 |
Главная |


Минимаксный принцип поиска решений
|
из
5.00
|
Алгоритмы поиска пути на И/ИЛИ- графах могут использовать стратегии поиска в глубину и ширину, однако, для большинства игр, дерево игры имеет большое количество позиций, что приводит к комбинаторному взрыву при реализации просмотра всех вершин дерева решений.
Основной подход к организации поиска на игровых деревьях использует оценочные функции, которые используются для вычисления оценки текущего состояния игры.
Для выбора следующего хода используется простой алгоритм:
· найти все возможные состояния игры, которые могут быть достигнуты за один ход;
· используя оценочную функцию, вычислить оценки состояний;
· выбрать ход, ведущий к позиции с наивысшей оценкой.
Если оценочная функция была бы совершенной, то есть ее значение отражало бы какие позиции ведут к победе, а какие – к поражению, то достаточно было бы просмотра вперед на один шаг. Обычно совершенная оценочная функция неизвестна, поэтому стратегия выбора хода на основе просмотра на один шаг вперед не дает хорошего результата, поэтому используется стратегия просмотра на несколько шагов вперед.
Стандартный метод определения оценки позиции, основанный на просмотре вперед нескольких слоев игрового дерева, называется минимаксным алгоритмом.
Минимаксный алгоритм предполагает, что противник из нескольких возможных ходов сделает выбор, лучший для себя , то есть худший для игрока. Поэтому целью игрока является выбор такого хода, который даст максимальную оценку своей позиции, возможной после лучшего хода противника, то есть минимизирующего оценку позиции противника. Отсюда название – минимаксный алгоритм. Число слоев игрового дерева, просматриваемых при поиске, зависит от доступных ресурсов. На последнем слое используется оценочная функция.
В предположении, что оценочная функция выбрана разумно, алгоритм будет давать тем лучшие результаты, чем больше слоев просматривается при поиске.
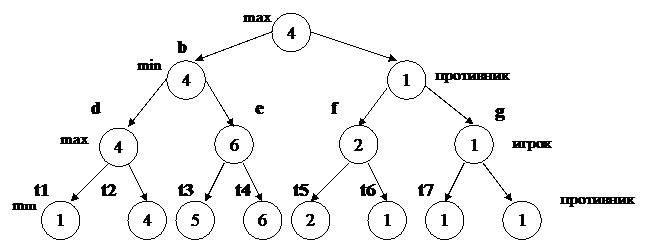
Пусть мы имеем следующее дерево игры:
|
|
|
|
Задана некая оценочная функция j(Pk), где Pk- некоторая игровая ситуация.
Предположим, что игрок максимизирует свой выигрыш, а противник минимизирует свой проигрыш. Вариант решения, образованный минимаксной стратегией движения по дереву игры, будем называть основным вариантом решения.
Если существует оценочная функция, то можно ввести внутреннюю функцию j(Pk) такую, что:
j(pk)= 
Пример 60:
domains
poz = symbol
spoz = poz*
facts
xod (poz, spoz)% описывает возможные ходы (дуги)
xod_min (poz) )% описывает вершины противника
xod_max (poz) )% описывает вершины игрока
predicates
minmax (poz, poz, integer) % запускающий предикат
best (spoz, poz, integer) % основной предикат, определяющий лучший ход
oc_term(poz, integer) % описывает стоимость вершин
case_(poz, integer, poz, integer, poz, integer) % определяет выбор вершины для перехода
clauses
xod (a, [b,c]).
xod (b, [d,e]).
xod (c, [f,g]).
xod (d, [t1,t2]).
xod (e, [t3,t4]).
xod (f, [t5,t6]).
xod (g, [t7,t8]).
xod_max (a).
xod_max (d).
xod_max (e).
xod_max (f).
xod_max (g).
xod_min (b).
xod_min (c).
xod_min (t1).
xod_min (t2).
xod_min (t3).
xod_min (t4).
xod_min (t5).
xod_min (t6).
xod_min (t7).
xod_min (t8).
oc_term (a,4).
oc_term (b,4).
oc_term (c,1).
oc_term (d,4).
oc_term (e,6).
oc_term (f,2).
oc_term (g,1).
oc_term (t1,1).
oc_term (t2,4).
oc_term (t3,5).
oc_term (t4,6).
oc_term (t5,2).
oc_term (t6,1).
oc_term (t7,1).
oc_term (t8,1).
minmax (Poz, BestPoz, Oc):-
xod (Poz, SpPoz),!,
best(SpPoz, BestPoz, Oc);
oc_term(Poz, Oc).
best ([Poz], Poz, Oc):- minmax (Poz, _ , Oc), !.
best ([Poz1| T], BestPoz, BestOc):-
minmax (Poz1, _ , Oc1),
best (T, Poz2, Oc2),
case_(Poz1,Oc1,Poz2,Oc2,BestPoz,BestOc).
case_(Poz1, Oc1, Poz2, Oc2, Poz1, Oc1):-
xod_min (Poz1), Oc1>Oc2,!;
xod_max (Poz1), Oc1<Oc2,!.
case_(Poz1, Oc1, Poz2, Oc2, Poz2, Oc2).
goal
minmax(a,BestPoz,Oc).
Литература:
1. Адаменко А.Н., Кучуков А. Логическое программирование и Visual Prolog – Спб.: БХВ – Петербург, 2003.
2. Андрейчиков А.В., Андрейчикова О.Н.. Интеллектуальные информационные системы: Учебник. – М.: Финансы и статистика, 2006. – 424 с., ил.
3. Братко И. Алгоритмы искусственного интеллекта на языке Prolog. М.: Вильямс, 2004. – 637 с.
4. Марселлус Д. Программирование экспертных систем на Турбо Прологе: Пер. с англ. – М.: Финансы и статистика, 1994. – 256 с., ил.
5. Осовский С. Нейронные сети для обработки информации / Пер. с пол. И.Д. Рудинского. – М.: Финансы и статистика, 2002. – 344 с.: ил.
6. Солдатова О.П. Основы нейроинфоматики: учеб. пособие - Самара: Изд-во Самар. гос. аэрокосм. ун-та, 2006- 132 с. ил.
7. Стерлинг Л., Шапиро Э. Искусство программирования на языке Пролог: Пер. с англ. М.: Мир.1990.
8. Хайкин С. Нейронные сети: Полный курс: Пер. с англ. - 2-е изд. – М.: Вильямс, 2006. – 1104 с.: ил.
|
из
5.00
|
Обсуждение в статье: Минимаксный принцип поиска решений |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы