 |
Главная |


Методы Изоляции элементов друг от друга в микросхемах 6 страница
|
из
5.00
|
Сложности могут возникать при синтезе конечных автоматов из-за недостатка промежуточных шин для реализации функций возбуждения элементов памяти. Поскольку коды состояний задаются пользователем, можно применить специальные методы рационального кодирования внутренних состояний.
Специфические свойства архитектуры PLD предоставляют новые возможности при синтезе комбинационных и последовательностных схем. Важное место среди методов синтеза на PLD цифровых устройств, математической моделью которых является конечный автомат, занимают методы синтеза одноуровневых схем, поскольку они обладают наибольшим быстродействием. Благодаря своей блочной структуре, CPLD оказались удобными для построения сложных иерархических и параллельных устройств. При построении микропроцессорных систем для согласования сигналов между различными микросхемами часто используются простейшие функциональные узлы, такие как инверторы, вентили, триггеры, регистры и др. Совокупность подобных элементов получила название логики склеивания (glue logic). PLD получили очень широкое распространение при реализации логики склеивания, причем в качестве элементов этой логики могут выступать простые функциональные узлы как комбинационного, так и регистрового типа.
Синтез сложных проектов на CPLD дополнительно требует специальной программы, называемой упаковщиком (fitter), которая выполняет “подгонку” проекта (fitting) в заданную структуру CPLD. При синтезе сложных проектов следует планировать 20-40% использования ресурсов CPLD для возможности корректировок и эффективной работы упаковщика. Проект рекомендуется создавать путем выполнения ряда итераций: вначале реализуется ядро проекта, а затем добавляется остальная логика до полного проекта. При этом обеспечивается лучшее решение по упаковке проекта и наиболее рациональное назначение сигналов внешним выводам.
Большие проекты могут разбиваться на отдельные PAL-блоки как автоматически, так и указываться пользователем с помощью директив. Пользователем также могут указываться назначение сигналов отдельным выводам. Если после указаний пользователя проект не может быть упакован в заданное устройство, программа запрашивает возможность альтернативных решений (компромиссов): переназначение выводов,
оптимизацию типов триггеров, повторное прохождение сигналов через устройство и др.
Рекомендуется первоначальную упаковку проекта выполнять предоставлением программе наибольших возможностей, а затем конкретизировать назначение выводов. После получения некоторого решения проект может быть оптимизирован для наиболее рационального использования ресурсов CPLD с целью их освобождения для реализации другой логики.
Моделирование проекта
Моделирование проекта на PLD может осуществляться как на логическом, так и на физическом уровне. При моделировании на логическом уровне работоспособность проекта проверяется на основании математических моделей PLD и выполняется программным обеспечением без участия конкретной микросхемы. На физическим уровне проверяется реальное функционирование проекта с использованием уже запрограммированных PLD.
Логическое моделирование делится на функциональное и временное (временной анализ). Функциональное моделирование выполняется программным обеспечением на основании тестовых векторов входных и выходных сигналов проекта. Тестовые вектора могут задаваться в файле исходного описания проекта или находиться в отдельном файле. Некоторые пакеты допускают задание тестовых векторов в виде временных диаграмм. При логическом моделировании возможно решение следующих задач:
определение выходных значений по заданным входным воздействиям;
сравнение вычисленных выходных значений с эталонными;
моделирование неисправностей устройства.
Временное моделирование выполняется на временных моделях PLD и заключается в определении времени прохождения и формирования различных сигналов. Результаты временного моделирования могут также представляться в виде временных диаграмм.
Кроме того с помощью отдельной программой, называемой временным анализатором, производится анализ, позволяющий обнаружить пути сигналов, критичные по скорости. Оптимизация путей распространения сигналов позволяет повысить быстродействие всего проекта.
Моделирование проекта на физическом уровне (тестирование на программаторе) осуществляется после настройки PLD. Для этого в файл, содержащий информацию о настройке PLD и управляющий работой программатора, добавляется информация для тестирования устройства. Последняя может быть получена на основании тестовых векторов и результатов функционального моделирования. Причем здесь возможно моделирование в реальном масштабе времени, в том числе на предельной частоте работы PLD.
CPLD, поддерживающие JTAG-стандарт, могут тестироваться непосредственно на плате методом граничного сканирования. Для этого программным обеспечением на основании тестовых векторов создаются тестовые последовательности в JTAG-стандарте. При этом допускается тестирование
одного CPLD;
цепочки CPLD;
цепочки всех устройств проекта (в том числе и CPLD), поддерживающих JTAG-стандарт.
Программирование PLD
Программирование PLD заключается в его настройке на заданный алгоритм функционирования. Стандартные PLD программируются с помощью программаторов. Технологии программирования (последовательности подаваемых сигналов, уровни напряжений и др.) могут существенно отличаться даже для одних и тех же PLD, но производимых различными фирмами. Поэтому важное значение имеет использование только сертифицированных программаторов, рекомендуемых фирмами-изготовителями PLD.
CPLD, в которых настраиваемым элементом является SRAM, конфигурируются всякий раз, при включении питания. Процесс конфигурирования состоит из двух частей: загрузки данных и обнуления всех регистров. Данные о настройке CPLD могут поступать от управляющего компьютера, микропроцессора, ПЗУ, ОЗУ, других CPLD. Форма передаваемых данных может быть как последовательная, так и параллельная. Имеется также ряд режимов программирования, когда CPLD выступает в качестве активного устройства (само управляет процессом загрузки данных), и в качестве пассивного устройства (другое устройство управляет процессом загрузки данных).
Как правило, фирмы-изготовители CPLD выпускают специализированные ППЗУ для программирования CPLD. В такие ППЗУ с помощью программатора записывается информация о настройке CPLD и они устанавливаются на плате вместе с CPLD. С целью минимизации площади платы для передачи данных между ППЗУ и CPLD используется последовательный интерфейс, а CPLD выступает в качестве активного устройства.
Некоторые CPLD, поддерживающие JTAG-стандарт, могут программироваться на плате, используя сигналы JTAG-стандарта. Для этого на границе платы устанавливается специальный разъем для передачи сигналов управления процессом программирования. Несколько CPLD на одной плате могут объединяться в цепочки, но в каждый момент времени допускается программирование только одного CPLD.
ОБЛАСТИ ПРИМЕНЕНИЯ PLD
PLD хорошо себя зарекомендовали в качестве универсальной элементной базы. Рассмотрим конкретные примеры использования PLD, приводимые в литературе фирмами-изготовителями PLD и производителями программного обеспечения для проектирования на основе PLD.
Таблица 6 - Стандартные функциональные узлы, реализуемые на PLD
| Комбинационные | Последовательностные |
| Легко реализуемые на PLD | |
| Шифраторы | Регистры |
| Дешифраторы | Сдвиговые регистры |
| Мультиплексоры | Двоичные счетчики |
| Демультиплексоры | Счетчики по модулю |
| Компараторы A=B | Счетчики Грея |
| Сумматоры | Счетчики Джонсона |
| Инкременторы | Асинхронные счетчики |
| Декременторы | Делители частоты |
| Преобразователи кодов | Полиномиальные счетчики |
| Приоритетные шифраторы | Двоичные счетчики |
| Требующие каскадной реализации на CPLD | |
| Мультиплексоры | Счетчики по модулю |
| Демультиплексоры | Счетчики Грея |
| Компараторы | Счетчики Джонсона |
| Сумматоры с параллельным переносом | |
| Преобразователи кода Грея в двоичный код |
На классических PLD можно легко реализовать ряд стандартных комбинационных и последовательностных узлов цифровых систем (табл.6). Отдельные функциональные узлы большой размерности требуют каскадной реализации на стандартных PLD или на сложной PLD.
Необходимость построения стандартных функциональных узлов на PLD может возникать по следующим причинам:
отсутствие необходимой номенклатуры;
нестандартные размеры узла;
большая размерность узла;
необходимость специального управления узлом;
требования схемотехники по согласованию напряжений уровней сигналов, временных задержек, улучшения помехозащищенности и др.;
улучшение временных параметров узла: постоянная задержка с любого входа на любой выход ;
необходимость реализации нескольких разнотипных узлов в одном корпусе;
необходимость тестирования по JTAG-стандарту;
минимизация числа корпусов схемы и др.
Особенно часто PLD используются при построении специализированных микропроцессорных систем:
для управления микропроцессорной системой;
для управления памятью;
для реализации отдельных функциональных узлов МПС;
для реализации шинного интерфейса;
в видеосистемах;
в других приложения микропроцессорных систем;
а также в качестве “логики склеивания” (glue logic), например, для реализации интерфейса микропроцессора с другими устройствами.
Кроме того, PLD широко используется в:
системах цифровой обработке сигналов;
системах телекоммуникации;
а также самых разнообразных приложениях автоматики и электроники.
ОСНОВНЫЕ СТРУКТУРЫ CPLD
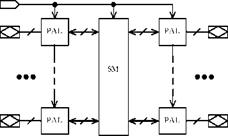
Все архитектуры рассматриваемых CPLD можно представить в виде пяти структур, приведенных на рис.34.
Структура на рис.34,а представляет собой “классическую” сложную CPLD: совокупность PAL-блоков (Programmable Array Logic), объединяемых матрицей переключений SM. Основные функциональные преобразования выполняются в PAL- блоках, а матрица переключений служит для передачи сигналов между PAL-блоками. Каждый PAL-блок имеет свое множество двунаправленных выводов (на рис. 34 не показаны), по которым поступают обрабатываемые сигналы. Кроме того, имеются специализированные (dedicated) входы, которые связаны с матрицей переключений и со всеми PAL-блоками. Эти входы обычно используются для глобальных сигналов установки, сброса и синхронизации триггеров, а также для глобальных сигналов разрешения выходов.
При возрастании числа PAL-блоков трудно обеспечить необходимые соединения между ними без значительного увеличения размеров матрицы переключений. В структуре на рис.34,б матрица переключений представлена в виде глобальной шины GI и нескольких локальных шин LI (семейство MACH5). Здесь все PAL-блоки объединены в сегменты по четыре PAL-блока в каждом сегменте. Локальные шины обеспечивают соединения между PAL-блоками одного сегмента, а глобальная шина - между сегментами PAL-блоков.
Для повышения гибкости в назначении внутренней логики внешним выводам фирмой Altera предложена структура, изображенная на рис.34,в. Здесь основные функциональные блоки организованы в виде матрицы логических элементов и названы LAB-модулями. Между строками и столбцами LAB-модулей расположены горизонтальные и вертикальные каналы трассировки. LAB-модули связаны с горизонтальными каналами, но имеется возможность передачи сигналов с горизонтальных каналов на вертикальные и наоборот. Элементы ввода-вывода подсоединяются к концам как горизонтальных, так и вертикальных каналов.
В структуре на рис.34,г (семейство XC9500) все обрабатываемые сигналы дважды проходят через матрицу переключений SM, при вводе и при выводе, для обеспечения 100% соединений между PAL-блоками и блоками ввода-вывода (IOB). Однако данная структура не гарантирует постоянной задержку прохождения сигнала с любого входа на
любой выход, поскольку задержка будет зависеть от способа настройки соответствующей макроячейки.
«67^»
PAL
~г
••• I
JtL
PAL
т
I •••
_Y_
LI
LI
GI
| PAL | ||
| LI | V | |
| PAL | ||
<7^
PAL
T
<7*>
^22
| PAL | ||
| V | LI | |
| PAL | ||
PAL
t
<7*»
IOE IOE IOE IOE IOE IOE
iT n n
SM
<7*> PAL
У У I
| LAB | EAB | LAB | ||||||
| LAB | EAB | LAB | ||||||
IIOE |<- | IOE |<- I IOE |«- | IOE |«- | IOE |<- | IOE |«-
| -H IOE | | £2— |
| ->| IOE | | • •• |
| 4 IOE | | £2— |
| -H IOE | | |
| -H IOE | | г) |
| -H IOE | |
<7^

IOE IOE IOE IOE IOE IOE
Рисунок 34 - Основные структуры CPLD
Структура на рис.34,д представляет специализированное семейство XC7300 фирмы Xilinx, предназначенное для построения арифметических вычислителей. Она содержит два типа функциональных блоков: быстрые FFB и повышенной функциональной мощности FB. Блоки FB реализуют арифметические операции, а на блоках FFB строятся конечные автоматы для управления вычислительными процессами.
Функциональные преобразователи
Основными функциональными преобразователями большинства CPLD являются PAL-подобные блоки, состоящие их двух матриц: матрицы И и матрицы ИЛИ, причем программируется только матрица И, а матрица ИЛИ имеет фиксированную настройку. Пара матриц И и ИЛИ позволяет вычислять булевы функции, представленные в дизъюнктивной нормальной форме (ДНФ). Выходные сигналы PAL-блоков формируются с помощью программируемых макроячеек, имеющих обратные связи с матрицей И. Обычно макроячейка включает вентиль ИЛИ (часть матрицы ИЛИ), регистр и элементы для ее программирования. Отметим, что в MAX-устройствах PAL-блоки названы LAB- модулями.
В устройствах FLEX-логики в качестве функциональных преобразователей выступают LAB-модули (Logic Array Block), содержащие множество логических элементов, объединяемых локальной шиной межсоединений. Каждый логический элемент включает функциональный генератор (Look-Up Table - LUT), который может программно настраиваться на табличную реализацию любой функции определенного числа переменных. При таком подходе к реализации логических вычислений отпадает необходимость в матрицах И и ИЛИ, благодаря чему экономится площадь кристалла и появляется возможность усложнения структуры логических элементов.
Функциональной мощности LAB-модулей часто бывает недостаточно для реализации сложных функций, поэтому в структуру устройств FLEX 10K введены EAB- модули (Embedded Array Block). EAB-модуль может настраиваться на табличную реализацию общих мегафункций проекта, например, умножения, корректировки ошибок, векторных операций и др. Эти функции затем используются вместе с обычной логикой, реализуемой в L AB-модулях, для построения целых систем на одном FLEX-устройстве: микроконтроллеров, специализированных процессоров, систем цифровой обработки сигналов, телекоммуникации и др. При необходимости EAB-модуль может использоваться как статическое ОЗУ в различных конфигурациях: 265х8, 512х4, 1024х2 и 2048х1. Для построения ОЗУ большого размера несколько EAB-модулей объединяются вместе.
Некоторые CPLD обеспечивают дополнительные логические преобразования. Так, устройства FLASH и FLEX 10K имеют программируемую опцию выхода “открытый сток” (open-drain), использование которой вместе с внешним питающим резистором позволяет реализовать дополнительную функцию ИЛИ. В устройствах семейства XC9500 матрица переключений позволяет реализовать функцию И большого числа переменных. Возможности матрицы переключений еще более развиты в устройствах семейства XC7300. Здесь матрица переключений, кроме обеспечения 100% соединений между функциональными блоками, позволяет реализовать функции И, ИЛИ, И-НЕ и ИЛИ-НЕ большого числа переменных. Последнее свойство матрицы переключений носит название “SMART switch”.
Кроме рассмотренных основных логических преобразователей CPLD также допускают функциональную обработку сигналов в макроячейках (логических элементах).
Обеспечение соединений между функциональными блоками
Для большинства CPLD соединения между PAL-блоками осуществляется с помощью матрицы переключений. В идеальном случае матрица переключений обеспечивает 100% соединений между любыми PAL-блоками. Данное свойство выполняется для сравнительно простых устройств MAX7000, FLASH-логики, XC7300 и XC9500, а также для устройств семейства MACH5. Для других устройств семейств MACH и семейств MAX не гарантируется 100% разводка сигналов между функциональными блоками, поэтому в некоторых случаях приходится преобразовывать проект для уменьшения числа связей между PAL-блоками.
С возрастанием сложности устройства данное свойство выполнить становится все труднее ввиду значительной площади, занимаемой на кристалле матрицей переключений. В устройствах семейства MACH5 (рис.34,б) эта проблема решается за счет введения двухуровневой матрицы переключений: глобальной матрицы GI и локальных матриц LI. Локальные матрицы обеспечивают соединения между группами PAL-блоков, называемыми сегментами, а глобальная матрица выполняет соединения сигналов между сегментами.
В CPLD со структурой на рис.34,в фактически имеется два уровня межсоединений. Глобальные соединения обеспечивают каналы трассировки, а на нижнем уровне находятся локальные шины LAB-модулей. Локальные шины гарантируют 100%-ю разводку любых сигналов внутри LAB-модуля, а на глобальном уровне обеспечение соединений зависит от ресурсов каналов трассировки, которые различны для устройств различных семейств.
Каналы трассировки в структуре на рис.34,в, кроме обеспечения соединений между LAB-модулями, служат также для подвода сформированных сигналов к внешним выводам и от внешних выводов к внутренней логике (в других структурах CPLD внешние выводы подсоединяются непосредственно к функциональным блокам). Поэтому от возможностей каналов трассировки во многом зависит успех реализации проекта на заданном устройстве.
В общем случае обеспечение соединений между функциональными блоками и между внутренней логикой и внешними выводами является достаточно сложной задачей, которая решается с помощью программы, называемой упаковщиком (fitter). В некоторых случаях указание разработчиком рекомендаций по декомпозиции логики проекта для реализации в отдельных функциональных блоках способствует успешному решению задачи.
При разработке на CPLD быстродействующих проектов важное значение имеют временные параметры. Во всех устройствах фирмы Advanced Micro Devices (AMD) любой сигнал со входа или цепи обратной связи может пройти на выход только через матрицу переключений. Благодаря этому сохраняется постоянной задержка формируемых сигналов. Данное свойство реализовано за счет снижения быстродействия и использования дополнительных ресурсов CPLD. Поэтому в устройствах других производителей концепция фирмы AMD не поддерживается и задержки выходных сигналов могут быть различными для разных сигналов. Подобная проблема неизбежно усложняет проектирование, требуя выполнения временного анализа. В некоторых случаях для решения данной проблемы приходится прибегать к синхронизации выходных сигналов путем их буферизации в регистрах.
Соотношение числа триггеров и внешних выводов
Отношение числа триггеров к числу внешних выводов иногда выступает в качестве грубой меры функциональной мощности CPLD: чем оно больше, тем функциональная мощность микросхемы выше. Триггеры CPLD, в основном, используются для реализации регистровой логики, буферизации входных и выходных сигналов, а также для реализации внутренней (промежуточной) регистровой логики, например, памяти автомата. Большое число триггеров по отношению к числу внешних выводов особенно важно при построении таких функциональных узлов, как счетчики и регистры.
Поскольку в структурах на рис.34,а, рис.34,б и рис.34,д одна макроячейка соответствует одному внешнему выводу, можно предположить, что число триггеров в этих структурах будет кратно числу внешних выводов. Это предположение подтверждается для всех MACH-устройств, FLASH-логики и семейства XC7300: один триггер на вывод для FLASH-логики, MACH1, MACH3 и XC7300; два триггера на вывод для MACH2 и MACH5; три триггера на вывод для MACH4. Исключение составляют семейства MAX5000 и MAX7000. Здесь наблюдается тенденция возрастания отношения числа триггеров к числу внешних выводов с увеличением сложности устройства. При этом отдельные макроячейки не имеют связи с внешними выводами, а используются для реализации внутренней логики.
В CPLD со структурами на рис.34,в и рис.34,г нет жесткой зависимости числа макроячеек от числа внешних выводов. Однако и для этих устройств (MAX9000, FLEX- логика и XC9500) наблюдается тенденция опережающего роста триггеров по отношению к числу внешних выводов с увеличением сложности устройства.
При задействовании триггера макроячейки в стандартных PLD для реализации внутренних функций, например, памяти автомата, внешний вывод, как правило, остается не используемым. Данная проблема в CPLD решается несколькими способами:
введением в макроячейку дополнительного скрытого (buried) триггера для реализации внутренней логики (MACH2,4,5);
введением в структуру PAL-блока скрытых, т.е. непосредственно не связанных с внешними выводами, макроячеек (FLASH, MAX5000, MAX7000);
“регистровой упаковкой” (register packing), когда макроячейка имеет два выхода; в случае реализации комбинационной логики один выход используется для формирования функции, а второй - для задействования регистра в цепи обратной связи (MAX9000, FLEX 10K) и др.
Назначение промежуточных шин макроячейкам
Выходы матрицы И называются промежуточными шинами. Они подсоединяются к макроячейкам. Число q промежуточных шин, связанных с одной макроячейкой ограничивает количество элементарных конъюнкций (слагаемых) в дизъюнктивной нормальной форме реализуемой функции. Большое значение q требует значительного увеличения площади кристалла, занимаемого матрицей И, что приводит к удорожанию CPLD и снижению быстродействия устройства. Малое значение q не позволяет реализовать функции, имеющие в ДНФ большое число слагаемых.
Имеется два основных способа назначения промежуточных шин матрицы И выходным макроячейкам: с помощью распределителя (allocator) и с помощью
расширителей (expanders).
С каждой макроячейкой обычно связано некоторое среднее число промежуточных шин (4-5). Если часть или все шины некоторой макроячейки не используются, с помощью распределителя они могут быть назначены другим, обычно соседним макроячейкам. Для этого промежуточные шины матрицы И разбиваются на группы, называемые кластерами, по 2, 3, 4 или 5 шин в каждой группе. Распределитель промежуточных шин оперирует кластерами, переназначая неиспользуемые кластеры тем макроячейкам, которым требуется большее число промежуточных шин.
Расширители делятся на параллельный (parallel) и общий или совместно используемый (shared). Параллельный расширитель позволяет с небольшой задержкой последовательно объединять по ИЛИ промежуточные шины неиспользуемых макроячеек и назначать их требуемой макроячейке. Общий расширитель представляет собой совокупность промежуточных шин, которые одновременно могут использоваться несколькими макроячейками одного PAL-блока. Имеется два способа организации общего расширителя, когда расширитель составляют отдельные, не подсоединенные ни к одной макроячейке промежуточные шины PAL-блока, и когда одна промежуточная шина каждой макроячейки, если она не используется, считается промежуточной шиной общего расширителя.
В устройствах FLEX-логики отсутствует матрица И, поэтому нет понятия промежуточных шин. Однако к каждому логическому элементу от локальной шины подводятся сигналы по отдельным линиям, которые условно можно назвать промежуточными шинами. Для устройств семейства FLEX8000 таких линий 10, 4 их которых служат для подвода обрабатываемых сигналов, а 6 - для сигналов управления. В устройствах семейства FLEX 10K таких линий 11, на один сигнал управления больше.
Макроячейки CPLD
Обычно макроячейки CPLD содержат вентиль ИЛИ, триггер, называемый часто регистром, логику управления и программируемые цепи передачи сигналов. Вентиль ИЛИ содержат все рассматриваемые CPLD, за исключением FLEX-логики, причем в макроячейках устройств семейства XC7300 находится целых три вентиля ИЛИ.
Концепция совокупности двух матриц хорошо себя зарекомендовала при реализации систем булевых функций, представленных в дизъюнктивной нормальной форме. Однако для некоторых функциональных узлов (сумматоры, компараторы, счетчики и др.) получаются слишком сложные логические уравнения и их реализация двумя матрицами не эффективна. Для повышения функциональной мощности в макроячейки CPLD наряду с вентилем ИЛИ и регистром часто вводятся дополнительные элементы, такие как вентиль “исключающее ИЛИ” (MAX, MACH3,4, XC9500), схемы сравнения для реализации компаратора (FLASH), арифметическо-логические устройства (FLEX, XC7300), цепи переноса (FLEX, XC7300) и каскадирования (FLEX). Кроме того, каждое арифметическо-логическое устройство кроме выполнения арифметических операций может работать как функциональный генератор для табличного вычисления логических функций.
На функциональные возможности макроячеек определенное значение также оказывает число обратных связей и точки их подсоединений: вход триггера, выход триггера (инверсный выход триггера) внешний вывод и др. Число обратных связей макроячеек разное для различных CPLD: одна - для MAX9000 и FLEX; две - для
MAX5000 и FLASH; три - для MAX7000, MACH и XC7300. Кроме того, обратные связи устройств MACH2,4,5 могут содержать дополнительный регистр.
Обычно при реализации комбинационной логики триггер обходится и остается незадействованным. С целью повышения степени использования ресурсов макроячейки в устройствах семейств MAX9000 и FLEX 10K имеют два выхода. В этом случае при реализации комбинационной логики один выход служит для формирования выходной функции, а второй выход подключается к цепи обратной связи для использования регистра для реализации скрытой (внутренней) регистровой логики, например, памяти автомата. Подобное свойство носит название регистровой упаковки (register packing).
Устройства семейства XC7300 специально спроектированы для реализации арифметических функций. Поэтому в состав макроячеек этих устройств дополнительно введено одноразрядное арифметическо-логическое устройство (АЛУ), которое также может использоваться в качестве функционального генератора. Кроме того, в XC7300 имеется кольцевая цепь переноса, которая охватывает все макроячейки устройства.
В логических элементах FLEX-логики отсутствуют вентили ИЛИ, но имеется 4- входовой функциональный генератор, который позволяет очень быстро вычислить любую функцию четырех переменных. Данный функциональный генератор имеет четыре режима работы: нормальный, арифметический, реверсивного счетчика и очищаемого счетчика. Все логические элементы FLEX-логики также содержат цепь переноса и цепь каскадирования. Цепь переноса служит для реализации переносов при арифметических вычислениях, а цепь каскадирования предназначена для реализации функций большого числа переменных.
Регистры макроячеек
В качестве регистров макроячеек CPLD используются триггеры различного типа. Основным типом триггера является D-триггер, его поддерживают все CPLD. Другие типы триггеров получаются либо путем программирования, либо путем эмуляции на основе D- триггера, в последнем случае для эмуляции других типов триггеров часто используется вентиль “исключающее ИЛИ”.
|
из
5.00
|
Обсуждение в статье: Методы Изоляции элементов друг от друга в микросхемах 6 страница |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы