 |
Главная |


Нормальное распределение и его значение
|
из
5.00
|
Большинство случайных величин подчиняется определенному закону распределения, зная который можно предвидеть вероятности попадания исследуемой случайной величины в определенный интервал. Такое предсказание весьма желательно при анализе экономических показателей, ведь в этом случае появляется возможность осуществить продуманную политику с учетом возможности возникновения той или иной ситуации. Законов распределения достаточно много, поэтому мы ограничимся рассмотрением лишь тех законов, которые наиболее активно встречаются в экономической теории, особенно в эконометрике.
Одним из наиболее часто встречающихся распределений является нормальное распределение (его еще называют распределением Лапласа-Гаусса, или просто распределением Гаусса.). Оно играет огромную роль в теории вероятностей и ее приложениях.
Плотность нормального распределения имеет вид
 , (2.18)
, (2.18)
а функция нормального распределения имеет вид
 . (2.19)
. (2.19)
Если a=0, s=1, то получим
 , (2.20)
, (2.20)
 (2.21)
(2.21)
стандартное нормальное распределение. Эту функцию можно записать в виде
 ,
,
где
 (2.22)
(2.22)
есть функция Лапласа.
Между произвольной функцией нормального распределения и стандартным распределением (соответственно и функцией Лапласа) существует взаимосвязь:
 . (2.23)
. (2.23)
Для плотности нормального распределения имеем
 . (2.24)
. (2.24)
Для плотности стандартного нормального распределения j(x) и функции Лапласа F(x) существуют обширные таблицы. Однако здесь нужно иметь в виду, что иногда вместо рассмотренных функций используют функци.
 .
.
Отметим, что для нормального распределения
M[X] = a, D[X] = s2,
т.е. нормальное распределение характеризуется двумя параметрами: a, имеющим смысл математического ожидания, и s, имеющим смысл среднего квадратичного отклонения.
Вероятность того, что нормально распределенная случайная величина X примет значение, принадлежащее интервалу (a, b), имеет вид
 . (2.25)
. (2.25)
Вероятность того, что отклонение случайной величины X от математического ожидания по абсолютной величине меньше заданного положительного числа d, равна
 . (2.26)
. (2.26)
В частности, если d=3s, то
P(|X–a|<3s) = 2F(3) = 0,9973.
Это равенство показывает, что во многих практических вопросах при рассмотрении нормального распределения можно пренебречь возможностью отклонения случайной величины от a больше, чем 3s. Это есть т.н. правило «трех сигм».
Например, каждому кто занимался измерениями, встречался с ситуацией, когда появляется «дикое значение». В связи с этим возникает проблема: исключать это значение или его следует оставить. Так, при разработке норматива времени для изготовления одной детали проделали следующие измерения: 5,0; 4,8; 5,2; 5,3; 5,0; 6,1. Последнее число сильно отличается от других. В связи с этим возникает вопрос, не скрыта ли здесь ошибка в измерениях. Вычислим среднее значение  и среднее квадратичное отклонение s=0,46. После этого построим «трехсигмовый» интервал: (4,84; 6,61). Поскольку значение x=6,1 не выходит за пределы трехсигмовой зоны, то его нельзя считать «диким».
и среднее квадратичное отклонение s=0,46. После этого построим «трехсигмовый» интервал: (4,84; 6,61). Поскольку значение x=6,1 не выходит за пределы трехсигмовой зоны, то его нельзя считать «диким».
Пример 2.12. Рост мужчин определенной возрастной категории описывается нормальным закон распределения с математическим ожиданием a=165 см и средним квадратичным отклонением s=5 см. Какую долю костюмов 3-го роста (170-176 см) следует предусмотреть в общем объеме производства для данной возрастной категории?
Решение. Пусть X – рост в сантиметрах представителя данной возрастной категории. Тогда по формуле (2.46), где a=170 см и b=176 см, находим
 .
.
Далее, по таблицам для функции Лапласа, находим
 и
и  .
.
Отметим, что функция Лапласа является нечетной функцией, т.е.  . В результате получаем
. В результате получаем
 ,
,
т.е. доля костюмов 3-го роста должна составлять приблизительно 14,5% общего объема производства для данной категории мужчин. â
Пример 2.13. Коробки с конфетами упаковываются автоматически. Вес коробки – нормально распределенная случайная величина. Известно, что их средний вес равен 540 г, а также что 5% коробок имеют вес, меньший 500 г. Каков процент коробок, вес которых отличается от среднего не более чем на 30 г по абсолютной величине?
Решение. Пусть X – вес коробки, имеющий нормальное распределение с известным параметром a=540 неизвестным параметром s. Среднее квадратичное отклонение s найдем из условия  . Поскольку X – нормально распределенная величина, то
. Поскольку X – нормально распределенная величина, то
 .
.
В результате получаем
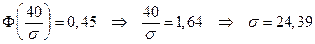 .
.
Тогда
 .
.
Таким образом, приблизительно у 78% коробок вес отличается от среднего значения 540 г не более чем на 30 г. â
Отметим еще одно важное свойство нормального распределения: линейная комбинация произвольного числа нормальных случайных величин имеет нормальное распределение. При этом, если  и
и  – независимые случайные величины, то
– независимые случайные величины, то  , где
, где  и
и  .
.
При изучении теории вероятностей приходится использовать понятия случайного события и случайной величины. При этом нельзя уверенно заранее предсказать результат испытания, в котором может появиться или не появится то или иное событие. Однако при неоднократном повторении испытаний могут наблюдаться определенные закономерности. Суть этих закономерностей заключается в свойстве устойчивости: некоторые характеристики случайных событий и случайных величин при неограниченном увеличении числа испытаний становятся практически не случайными.
Например, любой газ состоит из огромного числа молекул, находящихся в непрерывном хаотическом движении (броуновском движении). Про каждую отдельную молекулу нельзя сказать, с какой скоростью она будет двигаться и в каком направлении. Однако основные характеристики газа – давление, температура, вязкость и др. – определяются не замысловатым поведением одной молекулы, а их совокупным действием. Так, давление газа равно суммарному воздействию молекул, ударившихся о пластину единичной площади в единицу времени. Число ударов и скорости ударившихся молекул меняются от случая к случаю, однако в силу «закона больших чисел» давление – величина постоянная, что подтверждается в физических экспериментах с очень большой точностью.
Для практики очень важно знание условий, при выполнении которых совокупное действие очень многих случайных причин приводит к неслучайному результату. Эти условия указываются в теоремах, носящих название предельных. По смыслу их можно разбить на две группы, одна из которых называется законом больших чисел, а другая – центральной предельной теоремой.
Под законом больших чисел не следует понимать какой-то один общий закон, связанный с большими числами. Закон больших чисел – это обобщенное название нескольких теорем, из которых следует, что при неограниченном увеличении числа испытаний средние величины стремятся к некоторым постоянным величинам. Другими словами, закон больших чисел – это общий принцип, в силу которого совместное действие случайных факторов приводит, при весьма общих условиях, к результату, почти не зависящему от случая и может быть предсказан с большой долей определенности.
Существует много различных теорем, относящихся к группе теорем, носящих название «закона больших чисел». Наиболее важная из них – это теорема Чебышева:
При неограниченном увеличении числа n независимых испытаний «средняя арифметическая наблюдаемых значений случайной величины сходится по вероятности к ее математическому ожиданию»[1], т.е. для любого положительного e
 . (2.27)
. (2.27)
Выражение (2.27), т.е. «сходимость по вероятности», мы также будем обозначать следующим образом
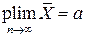
Итак, хотя отдельные значения случайной величины могут принимать значения, далекие от математического ожидания, средняя арифметическая наблюдаемых значений этой случайной величины с возрастанием n с вероятностью, близкой к 1, принимает значения, близкие к постоянному числу, равному математическому ожиданию.
Из теоремы Чебышева вытекает весьма важный практический вывод. Он состоит в том, что неизвестное нам значение математического ожидания случайной величины мы вправе заменить средним арифметическим значением, полученным по достаточно большому числу опытов. При этом, чем больше проведено опытов для вычисления, тем с большей вероятностью (надежностью) можно ожидать, что связанная с этой заменой ошибка  не превзойдет заданную величину e. Отметим, что закон больших чисел является обоснованием выборочного метода, являющегося одним из основным методов статистики.
не превзойдет заданную величину e. Отметим, что закон больших чисел является обоснованием выборочного метода, являющегося одним из основным методов статистики.
Теоремы закона больших чисел касаются вопросов приближения некоторых случайных величин к определенным предельным значениям, независимо от их закона распределения. Другая группа теорем, относящихся к центральной предельной теореме, устанавливают связь между законом распределения суммы случайных величин и нормальным распределением. Суть центральной предельной теоремы заключается в следующем:
Если случайная величина X представляет собой сумму очень большого числа независимых случайных величин, влияние каждой из которых на всю сумму ничтожно мало, то X имеет распределение, близкое к нормальному.
Исключительная важность центральной предельной теоремы объясняется тем, что она дает теоретическое объяснение следующему, многократно подтвержденному практикой, наблюдению: если исход случайного эксперимента определяется большим числом случайных факторов, влияние каждого из которых пренебрежимо мало, то такой эксперимент хорошо аппроксимируется нормальным распределением с соответствующим образом подобранными математическим ожиданием и дисперсией.
Центральная предельная теорема имеет огромное практическое значение, поскольку многие случайные величины можно рассматривать как сумму отдельных независимых слагаемых. Например, ошибки различных измерений, отклонения размеров деталей, изготовляемых при неизменном технологическом режиме, распределение числа продаж некоторого товара, объемов прибыли от реализации однородного товара различными производителями, валютные курсы, рост, вес животных и растений данного вида, отклонения точки падения снаряда от цели и т.д. могут рассматриваться как суммарный результат большого числа слагаемых и потому приближенно следовать нормальному закону распределения.
Приведем две простейшие теоремы, относящиеся к центральным предельным теоремам. Пусть {Xn} – последовательность взаимно независимых случайных величин, имеющих конечные математические ожидания M[Xi]=ai и дисперсии D[Xi]=si2. Введем обозначение  .
.
Теорема Ляпунова. Если для последовательности взаимно независимых случайных величин {Xn} выполняется условие (условие Ляпунова):
 , (2.28)
, (2.28)
то для функции распределения Fn(x) нормированной суммы
 (2.29)
(2.29)
имеет место равенство
 .
.
Более простой вид имеет следующая теорема.
Теорема Леви-Линдеберга. Если независимые случайные величины {Xn} имеют одинаковые функции распределения, где M[Xi]=a, D[Xi]=s2, то функция Fn(x) нормированной суммы:
 (2.30)
(2.30)
имеет место равенство
.
Дополнение 1.
ИСТОРИЯ РАЗВИТИЯ ЭКОНОМЕТРИКИ
Как наука эконометрика прошла сложный путь зарождения и выделения в самостоятельную область знания. Первые работы по эконометрике появились в конце XIX-начале XX веков. В 1897 г. появилась работа одного из основателей математической школы в экономической теории В. Парето, посвященная статистическому изучению доходов населения в разных странах. В самом начале XX в. вышло несколько работ английского статистика Гукера, в которых он применил корреляционно-регрессионные методы, разработанные Ч. Пирсоном и его школой, для изучения взаимосвязей экономических показателей, в частности – влияния числа банкротств на товарной бирже на цену зерна. В дальнейшем появилось огромное число работ как по развитию теории математической статистики, так и по практическому применению этих методов в экономическом анализе. К началу 30-х годов XX в. сложились предпосылки для выделения эконометрики в отдельную науку. К этому времени был накоплен большой материал по использованию математических и статистических методов в экономической теории.
В 1912 г. И. Фишер попытался создать группу ученых для стимулирования развития экономической теории путем ее связи со статистикой и математикой. Но тогда эту группу создать не удалось. В 1930 г. по инициативе И. Фишера (1867-1947), Р. Фриша (1895-1973), Я. Тинбергера (1903-1995), Й. Шумпетера (1883-1950), О. Андерсена (1887-1960) и других ученых на заседании Американской ассоциации развития науки (США) было создано эконометрическое общество, на котором норвежский ученый Р. Фриш дал новой науке название – "эконометрика". С 1933 г. под редакцией Р. Фриша стал издаваться журнал "Эконометрика", который и сейчас играет важную роль в развитии эконометрической науки. В 1941 г. появился первый учебник по эконометрике, который был создан Я. Тинбергером.
С тех пор эконометрика бурно развивалась. Свидетельством всемирного признания эконометрики стало присуждение премий по эконометрике за разработки в этой области: премия 1969 г. была присуждена Р. Фришу и Я. Тинбергену за разработку математических методов анализа экономических моделей; премия 1980 г. – Л. Клейну за создание эконометрических моделей и их применение к анализу экономических колебаний и экономической политике; премия 1981 г. – Дж. Тобин за анализ финансовых рынков и их взаимосвязи с расходами, занятостью и ценами; его главный вклад в эконометрику состоит в создании регрессии с цензурированной зависимой переменной, которую по его имени называют тобит.
Премия 1989 г. – Т. Хаавельмо за прояснение вероятностных основ эконометрики и анализ одновременных экономических структур. Он продемонстрировал, что если формулировать экономические теории в терминах теории вероятностей, то можно применять методы статистического оценивания для проверки экономических теорий и использования их в прогнозировании. Он также указал, что из-за взаимосвязи экономических переменных следует оценивать такие соотношения как систему (т.е. использовать системы одновременных уравнений).
Премия 1995 г. – Р. Лукас за развитие и применение гипотезы рациональных ожиданий и трансформацию макроэкономического анализа с помощью этой гипотезы. Основной вклад Лукаса в эконометрику получил название «критики Лукаса». Он показал, что обычные способы оценивания макроэкономических функций, описывающих поведение неправительственного сектора экономики, дают неадекватные результаты из-за применения режимов экономической политики. Он также предложил способ решения этой проблемы.
Премия 2000 г. – Дж. Хекману за развитие теории и методов анализа селективных выборок и Д. Макфаддену за развитие теории и методов анализа моделей дискретного выбора, т.е. выбора решения из конечного числа альтернатив.
Премия 2003 г. – Р. Энглу за методу анализа экономических временных рядов с меняющейся волативностью и К. Грейнджер за методы анализа экономических временных рядов с общими трендами (коинтеграция). Грейнждер создал метод статистического анализа, позволяющий отслеживать потенциальные долгосрочные связи, скрытые краткосрочными колебаниями. Он ввел термин «коинтеграция» для обозначения стационарной комбинации нестационарных переменных. Грейджер и Энгл разработали методы для практического приложения концепции коинтеграции. Предложенные Энглом методы учёта волатильности получили наиболее широкое применение при анализе финансовых рынков.
Широкому внедрению эконометрических методов способствовало появление во второй половине XX в. электронных вычислительных машин и в частности персональных компьютеров. Компьютерные эконометрические пакеты сделали эти методы более доступными и наглядными, т.к. наиболее трудоемкую (рутинную) работу по расчету различных статистик, параметров, характеристик, построению таблиц и графиков в основном стал выполнять компьютер.
Дополнение 2.
ЗАКОНЫ РАСПРЕДЕЛЕНИЙ, СВЯЗАННЫХ С НОРМАЛЬНЫМ
Распределение Пирсона (c2-распределение)
Пусть независимые случайные величины U1, U2, …, Uk описываются стандартным нормальным распределением:  . Тогда распределение суммы квадратов этих величин
. Тогда распределение суммы квадратов этих величин
 (2.31)
(2.31)
называется c2 распределением Пирсона с k степенями свободы (читается «хи-квадрат»).В явном виде плотность функции этого распределения имеет вид
 (2.32)
(2.32)
где  – гамма-функция; в частности, G(n+1)=n!.
– гамма-функция; в частности, G(n+1)=n!.
Распределение Пирсона определяется одним параметром – числом степеней свободы k. Числовые характеристики распределения Пирсона:

Если случайные величины c2(k1) и c2(k2) независимы, то
 .
.
Отметим, что с увеличением числа степеней свободы распределение Пирсона постепенно приближается к нормальному.
Распределение Пирсона применяется для нахождения интервальных оценок и проверки статистических гипотез. При этом активно используется таблица критических точек c2-распределения. В таблицах для распределения Пирсона обычно в левом столбце приведены различные числа степеней свободы k. В верхней строчке указаны вероятности (уровни значимости) a попадания рассматриваемой величины в «правый хвост» распределения c2 (см. рис. 2.2,а).
|
|
|
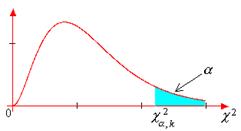
 |
Критическая точка
 отыскивается на пересечении столбца с заданной вероятностью a и строки, соответствующей числу степеней свободы k. Например,
отыскивается на пересечении столбца с заданной вероятностью a и строки, соответствующей числу степеней свободы k. Например,  . Другими словами,
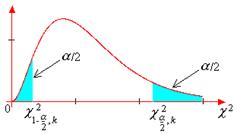
. Другими словами,  . Отметим, что часто таблицы приводятся для двусторонних критических точек
. Отметим, что часто таблицы приводятся для двусторонних критических точек  и
и  . В этом случае предполагается, что вероятности попадания рассматриваемой случайной величины c2 в оба «хвоста» распределения одинаковы и равны половине уровня значимости a, т.е. a/2 (рис.2.2,б).
. В этом случае предполагается, что вероятности попадания рассматриваемой случайной величины c2 в оба «хвоста» распределения одинаковы и равны половине уровня значимости a, т.е. a/2 (рис.2.2,б).
Распределение Стьюдента (t-распределение)
Пусть U –стандартная нормально распределенная случайная величина, U=N(0,1), а c2 – случайная величина, имеющая c2-распределение с k степенями свободы, причем U и c2 независимые величины. Тогда распределение величины
 (2.33)
(2.33)
называется распределением Стьюдента (t-распределением) с k степенями свободы. В явном виде плотность функции распределения Стьюдента имеет вид
 (2.34)
(2.34)
Числовые характеристики распределения Стьюдента:

Отметим, что с возрастанием числа степеней свободы распределение Стьюдента быстро приближается к нормальному, причем при n>30 распределение Стьюдента
Распределение Стьюдента применяется для нахождения интервальных оценок, а также при проверке статистических гипотез. При этом активно используется таблица критических точек распределения Стьюдента. В таблицах для распределения Стьюдента обычно в левом столбце указаны числа степеней свободы k, а в верхней строчке – вероятности (уровни значимости) a попадания рассматриваемой величины в «правый хвост» распределения Стьюдента (см. рис. 2.3,а).
|
|
|


 |
Критическая точка
 отыскивается на пересечении столбца с заданной вероятностью a и строки, соответствующей числу степеней свободы k. Например,
отыскивается на пересечении столбца с заданной вероятностью a и строки, соответствующей числу степеней свободы k. Например,  . Другими словами,
. Другими словами,  .
.
Отметим, что иногда таблицы распределения Стьюдента приводятся для двусторонних критических точек  , определяемых из условия
, определяемых из условия  (рис.2.3,б).
(рис.2.3,б).
Распределение Фишера (F-распределение)
Пусть c2(k1) и c2(k2) – независимые случайные величины, имеющие c2-распределение соответственно с k1 и k2 степенями свободы. Распределение величины
 (2.35)
(2.35)
называется распределением Фишера (F-распределением) со степенями свободы k1 и k2. В явном виде плотность распределения Фишера имеет вид
 (2.38)6
(2.38)6
Распределение Фишера определяется двумя параметрами – числами степеней свободы k1 и k2. Числовые характеристики распределения Фишера:

Отметим, что между случайными величинами, имеющими нормальное распределение, распределение Пирсона, Стьюдента и Фишера, имеют место соотношения:

Распределение Фишер используется при проверке статистических гипотез, в дисперсионном и регрессионном анализах. При этом активно используется таблица критических точек распределения Фишера. Таблицы критических точек распределения Фишера обычно приводятся для различных значений вероятности (уровня значимости) a попадания рассматриваемой величины в «правый хвост» распределения Фишера (см. рис. 2.4).
 |

Критическая точка  отыскивается в таблице с заданной вероятностью a на пересечении столбца и строки, соответствующих числам степеней свободы k1 и k2. Например,
отыскивается в таблице с заданной вероятностью a на пересечении столбца и строки, соответствующих числам степеней свободы k1 и k2. Например,  . Другими словами,
. Другими словами,  .
.
|
из
5.00
|
Обсуждение в статье: Нормальное распределение и его значение |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы