 |
Главная |


Оптимальные деревья поиска
|
из
5.00
|
Встречаются ситуации, в которых можно получить информацию о вероятности обращений к отдельным ключам. Обычно в таких случаях дерево поиска строится один раз, имеет неизменяемую структуру, в него не включаются новые ключи, и из него не исключаются существующие ключи. Примером соответствующего приложения является сканер компилятора, одной из задач которого является определение принадлежности очередного идентификатора к набору ключевых слов языка программирования. На основе сбора статистики при многочисленной компиляции программ можно получить достаточно точную информацию о частотах поиска по отдельным ключам.
Пусть дерево поиска содержит n вершин, и обозначим через pi вероятность обращения к i-той вершине, содержащей ключ ki. Сумма всех pi, естественно, равна 1. Постараемся теперь организовать дерево поиска таким образом, чтобы обеспечить минимальность общего числа шагов поиска, подсчитанного для достаточно большого количества обращений. Будем считать, что корень дерева имеет высоту 1 (а не 0, как раньше), и определим взвешенную длину пути дерева как сумму pi*hi (1<=i<=n), где hi - длина пути от корня до i-той вершины. Требуется построить дерево поиска с минимальной взвешенной длиной пути.
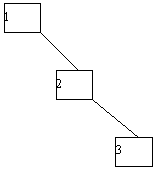
В качестве примера рассмотрим возможности построения дерева поиска для трех ключей 1, 2, 3 с вероятностями обращения к ним 1/7, 2/7 и 4/7 соответственно (рисунок 25).
Посчитаем взвешенную длину пути для каждого случая. В случае (a) взвешенная длина пути P(a) = 1*4/7 + 2*2/7 + 3*1/7 = 11/7. Аналогичные подсчеты дают результаты P(b)=12/7; P(c)=12/7; P(d)=15/7; P(e)=17/7. Следовательно, оптимальным в интересующем нас смысле оказалось не идеально сбалансированное дерево (c), а вырожденное дерево (a).

 На практике приходится решать несколько более общую задачу, а именно, при построении дерева учитывать вероятности неудачного поиска, т.е. поиска ключа, не включенного в дерево.
На практике приходится решать несколько более общую задачу, а именно, при построении дерева учитывать вероятности неудачного поиска, т.е. поиска ключа, не включенного в дерево.



a) (b) (c) (d) (e)
Рисунок 25 -
При построении дерева оптимального поиска вместо значений pi и qj обычно используют полученные статистически значения числа обращений к соответствующим вершинам. Процедура построения дерева оптимального поиска достаточно сложна и опирается на тот факт, что любое поддерево дерева оптимального поиска также обладает свойством оптимальности. Поэтому известный алгоритм строит дерево "снизу-вверх", т.е. от листьев к корню. Сложность этого алгоритма и расходы по памяти составляют O(n2). Имеется эвристический алгоритм, дающий дерево, близкое к оптимальному, со сложностью O(n*log n) и расходами памяти - O(n).
|
из
5.00
|
Обсуждение в статье: Оптимальные деревья поиска |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы