 |
Главная |


Алгоритмы обучения без учителя
|
из
5.00
|
Алгоритм WTA
Алгоритмы обучения, используемые для обучения нейронных сетей Кохонена, называются алгоритмами обучения без учителя. Подобные алгоритмы применяются в тех случаях, когда нет эталонных выходных значений для входных векторов.
Целью обучения сети с самоорганизацией на основе конкуренции, считается такое упорядочение нейронов, которое минимизирует значение отклонения вектора весов от входного вектора x. При p входных векторах x эта погрешность в эвклидовой метрике может быть выражена в виде:
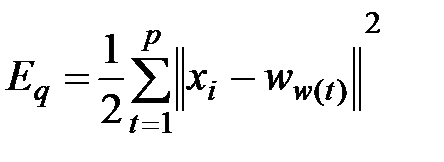 , (3.13)
, (3.13)
где  - это вес нейрона-победителя при предъявлении вектора
- это вес нейрона-победителя при предъявлении вектора  .
.
Этот подход также называется векторным квантованием (VQ). Номера нейронов-победителей при последовательном предъявлении векторов xобразуют так называемую кодовую таблицу. При классическом решении задачи кодирования применяется алгоритм K-усреднений, носящий имя обобщенного алгоритма Ллойда.
Для нейронных сетей аналогом алгоритма Ллойда считается алгоритм WTA(WinnerTakesAll – победитель получает все). В соответствии с ним после предъявления вектора x рассчитывается активность каждого нейрона. Победителем признается нейрон с самым сильным выходным сигналом, то есть тот, для которого скалярное произведение  оказывается наибольшим, что для нормализованных векторов равнозначно наименьшему эвклидову расстоянию между входным вектором и вектором весов нейронов. Победитель получает право уточнить свои веса в направлении вектора x согласно правилу
оказывается наибольшим, что для нормализованных векторов равнозначно наименьшему эвклидову расстоянию между входным вектором и вектором весов нейронов. Победитель получает право уточнить свои веса в направлении вектора x согласно правилу
 (3.14)
(3.14)
Веса остальных нейронов уточнению не подлежат. Алгоритм позволяет учитывать усталость нейронов путем подсчета количества побед каждого из них и поощрять элементы с наименьшей активностью для выравнивания их шансов.
Помимо алгоритмов WTA, в которых в каждой итерации может обучаться только один нейрон, для обучения сетей с самоорганизацией широко применяется алгоритмы типа WTM (WinnerTakesMost – победитель получает больше), в которых, кроме победителя, уточняют значения своих весов и нейроны из его ближайшего окружения. При этом, чем дальше какой-либо нейрон находится от победителя, тем меньше изменяются его веса. Процесс уточнения вектора весов может быть определен в виде
 (3.15)
(3.15)
для всех i нейронов, расположенных в окрестности победителя. В приведенной формуле коэффициент обучения  каждого нейрона отделен от его расстояния до предъявленного вектора x функцией
каждого нейрона отделен от его расстояния до предъявленного вектора x функцией  . Если
. Если 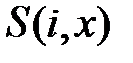 определяется в форме
определяется в форме
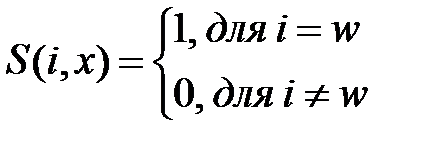 , (3.16)
, (3.16)
для wобозначает номер победителя, то мы получаем классический алгоритм WTA. Существует множество вариантов алгоритма WTM, отличающихся ,прежде всего формой функции . Для дальнейшего обсуждения выберем классический алгоритм Кохонена.
Алгоритм Кохонена
Алгоритм Кохонена относится к наиболее старым алгоритмам обучения сетей с самоорганизацией на основе конкуренции, и в настоящее время существуют различные его версии [4]. В классическом алгоритме Кохонена сеть инициализируется путем приписывания нейронам определенных позиций в пространстве и связывании их с соседями на постоянной основе. В момент выбора победителя уточняются не только его веса, но также веса и его соседей, находящихся в ближайшей окрестности. Таким образом, нейрон-победитель подвергается адаптации вместе со своими соседями.
 , (3.17)
, (3.17)
В этом выражении  может обозначать как эвклидово расстояние между векторами весов нейрона-победителя
может обозначать как эвклидово расстояние между векторами весов нейрона-победителя  и
и 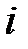 -го нейрона, так и расстояние, измеряемое количеством нейронов.
-го нейрона, так и расстояние, измеряемое количеством нейронов.
Другой тип соседства в картах Кохонена- это соседство гауссовского типа, при котором функция определяется формулой
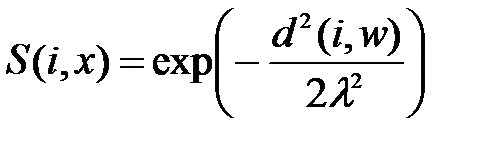 . (3.18)
. (3.18)
Уточнение весов нейронов происходит по правилу:
 . (3.19)
. (3.19)
Степень адаптации нейронов-соседей определяется не только эвклидовым расстоянием между i-м нейроном и нейроном-победителем (w-м нейроном)  , но также уровнем соседства
, но также уровнем соседства  . Как правило, гауссовское соседство дает лучшие результаты обучения и обеспечивает лучшую организацию сети, чем прямоугольное соседство.
. Как правило, гауссовское соседство дает лучшие результаты обучения и обеспечивает лучшую организацию сети, чем прямоугольное соседство.
Рекуррентные сети
Общие положения
Отдельную группу нейронных сетей составляют сети с обратной связью между различными слоями нейронов. Это так называемые рекуррентные сети. Их общая черта состоит в передаче сигналов с выходного либо скрытого слоя во входной слой.Главная особенность таких сетей – динамическая зависимость на каждом этапе функционирования. Изменение состояния одного нейрона отражается на всей сети вследствие обратной связи типа «один ко многим». В сети возникает переходный процесс, который завершается формированием нового устойчивого состояния, отличающегося в общем случае от предыдущего [4].
Другой особенностью рекуррентных сетей является тот факт, что для них не подходит ни обучение с учителем, ни обучение без учителя. В таких сетях весовые коэффициенты синапсов рассчитываются только однажды перед началом функционирования сети на основе информации об обрабатываемых данных, и все обучение сети сводится именно к этому расчету.
С одной стороны, предъявление априорной информации можно расценивать, как помощь учителя, но с другой – сеть фактически просто запоминает образцы до того, как на ее вход поступают реальные данные, и не может изменять свое поведение, поэтому говорить о звене обратной связи с учителем не приходится.
Из сетей с подобной логикой работы наиболее известны сеть Хопфилда и сеть Хемминга, которые обычно используются для организации ассоциативной памяти. Ассоциативная память играет роль системы, определяющей взаимную зависимость векторов. В случае, когда на взаимозависимость исследуются компоненты одного и того же вектора, говорят об ассоциативной памяти. Если же взаимозависимыми оказываются два различных вектора, можно говорить о памяти гетероассоциативного типа. Типичным представителем первого класса является сеть Хопфилда, а второго – сеть Хемминга.
Главная задача ассоциативной памяти сводится к запоминанию входных обучающих выборок таким образом, чтобы при представлении новой выборки система могла сгенерировать ответ, – какая из запомненных ранее выборок наиболее близка к вновь поступившему образу. Наиболее часто в качестве меры близости отдельных векторов применяется мера Хемминга.
При использовании двоичных значений  расстояние Хемминга между двумя векторами
расстояние Хемминга между двумя векторами  и
и  определяется в виде [4]:
определяется в виде [4]:
 . (4.1)
. (4.1)
При биполярных 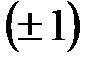 значениях элементов обоих векторов расстояние Хемминга рассчитывается по формуле:
значениях элементов обоих векторов расстояние Хемминга рассчитывается по формуле:
 . (4.2)
. (4.2)
Мера Хемминга равна нулю только тогда, когда 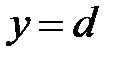 . В противном случае она равна количеству битов, на которое различаются оба вектора.
. В противном случае она равна количеству битов, на которое различаются оба вектора.
Сеть Хопфилда
Обобщенная структура сети Хопфилда представляется, как правило, в виде системы с непосредственной обратной связью выхода с входом (рис. 4.1) [4]. Характерная особенность такой системы состоит в том, что выходные сигналы нейронов являются одновременно входными сигналами сети:
 (4.3)
(4.3)
В классической системе Хопфилда отсутствует связь нейрона с собственным выходом, что соответствует  , а матрица весов является симметричной
, а матрица весов является симметричной  . Процесс обучения сети формирует зоны притяжения некоторых точек равновесия, соответствующих обучающим данным.
. Процесс обучения сети формирует зоны притяжения некоторых точек равновесия, соответствующих обучающим данным.
Сеть Хопфилда состоит из единственного слоя нейронов, число которых является одновременно числом входов и выходов сети. Каждый нейрон связан синапсами со всеми остальными нейронами, а также имеет один входной синапс, через который осуществляется ввод сигнала. В качестве функции активации нейронов сети Хопфилда будем использовать знаковую функцию, хотя для сетей Хопфилда также можно использовать пороговую функцию, линейную функцию с насыщением или сигмоидальные функции активации.
| 1 |
| wN2 |
| wNN |
| wN1 |
| w2N |
| w22 |
| w21 |
| w1N |
| w11 |
| w12 |
| w20 |
| wN0 |
| w10 |
| yN |
| y2 |
| y1 |
| z-1 |
| z-1 |
| z-1 |
| 1 |
| 1 |
Рисунок4.1 Обобщенная структура сети Хопфилда
Это означает, что выходной сигнал  нейрона определяется функцией:
нейрона определяется функцией:
 , (4.4)
, (4.4)
где  обозначает число нейронов.
обозначает число нейронов.
Будем считать, что пороговые элементы являются компонентами вектора  . Без учета единичных задержек сети, представляющих собой способ синхронизации процесса передачи сигналов, основные зависимости, определяющие сеть Хопфилда, можно представить в виде:
. Без учета единичных задержек сети, представляющих собой способ синхронизации процесса передачи сигналов, основные зависимости, определяющие сеть Хопфилда, можно представить в виде:
 , (4.5)
, (4.5)
с начальным условием 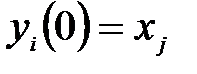 . В процессе функционирования сети Хопфилда можно выделить два режима: обучения и классификации. В режиме обучения на основе известных обучающих выборок
. В процессе функционирования сети Хопфилда можно выделить два режима: обучения и классификации. В режиме обучения на основе известных обучающих выборок 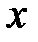 подбираются весовые коэффициенты
подбираются весовые коэффициенты 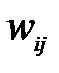 . В режиме классификации при зафиксированных значениях весов и вводе конкретного начального состояния нейронов
. В режиме классификации при зафиксированных значениях весов и вводе конкретного начального состояния нейронов  возникает переходной процесс, протекающий в соответствии с выражением (4.5) и завершающийся в одном из локальных минимумов, для которого
возникает переходной процесс, протекающий в соответствии с выражением (4.5) и завершающийся в одном из локальных минимумов, для которого 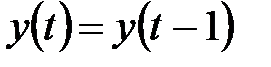 .
.
При вводе только одной обучающей выборки  процесс изменений продолжается до тех пор, пока зависимость (4.5) не начнет соблюдаться для всех
процесс изменений продолжается до тех пор, пока зависимость (4.5) не начнет соблюдаться для всех  нейронов. Это условие автоматически выполняется в случае выбора значений весов, соответствующих отношению
нейронов. Это условие автоматически выполняется в случае выбора значений весов, соответствующих отношению
 , (4.6)
, (4.6)
поскольку только тогда  (вследствие биполярных значений элементов вектора
(вследствие биполярных значений элементов вектора  всегда выполняется соотношение
всегда выполняется соотношение 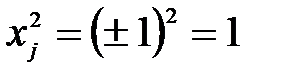 ). Следует отметить, что зависимость (4.6) представляет собой правило обучения Хебба. При вводе большого числа обучающих выборок
). Следует отметить, что зависимость (4.6) представляет собой правило обучения Хебба. При вводе большого числа обучающих выборок 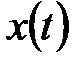 для
для  веса
веса  подбираются согласно обобщенному правилу Хебба, в соответствии с которым
подбираются согласно обобщенному правилу Хебба, в соответствии с которым
 . (4.7)
. (4.7)
Благодаря такому режиму обучения веса принимают значения, определяемые усреднением множества обучающих выборок.
В случае множества обучающих выборок становится актуальным фактор стабильности ассоциативной памяти. Для стабильного функционирования сети необходимо, чтобы реакция  -го нейрона
-го нейрона  на
на  -ю обучающую выборку
-ю обучающую выборку  совпадала с ее
совпадала с ее  -й составляющей
-й составляющей  . Это означает, что с учетом выражения (4.7) получим
. Это означает, что с учетом выражения (4.7) получим
 . (4.8)
. (4.8)
Если взвешенную сумму входных сигналов  -го нейрона обозначить
-го нейрона обозначить 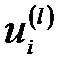 , то можно выделить в ней ожидаемое значение
, то можно выделить в ней ожидаемое значение  и остаток, называемый диафонией [2]:
и остаток, называемый диафонией [2]:
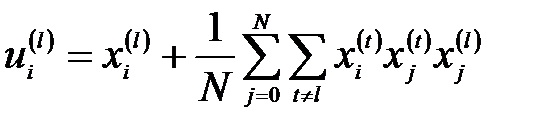 . (4.9)
. (4.9)
Вследствие применения знаковой функции активации, выполнение условия (4.8) возможно при малых значениях диафонии, не способных изменить знак  . Это означает, что, несмотря на определенное несовпадение битов, переходный процесс завершается в нужной точке притяжения. При предоставлении тестовой выборки, отличающейся некоторым количеством битов, нейронная сеть может откорректировать эти биты и завершить процесс классификации в нужной точке притяжения.
. Это означает, что, несмотря на определенное несовпадение битов, переходный процесс завершается в нужной точке притяжения. При предоставлении тестовой выборки, отличающейся некоторым количеством битов, нейронная сеть может откорректировать эти биты и завершить процесс классификации в нужной точке притяжения.
Тем не менее, правило Хебба обладает невысокой продуктивностью. Максимальная емкость ассоциативной памяти (число запомненных образцов) при обучении по правилуХебба с допустимой погрешностью 1%, составляет примерно 14% от числа нейронов сети [4]. Кроме того, при наличии шума, применение правила Хебба приводит к различным неточностям в виде локальных минимумов, далеких от исходного решения. Поэтому в качестве альтернативы используют методы обучения, основанные на псевдоинверсии.
Идея этого метода состоит в том, что при правильно подобранных весах, каждая поданная на вход выборка  генерирует на выходе саму себя, мгновенно приводя к исходному состоянию (зависимость (4.5)) [2]. В матричной форме это можно представить в виде:
генерирует на выходе саму себя, мгновенно приводя к исходному состоянию (зависимость (4.5)) [2]. В матричной форме это можно представить в виде:
 , (4.10)
, (4.10)
где  - матрица весов сети размерностью
- матрица весов сети размерностью  , а
, а 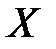 - прямоугольная матрица размерностью
- прямоугольная матрица размерностью  , составленная из
, составленная из  последовательных обучающих векторов
последовательных обучающих векторов  , то есть
, то есть  . Решение такой линейной системы уравнений имеет вид:
. Решение такой линейной системы уравнений имеет вид:
 , (4.11)
, (4.11)
где знак + обозначает псевдоинверсию. Если обучающие векторы линейно независимы, последнее выражение можно представить в форме:
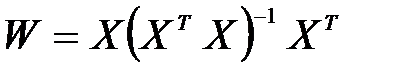 . (4.12)
. (4.12)
Псевдоинверсия матрицы размерностью  в этом выражении заменена обычной инверсией квадратной матрицы
в этом выражении заменена обычной инверсией квадратной матрицы 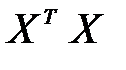 размерностью
размерностью 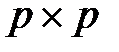 . Дополнительное достоинство выражения (4.12) – возможность записать его в итерационной форме, не требующей расчета обратной матрицы. В этом случае выражение (4.12) принимает вид функциональной зависимости от последовательности обучающих векторов
. Дополнительное достоинство выражения (4.12) – возможность записать его в итерационной форме, не требующей расчета обратной матрицы. В этом случае выражение (4.12) принимает вид функциональной зависимости от последовательности обучающих векторов  для
для  :
:
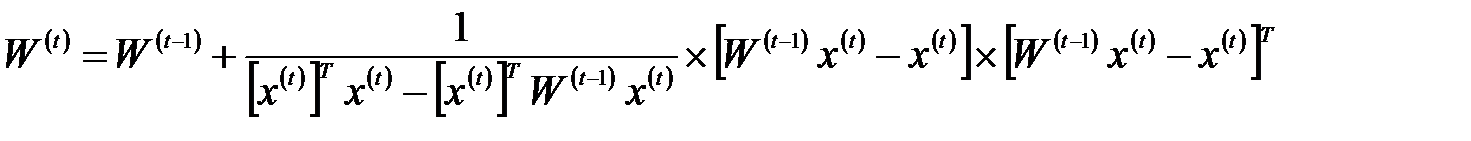
(4.13)
при начальных условиях  . Такая форма предполагает однократное предъявление всех обучающих выборок, в результате чего матрица весов принимает значение
. Такая форма предполагает однократное предъявление всех обучающих выборок, в результате чего матрица весов принимает значение  . Зависимости (4.12) и (4.13) называются методом проекций. Применение метода псевдоинверсии увеличивает максимальную емкость сети Хопфилда, которая становится равной
. Зависимости (4.12) и (4.13) называются методом проекций. Применение метода псевдоинверсии увеличивает максимальную емкость сети Хопфилда, которая становится равной 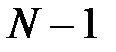 .
.
Модифицированный вариант метода проекций – метод  проекций – это градиентная форма алгоритма минимизации целевой функции. В соответствии с этим способом веса подбираются рекуррентно с помощью циклической процедуры, повторяемой для всех обучающих выборок:
проекций – это градиентная форма алгоритма минимизации целевой функции. В соответствии с этим способом веса подбираются рекуррентно с помощью циклической процедуры, повторяемой для всех обучающих выборок:
 . (4.14)
. (4.14)
Коэффициент  - это коэффициент обучения, выбираемый обычно из интервала [0.7 – 0.9]. Процесс обучения завершается, когда изменение вектора весов становится меньше априорно принятого значения
- это коэффициент обучения, выбираемый обычно из интервала [0.7 – 0.9]. Процесс обучения завершается, когда изменение вектора весов становится меньше априорно принятого значения  .
.
По завершении подбора весов сети их значения «замораживаются», и сеть можно использовать в режиме распознавания. В этой фазе на вход сети подается тестовый вектор 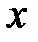 и рассчитывается ее отклик в виде:
и рассчитывается ее отклик в виде:
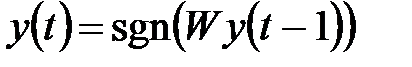 (4.15)
(4.15)
(в начальный момент  ), причем итерационный процесс повторяется для последовательных значений
), причем итерационный процесс повторяется для последовательных значений  вплоть до стабилизации отклика.
вплоть до стабилизации отклика.
В процессе распознавания образа по зашумленным сигналам, образующим начальное состояние нейронов, возникают проблемы с определением конечного состояния, соответствующего одному из запомненных образов. Возможны ошибочные решения. Одной из причин нахождения ошибочных решений является возможность перемешивания различных компонентов запомненных образов и формирования стабильного состояния, воспринимаемого как локальный минимум.
Сеть Хемминга
Сеть Хемминга – это трехслойная рекуррентная структура, которую можно считать развитием сети Хопфилда, была предложена Р. Липпманом. Она позиционируется как специализированное гетероассоциативное запоминающее устройство. Основная идея функционирования сети состоит в минимизации расстояния Хемминга между тестовым вектором, подаваемым на вход сети, и векторами обучающих выборок, закодированными в структуре сети. Обобщенная структура сети Хемминга представлена на рисунке4.2. [4].
Первый ее слой имеет однонаправленное распространение сигналов от входа к выходу и фиксированные значения весов. Второй слой, MAXNET, состоит из нейронов, связанных обратными связями по принципу «каждый с каждым», при этом в отличие от структуры Хопфилда существует ненулевая связь входа нейрона со своим собственным выходом. Веса нейронов в слое MAXNET постоянны. Разные нейроны связаны отрицательной обратной связью с весом  , при этом обычно величина
, при этом обычно величина 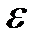 обратно пропорциональна числу образов.
обратно пропорциональна числу образов.
С собственным выходом нейрон связан положительной обратной связью с весом +1. Веса пороговых элементов равны нулю. Нейроны этого слоя функционируют в режиме WTA, при котором в каждой фиксированной ситуации активизируется только один нейрон.
Выходной однонаправленный слой формирует выходной вектор, в котором только один нейрон имеет выходное значение, равное 1, а все остальные – равные 0.
| y1 |
| yM |
| y2 |
| х1 |
| х2 |
| xN |
| w(m) |
| w(2) |
| Слой MAXNET |
| w(1) |
Рисунок4.2 Обобщенная структура сети Хемминга
Веса первого слоя соответствуют входным векторам-образцам 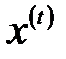 , поэтому
, поэтому  для
для 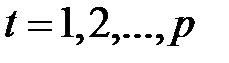 , i=t,
, i=t, 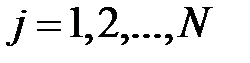 , то есть веса первого нейрона запоминают компоненты первого входного вектора. Веса второго нейрона – компоненты второго вектора и т. д.
, то есть веса первого нейрона запоминают компоненты первого входного вектора. Веса второго нейрона – компоненты второго вектора и т. д.
Аналогично веса выходного слоя соответствуют очередным векторам образов  ,
,  , i,t,l=1,2,…p.
, i,t,l=1,2,…p.
В случае нейронов слоя MAXNET, функционирующих в режиме WTA, веса сети должны усиливать собственный сигнал нейрона и ослаблять остальные сигналы. Для достижения этого принимается  , а также
, а также
 (4.16)
(4.16)
для  . Для обеспечения абсолютной сходимости алгоритма веса
. Для обеспечения абсолютной сходимости алгоритма веса  должны отличать друг от друга. Р. Липпман в своей работе принял
должны отличать друг от друга. Р. Липпман в своей работе принял
 , (4.17)
, (4.17)
где  - случайная величина с достаточно малой амплитудой.
- случайная величина с достаточно малой амплитудой.
В процессе функционирования сети в режиме распознавания можно выделить три фазы. В первой из них на вход подается N-элементный вектор х. После предъявления этого вектора на выходах нейронов первого слоя генерируются сигналы, задающие начальные состояния нейронов второго слоя. Нейроны первого слоя рассчитывают расстояния Хемминга между поданными на вход сети вектором  и векторами весов
и векторами весов 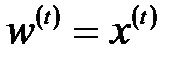 отдельных нейронов этого слоя. Значения выходных сигналов этих нейронов определяются по формуле:
отдельных нейронов этого слоя. Значения выходных сигналов этих нейронов определяются по формуле:
 , (4.18)
, (4.18)
где 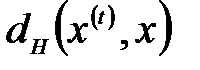 обозначает расстояние Хемминга между входными векторами
обозначает расстояние Хемминга между входными векторами  и
и  , то есть число битов, на которое различаются эти два вектора. Значение
, то есть число битов, на которое различаются эти два вектора. Значение 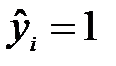 , если
, если 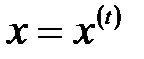 , и
, и  , если
, если  . В остальных случаях значения
. В остальных случаях значения  лежат в интервале [0, 1].
лежат в интервале [0, 1].
Сигналы  нейронов первого слоя становятся начальными состояниями нейронов слоя MAXNET на второй фазе функционирования сети.
нейронов первого слоя становятся начальными состояниями нейронов слоя MAXNET на второй фазе функционирования сети.
Во второй фазе инициировавшие MAXNET сигналы удаляются, и из сформированного ими начального состояния запускается итерационный процесс. Итерационный процесс завершается в момент, когда все нейроны, кроме нейрона-победителя с выходным сигналом не равным 0, перейдут в нулевое состояние.
Задача нейронов этого слоя состоит в определении победителя, то есть нейрона, у которого выходной сигнал отличен от 0. Процесс определения победителя выполняется согласно формуле:
 , (4.19)
, (4.19)
при начальном значении  . Функция активации
. Функция активации  нейронов слоя MAXNET задается выражением:
нейронов слоя MAXNET задается выражением:
 . (4.20)
. (4.20)
Итерационный процесс (4.19) завершается в момент, когда состояние нейронов стабилизируется, и активность продолжает проявлять только один нейрон, тогда как остальные пребывают в нулевом состоянии. Активный нейрон становится победителем и через веса  (s= 1,2,..,N)линейных нейронов выходного слоя представляет вектор
(s= 1,2,..,N)линейных нейронов выходного слоя представляет вектор  , который соответствует номеру вектора
, который соответствует номеру вектора  , признанному слоем MAXNET в качестве ближайшего к входному вектору
, признанному слоем MAXNET в качестве ближайшего к входному вектору  .
.
В третьей фазе этот нейрон посредством весов, связывающих его с нейронами выходного слоя, формирует на выходе сигнал, равный 1, его номер является номер входного образца, к которому принадлежит входной вектор.
Входные узлы сети принимают значения, задаваемые аналогичными компонентами вектора х. Нейроны первого слоя рассчитывают расстояние Хемминга между входным вектором х и каждым из  закодированных векторов-образцов
закодированных векторов-образцов  , образующих веса нейронов первого слоя. Нейроны в слое MAXNET выбирают вектор с наименьшим расстоянием Хемминга, определяя, таким образом, класс, к которому принадлежит предъявленный входной вектор х. Веса нейронов выходного слоя формируют вектор, соответствующий классу входного вектора. При
, образующих веса нейронов первого слоя. Нейроны в слое MAXNET выбирают вектор с наименьшим расстоянием Хемминга, определяя, таким образом, класс, к которому принадлежит предъявленный входной вектор х. Веса нейронов выходного слоя формируют вектор, соответствующий классу входного вектора. При  нейронах первого слоя, емкость запоминающего устройства Хемминга также равна
нейронах первого слоя, емкость запоминающего устройства Хемминга также равна  , так как каждый нейрон представляет единственный класс.
, так как каждый нейрон представляет единственный класс.
Важным достоинством сети Хемминга считается небольшое, по сравнению с сетью Хопфилда, число взвешенных связей между нейронами. Так, например, 100-входовая сеть Хопфилда, кодирующая 10 различных векторных классов, должна содержать 10000 взвешенных связей, тогда как аналогичная сеть Хемминга содержит 1100 связей, из которых 1000 весов находятся в первом слое, а 100 – в слое MAXNET [4].
|
из
5.00
|
Обсуждение в статье: Алгоритмы обучения без учителя |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы