 |
Главная |


Динамические модели надежности
|
из
5.00
|
Модель Шумана. Исходные данные для модели Шумана, которая относится к динамическим моделям дискретного времени, собираются в процессе тестирования ПС в течение фиксированных или случайных временных интервалов. Каждый интервал - это стадия, на которой выполняется последовательность тестов и фиксируется некоторое число ошибок.
Модель Шумана может быть использована при определенным образом организованной процедуре тестирования. Использование модели Шумана предполагает, что тестирование проводится в несколько этапов. Каждый этап представляет собой выполнение программы на полном комплексе разработанных тестовых данных. Выявленные ошибки регистрируются (собирается статистика об ошибках), но не исправляются. По завершении этапа на основе собранных данных о поведении ПС на очередном этапе тестирования может быть использована модель Шумана для расчета количественных показателей надежности. После этого исправляются ошибки, обнаруженные на предыдущем этапе, при необходимости корректируются тестовые наборы и проводится новый этап тестирования. При использовании модели Шумана предполагается, что исходное количество ошибок в программе постоянно и в процессе тестирования может уменьшаться по мере того, как ошибки выявляются и исправляются. Новые ошибки при корректировке не вносятся. Скорость обнаружения ошибок пропорциональна числу оставшихся ошибок. Общее число машинных инструкций в рамках одного этапа тестирования постоянно.
Предполагается, что до начала тестирования в ПС имеется Ет ошибок. В течение времени тестирования t обнаруживается ec ошибок в расчете на команду в машинном языке.
Таким образом, удельное число ошибок на одну машинную команду, оставшихся в системе после т времени тестирования, равно:
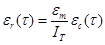 , (1)
, (1)
где IT — общее число машинных команд, которое предполагается постоянным в рамках этапа тестирования.
Автор предполагает, что значение функции частоты отказов Z(t) пропорционально числу ошибок, оставшихся в ПС после израсходованного на тестирование времени t:
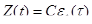 , (2)
, (2)
где С — некоторая константа;
t — время работы ПС без отказа.
Тогда, если время работы ПС без отказа 1 отсчитывается от точки t = 0, а t остается фиксированным, функция надежности, или вероятность безотказной работы на интервале времени от 0 до t, равна:
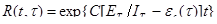 ; (3)
; (3)
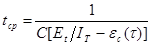 . (4)
. (4)
Из величин, входящих в формулы (3) и (4), не известны начальное значение ошибок в ПС (ЕT) и коэффициент пропорциональности - С. Для их определения прибегают к следующим рассуждениям. В процессе тестирования собирается информация о времени и количестве ошибок на каждом прогоне, т.е. общее время тестирования  t складывается из времени каждого прогона:
t складывается из времени каждого прогона:
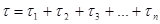 . (5)
. (5)
Предполагая, что интенсивность появления ошибок постоянна и равна l, можно вычислить ее как число ошибок в единицу времени:
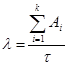 , (6)
, (6)
где Аi — количество ошибок на i-м прогоне.
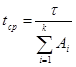 . (7)
. (7)
Имея данные для двух различных моментов тестирования ta и tb, которые выбираются произвольно с учетом требования, чтобы ec(tb)<e c(tA) можно сопоставить уравнения (4) и (7) при:
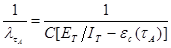 , (8)
, (8)
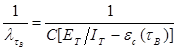 . (9)
. (9)
Вычисляя отношения (8) и (9), получим:
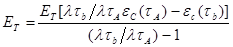 . (10)
. (10)
Подставив полученную оценку параметров ET, в выражение (8), получим оценку для второго неизвестного параметра:
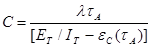 . (11)
. (11)
Получив неизвестные Еt и С, можно рассчитать надежность программы по формуле (3).
Позднее автором предложена модифицированная модель, не учитывающая число машинных команд, т.е. независимая от IT
Функция частоты отказов в течение 1-го интервала тестирования остается постоянной и равна:
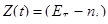 , t³0, i=1,2,…m. (12)
, t³0, i=1,2,…m. (12)
Известные параметры модели ЕT и С автор предлагает вычислять из следующих соотношений:
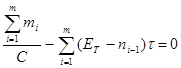 , (13)
, (13)
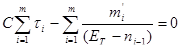 , (14)
, (14)
где ti( — время i-го прогона (время i-го интервала);
mi’ — число прогонов, завершившихся отказом в i-ом интервале (число ошибок в i-м интервале);
m — общее число тестовых интервалов;
ni — общее число ошибок, обнаруженных (но не включенных) к i-му интервалу.
Все эти данные можно получить в ходе тестирования. Вычислив значения параметров Еt и С, можно определить показатели:
- число оставшихся ошибок в ПС;
NT=ЕT-n; (15)
- надежность:
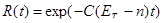 , t>0. (16)
, t>0. (16)
Достоинство этой модели по сравнению с предыдущей заключается в том, что можно исправлять ошибки, внося изменения в текст программы в ходе тестирования, не разбивая процесс на этапы, чтобы удовлетворить требованию постоянства числа машинных инструкций.
Модель Lа Раdula. По этой модели выполнение последовательности тестов производится в т этапов. Каждый этап заканчивается внесением изменений (исправлений) в ПС. Возрастающая функция надежности базируется на числе ошибок, обнаруженных в ходе каждого тестового прогона.
Надежность ПС в течение i-го этапа:
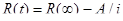 , i = 1,2,3,…, (17)
, i = 1,2,3,…, (17)
где А—параметр роста;
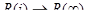 при i ® ¥.Т.е R(¥) - предельная надежность ПС.
при i ® ¥.Т.е R(¥) - предельная надежность ПС.
Эти неизвестные величины автор предлагает вычислить, решив следующие уравнения:
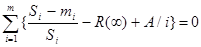 , (18)
, (18)
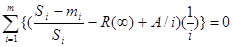 , (19)
, (19)
где Si. — число тестов;
mi, — число отказов во время i-го этапа:
т — число этапов;
i=1,2, ...,т.
Определяемый по этой модели показатель есть надежность ПС на i-м этапе:
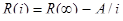 , i = m+1, m+2 … (20)
, i = m+1, m+2 … (20)
Преимущество модели заключается в том, что она является прогнозной и, основываясь на данных, полученных в ходе тестирования, дает возможность предсказать вероятность безотказной работы программы на последующих этапах ее выполнения.
Модель Джелинского-Моранды. относится к динамическим моделям непрерывного времени. Исходные данные для использования этой модели собираются в процессе тестирования ПС. При этом фиксируется время до очередного отказа. Основное положение, на котором базируется модель, заключается в том, что значение интервалов времени тестирования между обнаружением двух ошибок имеет экспоненциальное распределение с частотой ошибок (или интенсивностью отказов), пропорциональной числу еще не выявленных ошибок. Каждая обнаруженная ошибка устраняется, число оставшихся ошибок уменьшается на единицу.
Функция плотности распределения времени обнаружения 1-й ошибки, отсчитываемого от момента выявления 1-1-и ошибки, имеет вид:
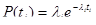 , (21)
, (21)
где li — частота отказов (интенсивность отказов), которая пропорциональна числу еще не выявленных ошибок в программе:
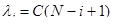 (22)
(22)
где N — число ошибок, первоначально присутствующих в программе; С — коэффициент пропорциональности.
Наиболее вероятные значения величин 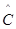 и
и 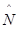 (оценка максимального правдоподобия) можно определить на основе данных, полученных при тестировании. Для этого фиксируют время выполнения программы до очередного отказа (t1, t2, t3, … tk,).
(оценка максимального правдоподобия) можно определить на основе данных, полученных при тестировании. Для этого фиксируют время выполнения программы до очередного отказа (t1, t2, t3, … tk,).
Значения 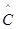 и
и 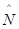 предлагается получить, решив систему уравнений:
предлагается получить, решив систему уравнений:
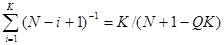 , (23)
, (23)
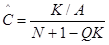 , (24)
, (24)
где
Q=В/АК; 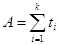 ;
; 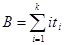 . (25)
. (25)
Поскольку полученные значения и - вероятностные и точность их зависит от количества интервалов тестирования (или количества ошибок), найденных к моменту оценки надежности, асимптотические оценки дисперсий авторы предлагают определить с помощью следующих формул:
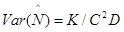 , (26)
, (26)
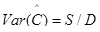 , (27)
, (27)
где
D = KS/C2 и 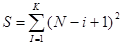 . (28)
. (28)
Чтобы получить числовые значения li нужно подставить вместо N и С их возможные значения и . Рассчитав К значений по формуле (22) и подставив их в формулу (21), можно определить вероятность безотказной работы на различных временных интервалах. На основе полученных расчетных данных строится график зависимости вероятности безотказной работы от времени.
Модель Шика-Волвертона. Модификация модели Джелинского-Моранды для случая возникновения на рассматриваемом интервале более одной ошибки предложена Волвертоном и Шиком. При этом считается, что исправление ошибок производится лишь после истечения интервала времени, на котором они возникли. В основе модели Шика-Волвертона лежит предположение, согласно которому частота ошибок пропорциональна не только количеству ошибок в программах, но и времени тестирования, т.е. вероятность обнаружения ошибок с течением времени возрастает. Частота ошибок (интенсивность обнаружения ошибок) li, предполагается постоянной в течение интервала времени ti, и пропорциональна числу ошибок, оставшихся в программе по истечении (i - 1)-го интервала; но она пропорциональна также и суммарному времени, уже затраченному на тестирование (включая среднее время выполнения программы в текущем интервале):
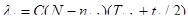 . (29)
. (29)
В данной модели наблюдаемым событием является число ошибок, обнаруживаемых в заданном временном интервале, а не время ожидания каждой ошибки, как это было для модели Желинского-Моранды. В связи с этим модель относят к группе дискретных динамических моделей, а уравнения для определения С и N имеют несколько иной вид:
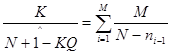 , (30)
, (30)
где
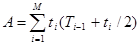 , (31)
, (31)
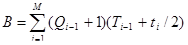 . (32)
. (32)
ti — продолжительность временного интервала, в котором наблюдается Мi ошибок;
Тi-1 — время, накопленное за (i—1) интервалов:
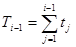 , T0=0 . (33)
, T0=0 . (33)
ni-1 — суммарное число ошибок, обнаруженных за период от первого до (i -1)-го интервала времени включительно:
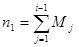 , n0=0 . (34)
, n0=0 . (34)
М — общее число временных интервалов;
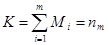 — суммарное число обнаруженных ошибок. (35)
— суммарное число обнаруженных ошибок. (35)
При М = 1 уравнения (30) приобретают вид уравнений (21).
Таким образом, модель Джелинского-Моранды является частным случаем модели Шика-Волвертона для случая, когда при тестировании фиксируется время до появления очередной ошибки.
Модель Муса. Модель Муса относят к динамическим моделям непрерывного времени. Это значит, что в процессе тестирования фиксируется время выполнения программы (тестового прогона) до очередного отказа. Но считается, что не всякая ошибка ПС может вызвать отказ, поэтому допускается обнаружение более одной ошибки при выполнении программы до возникновения очередного отказа.
Считается, что на протяжении всего жизненного цикла ПС может произойти М0 отказов и при этом будут выявлены все N0 ошибки, которые присутствовали в ПС до начала тестирования.
Общее число отказов Мо связано с первоначальным числом ошибок N0 соотношением
N0 = ВМ0, (36)
где В — коэффициент уменьшения числя ошибок.
В момент, когда производится оценка надежности, после проведения тестирования, на которое потрачено определенное время t, зафиксировано m отказов и выявлено п ошибок.
Тогда из соотношения:
п=Вт (15) , (37)
можно определить коэффициент уменьшения числа ошибок В как число, характеризующее количество устраненных ошибок, приходящихся на один отказ.
В модели Муса различают два вида времени:
1) суммарное время функционирования t, которое учитывает чистое время тестирования до контрольного момента, когда производится оценка надежности;
2) оперативное время t- время выполнения программы, планируемое от контрольного момента и далее, при условии, что дальнейшего устранения ошибок не будет (время безотказной работы в процессе эксплуатации).
Для суммарного времени функционирования t предполагается:
- интенсивность отказов пропорциональна числу не устраненных ошибок;
- скорость изменения числа устраненных ошибок, измеряемая относительно суммарного времени функционирования,. пропорциональна интенсивности отказов.
Один из основных показателей надежности, который рассчитывается по модели Муса, - средняя наработка на отказ. Этот показатель определяется как математическое ожидание временного интервала между последовательными отказами и связан с надежностью:
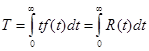 , (38)
, (38)
где t — время работы до отказа.
Если интенсивность отказов постоянна (т.е. когда длительность интервалов между последовательными отказами имеет экспоненциальное распределение), то средняя наработка на отказ обратно пропорциональна интенсивности отказов. По модели Муса средняя наработка на отказ зависит от суммарного времени функционирования t:
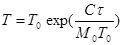 , (39)
, (39)
где T0 — средняя наработка на отказ в начале испытаний (тестирования);
С - коэффициент сжатия тестов, который вводится для устранения избыточности при тестировании. Если, например, один час тестирования соответствует 12 ч работы в реальных условиях, то коэффициент сжатия тестов равен 12.
Параметр То - средняя наработка на отказ до начала тестирования, можно предсказать из следующего соотношения:
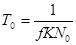 , (40)
, (40)
где f — средняя скорость исполнения программы, отнесенная к числу команд (операторов);
К — коэффициент проявления ошибок, связывающий частоту возникновения ошибок со "скоростью ошибок", которая представляет собой скорость, с которой бы встречались ошибки программы, если бы программа выполнялась линейно (последовательно по командам). В настоящее время значение К приходится определять эмпирическим путем по однотипным программам. Его значение изменяется от 1.54*10-7 до 3.99*10-7;
N0 — начальное число ошибок — можно рассчитать с помощью другой модели, позволяющей определить эту величину на основе статистических данных, полученных при тестировании (например, модель Шумана). Надежность R для оперативного периода t выражается равенством:
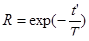 . (41)
. (41)
Если в договоре с заказчиком оговорена требуемая величина наработки на отказ ТF, то можно определить число отказов Dm и дополнительное время функционирования (тестирования) D t, обеспечивающее заданное ТF. Их можно рассчитать по формулам:
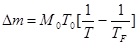 , (42)
, (42)
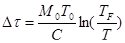 . (43)
. (43)
По результатам тестовых испытаний можно определить значение коэффициента В из соотношения (37) и М0 - из соотношения (34). По договорной величине требуемой средней наработки на отказ ТF и рассчитанной по модели Муса текущей средней наработки на отказ Т можно сделать заключение о необходимости продолжать или, возможно, закончить тестирование программ. В случае необходимости продолжения работ по тестированию для достижения требуемой средней наработки на отказ модель дает возможность предсказать число возможных отказов Dm (формула (42)) и дополнительное время тестирования D t (формула (43)).
Модель переходных вероятностей. Эта модель основана на марковском процессе, протекающем в дискретной системе с непрерывным временем.
Процесс, протекающий в системе, называется марковским (или процессом без последствий), если для каждого момента времени вероятность любого состояния системы в будущем зависит только от состояния системы в настоящее время t0 и не зависит от того, каким образом система пришла в это состояние. Процесс тестирования ПС рассматривается как марковский процесс.
В начальный момент тестирования (t=0) в ПС было n ошибок. Предполагается, что в процессе тестирования выявляется по одной ошибке. Тогда последовательность состояний системы (n, n-1, n-2, n-3} и т.д. соответствует периодам времени, когда предыдущая ошибка уже исправлена, а новая еще не обнаружена. Например, в состоянии n-5 пятая ошибка уже исправлена, а шестая еще не обнаружена.
Последовательность состояний {т, т-1, т-2, т-3 и т.д.} соответствует периодам времени, когда ошибки исправляются. Например, в состоянии т-1 вторая ошибка уже обнаружена, но еще не исправлена. Ошибки обнаруживаются с интенсивностью l, а исправляются с интенсивностью m.
Предположим, в какой-то момент времени процесс тестирования остановился. Совокупность возможных состояний системы будет: 5={ n, т, n-1, n-1, n-2, m-2, . . . }.
Система может переходить из одного состояния в другое с определенной вероятностью Pij. Время перехода системы из одного состояния в другое бесконечно мало.
Вероятность перехода из состояния n-k в состояние m-k есть ln-kDt ( для k = 0, 1, 2, ... . Соответственно вероятность перехода из состояния m-k в состояние n-k-1 будет mm-kDt для k=0,1,2,....
Общая схема модели представлена на рисунке 34. Если считать, что l1 и m1 зависят от текущего состояния системы, то можно составить матрицу переходных вероятностей представленной в таблице 12.
Общая схема модели
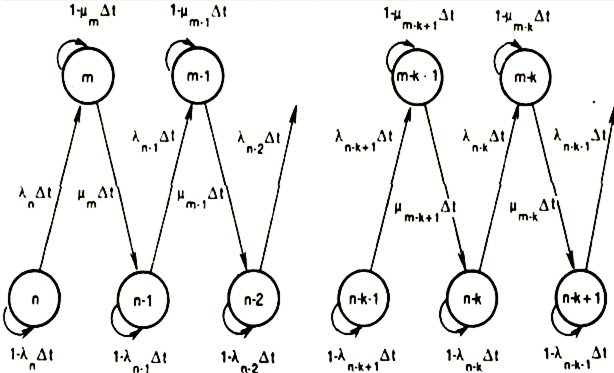
Рис. 34
Таблица 12 - Модель многих состояний ПС
| 1-lnDt | lnDt | 0 | 0 | 0 … | 0 … | |
| 0 | 1-mmDt | mmDt | 0 | 0 … | 0 … | |
| 0 | 0 | 1-ln-1Dt | ln-1Dt | |||
| 0 | 0 | 0 | 1-mm-1Dt | |||
| ……………… | ……………… | ……………… | ……………… | ……………. | 1-ln-kDt | ln-kDt |
| 0 | 1-mm-kDt |
Пусть S'(t) - случайная переменная, которой обозначено состояние системы в момент времени t.
В любой момент времени система может находиться в двух возможных состояниях: работоспособном либо неработоспособном (момент исправления очередной ошибки).
Вероятности нахождения системы в том или ином состоянии определяются как:
Pn-k(t) = P(S’(t)=n-k), k=1,2,3,… (44)
Pm-k(t) = P(S’(t)=m-k), k=1,2,3,… (45)
Готовность системы определяется как сумма вероятностей нахождения ее в работоспособном состоянии:
 . (46)
. (46)
Под готовностью системы к моменту времени t понимается вероятность того, что система находится в рабочем состоянии во время t.
Надежность системы после t (времени отладки, за которое уже выявлено К ошибок, т.е. система находится в состоянии n-k (К-я ошибка исправлена, а (К+1)-я еще не обнаружена), может быть определена из состояния:
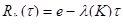 , (47)
, (47)
где 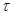 — интервал времени, когда может появиться (К+ 1)-я ошибка;
— интервал времени, когда может появиться (К+ 1)-я ошибка;
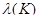 — принятая постоянная интенсивность проявления ошибок.
— принятая постоянная интенсивность проявления ошибок.
Рассмотрим решение модели для случая, когда интенсивность появления ошибок l и интенсивность их исправления m- постоянные величины. Составляется система дифференциальных уравнений:
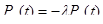 ;
;
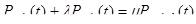 , k=1,2,3,… (48)
, k=1,2,3,… (48)
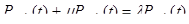 , k=0,1,2,3,…
, k=0,1,2,3,…
Начальными условиями для решения системы могут являться:
Pn(0) = 1;
Pn-k(0) = 0; k=1,2,3,… (49)
Pm-k(0) = 0; k=1,2,3,…
При имеющихся начальных условиях система уравнений может быть решена классически или с использованием преобразований Лапласа.
В результате решения определяются Pn-k и Pm-k для случая, когда l и m - константы.
Для общего случая отбросим ограничение постоянства интенсивностей появления и исправления ошибок и предположим, что
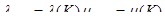 , k=1,2,3,…, (50)
, k=1,2,3,…, (50)
т.е. являются функциями числа ошибок, найденных к этому времени в ПС. Система дифференциальных уравнений для такого случая имеет вид:
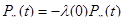
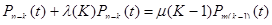 , K=1,2,3, … (51)
, K=1,2,3, … (51)
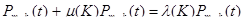 , K=1,2,3, …
, K=1,2,3, …
Начальные условия для решения системы будут:
Pn(0)=1;
Pn-k(0)=0; k=1,2,3,… (52)
Pm-k(0)=0; k=1,2,3,…
Система может быть решена методом итераций Эйлера. Предполагается, что в начальный период использования модели значения Х и р должны быть получены на основе предыдущего опыта разработчика. В свою очередь, модель позволяет накапливать данные об ошибках, что дает возможность повышения точности анализа на основе предыдущего моделирования. Практическое использование модели требует громоздких вычислений и делает необходимым наличие ее программной поддержки.
|
из
5.00
|
Обсуждение в статье: Динамические модели надежности |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы