная структура CPLD
Дальнейшее развитие структура сложных PLD получила в микросхемах фирмы Altera, названных матрицами элементов гибкой логики (Flexible Logic Element MatriX - FLEX), обобщенная структура которых показана на рис.30. Здесь отсутствует привычная PAL-структура, а имеются блоки логических элементов, объединяемые в LAB-модули по 8 элементов в каждом. Трассировка соединений между LAB-модулями осуществляется с помощью программируемых каналов межсоединений.
Фактически структура FLEX-устройств очень напоминает структуру FPGA, выпускаемых фирмой Xilinx (рис.30). Основу FPGA составляет матрица логических элементов, между которыми располагается поле межсоединений. По краям кристалла находятся блоки ввода-вывода.
Все PLD можно также классифицировать по типу настраиваемого элемента (рис.31):
статическое ОЗУ (SRAM) - FPGA, FLEX, FLASH;
электрически стираемое программируемое ПЗУ (EEPROM) - MACH, MAX7000, MAX9000, SPLD;
перепрограммируемое ПЗУ с ультрафиолетовым стиранием (EPROM) - MAX5000, SPLD.
Число настроек элементов первого класса обычно не ограничивается. Для второго и третьего классов число перезаписей данных настройки обычно ограничивается значением 100 - 1000 раз. Электрически стираемые элементы автоматически стираются при каждом новом программировании. Под EPROM обычно понимают ПЗУ, стираемое ультрафиолетовым излучением. Поэтому перепрограммирование микросхем третьего класса связано с необходимостью выполнения операции ультрафиолетового стирания, которая длиться около часа.

Элементы
ввода-вывода
Рисунок 30 - Обобщенная структура CPLD гибкой логики
Блоки
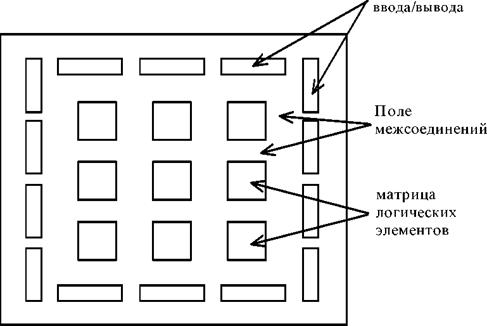
Рисунок 31 - Обобщенная структура FPGA XC2000, XC3000, XC4000
По количеству перепрограммирований PLD можно также разделить на многократно программируемые и однократно программируемые (One Time Programmable - OTP) (рис.32). Большинство PLD (как однократно, так и многократно настраиваемые) программируются самим пользователем во время эксплуатации (field). Однако, если проект тщательно отлажен и изделие производится массовыми тиражами, в нем могут применяться масочно программируемые PLD, настройка которых выполняется при их изготовлении.
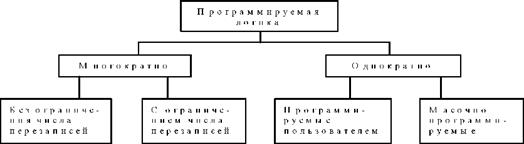
Рисунок 32 - Классификация программируемой логики по способу программирования

все SPLD, MAX FPGA
MACH FLASH
FLEX
Рисунок 33 - Классификация программируемой логики по времени прохождения сигнала
(задержки) с любого входа на любой выход
Еще одним важным критерием классификации PLD является предсказуемость задержки прохождения сигнала со входа на выход устройства (рис.33). Для всех SPLD и MACH-устройств задержка прохождения сигнала с любого входа на любой выход всегда постоянна. Поэтому при проектировании на этих устройствах можно не выполнять временное моделирование сигналов. Для MAX, FLASH и FLEX-устройств задержка переменная, но легко вычисляемая. Для FPGA задержка полностью зависит от пути, по которому проходит сигнал со входа на выход. При изменении трассировки межсоединений изменяются и задержки сигналов.
CPLD можно также разделять на устройства, требующие дополнительного оборудования для своего функционирования (FPGA, FLEX), и не требующие вспомогательного оборудования (все остальные CPLD и SPLD). Дополнительные устройства необходимы для выполнения начальной инициализации CPLD, настраиваемыми элементами которых являются статические ОЗУ. В качестве таких устройств могут выступать ОЗУ, ПЗУ, микроконтроллер, персональный компьютер и др.
В данном пункте были рассмотрены только основные способы классификации программируемой логики. Этот процесс можно было бы продолжить дальше, разделяя PLD на классы по степени обладания теми или иными свойствами. Но такая классификация мало полезна, поскольку свойств PLD достаточно много и часто микросхемы в пределах одного поколения и даже одной серии обладают различными свойствами. Поэтому ограничимся рассмотрением наиболее общих свойств, которые присущи различным PLD.
ОСНОВНЫЕ СВОЙСТВА PLD
PLD обладают рядом характерных особенностей, благодаря которым они получили такое широкое распространение и на сегодняшний день считаются наиболее перспективной элементной базой цифровых систем. Ограничимся простым перечислением основных свойств современных PLD, объединив их в следующие группы:
общие свойства PLD;
функциональные свойства PLD;
системные свойства PLD, имеющие значение при использовании PLD в составе цифровых систем;
свойства проектирования, проявляющиеся при разработке проекта.
Безусловно, абсолютно идеальной элементной базы не бывает, поэтому здесь
отмечаются и недостатки PLD.
Общие свойства PLD
Практически всем современным PLD присущи следующие общие свойства:
Низкая стоимость. Благодаря большим объемам производства, что обусловлено высоким спросом, стоимость PLD начинает приближаться к стоимости стандартных устройств.
Высокое быстродействие. Применение передовых технологий привело к снижению задержки прохождения сигнала через PLD до 3.5 ns и до 1 ns на один логический элемент для FPGA, что позволяет достигать частоты функционирования устройств до 250 MHz. Практически каждая микросхема PLD имеет несколько реализаций с градацией по быстродействию. Поэтому если высокое быстродействие не требуется, пользователь с целью экономии средств всегда может выбрать подходящую микросхему.
Высокая степень интеграции. PLD имеют достаточно регулярную структуру, что позволяет применять 0.5-микронную технологию и достигать до 100000 вентилей на кристалл, приближая их по степени интеграции к микросхемам памяти.
Функциональная мощность. Стандартные PLD могут заменять десятки корпусов “жесткой” логики, а сложные PLD - сотни корпусов “жесткой” логики, что позволяет реализовать на одной CPLD всю или некоторую часть цифровой системы, например, сопроцессор.
|
из
5.00
|
Обсуждение в статье: Методы Изоляции элементов друг от друга в микросхемах 9 страница |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы