 |
Главная |


Линия моделирования и базы данных
|
из
5.00
|
Изучаемые вопросы:
• Признаки компьютерной информационной модели.
• Является ли база данных информационной моделью.
• Задачи, решаемые на готовой базе данных.
• Проектирование базы данных (БД) — задача для углубленного курса.
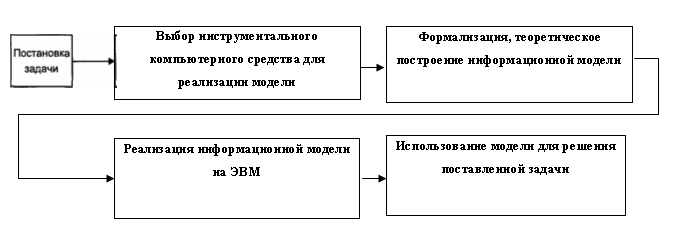 Общая схема этапов решения практической задачи на ЭВМ методами информационного моделирования выглядит следующим образом (рис. 1):
Общая схема этапов решения практической задачи на ЭВМ методами информационного моделирования выглядит следующим образом (рис. 1):
Два первых этапа относятся к предметной области решаемой задачи. На третьем этапе происходит выбор подходящего инструментального средства в составе программного обеспечения ЭВМ для реализации модели. Такими средствами могут быть: электронные таблицы, СУБД, системы программирования, математические пакеты, специализированные системы моделирования общего назначения или ориентированные на данную предметную область. В базовом курсе информатики изучаются первые три из перечисленных программных средств.
Основные признаки компьютерной информационной модели:
• наличие реального объекта моделирования;
• отражение ограниченного множества свойств объекта по принципу целесообразности;
• реализация модели с помощью определенных компьютерных средств;
• возможность манипулирования моделью, активного ее использования.
Ответ на вопрос: «является ли база данных информационной моделью?» будем искать, исходя их сформулированных выше критериев.
 Первый критерий: наличие предметной области, некоторого реального объекта (системы), к которым относится БД, практически всегда выполняется. Например, если в БД содержатся сведения о книгах в библиотеке, значит, объектом моделирования является книжный фонд библиотеки. Если БД содержит анкетные данные сотрудников предприятия, значит, она моделирует кадровый состав этого предприятия. Если в БД хранятся сведения о результатах сдачи экзаменов абитуриентами в институт, следовательно, она моделирует процесс вступительных экзаменов и т. п.
Первый критерий: наличие предметной области, некоторого реального объекта (системы), к которым относится БД, практически всегда выполняется. Например, если в БД содержатся сведения о книгах в библиотеке, значит, объектом моделирования является книжный фонд библиотеки. Если БД содержит анкетные данные сотрудников предприятия, значит, она моделирует кадровый состав этого предприятия. Если в БД хранятся сведения о результатах сдачи экзаменов абитуриентами в институт, следовательно, она моделирует процесс вступительных экзаменов и т. п.
Удовлетворение второму критерию также несложно обосновать. Каждый из моделируемых объектов (как перечисленные выше, так и любые другие) обладает гораздо большим числом свойств, характеристик, атрибутов, чем те, что отражены в БД. Отбор атрибутов, включаемых в БД, происходит в процессе проектирования базы, когда главным критерием является критерий целесообразности, т. е. соответствия цели создания БД, требованиям к ее последующим эксплуатационным свойствам. Например, в БД книжного фонда библиотеки не имеет смысла вносить такие характеристики книги, как ее вес, адрес типографии, где была напечатана книга, годы жизни автора и пр.
Третий критерий, очевидно, выполняется, поскольку речь идет о компьютерной базе данных, созданной в среде некоторой СУБД.
База данных — не «мертвое хранилище» информации. Она создается для постоянного, активного использования хранящейся в ней информации. Прикладные программы или СУБД, обслуживающие базу данных, позволяют ее пополнять, изменять, осуществлять поиск информации, сортировку, группировку данных, получение отчетных документов и пр. Таким образом, четвертый критерий компьютерной информационной модели также справедлив для БД.
В рамках обсуждаемой темы перед учителем информатики стоят две педагогические задачи: научить использовать готовые информационные модели; научить разрабатывать информационные модели. В минимальном варианте изучения базового курса предпочтение отдается первой задаче. В таком варианте ученикам могут быть предложены задачи следующего типа: имеется готовая база данных; требуется осуществить поиск нужной информации;
выполнить сортировку данных по некоторому ключу; сформировать отчет с нужной информацией. Решение этой задачи не требует вмешательства в готовую модель.
Другой тип задач: расширить информационное содержание базы данных. Например, имеется реляционная база данных, содержащая сведения о книгах в библиотеке:
БИБЛИОТЕКА (НОМЕР, ШИФР, АВТОР, НАЗВАНИЕ)
Требуется изменить структуру БД таким образом, чтобы из нее можно было узнать, находится ли книга в настоящее время в библиотеке, и если книга выдана, то когда и кому.
Новые цели требуют внесения изменений в модель, в структуру базы данных. Ученики должны спланировать добавление новых полей, определить их типы. Решение может быть таким: после добавления полей база данных будет иметь следующую структуру:
БИБЛИОТЕКА (НОМЕР, ШИФР, АВТОР, НАЗВАНИЕ, НАЛИЧИЕ, ЧИТАТЕЛЬ, ДАТА)
Здесь добавлены поля:
— НАЛИЧИЕ — поле логического типа; принимает значение True, если книга находится в библиотеке, и значение False, если выдана читателю;
— ЧИТАТЕЛЬ — поле числового (или символьного) типа; содержит номер читательского билета человека, взявшего книгу;
— ДАТА — поле типа «дата»; указывает день выдачи книги.
Несмотря на все сказанное выше, не следует преувеличивать в интерпретации каждого задания на работу с базой данных, как задачи моделирования. И на минимальном уровне изучения темы можно предлагать ученикам простые задачи на разработку баз данных, решение которых очевидно. К числу таких задач, например, относится задача разработки баз данных типа записной книжки с адресами знакомых, телефонного справочника и пр.
Проектирование баз данных . Проектирование базы данных заключается в теоретическом построении информационной модели определенной структуры. Известны три основные структуры, используемые при организации данных в БД: иерархическая (деревья), сетевая и табличная (реляционная). В последнее время чаще всего создаются БД реляционного типа. Доказано, что табличная структура является универсальной и может быть применена в любом случае. В базовом курсе информатики изучаются базы данных реляционной структуры.
Если объект моделирования представляет собой достаточно сложную систему, то проектирование БД становится нетривиальной задачей. Для небольших учебных БД ошибки при проектировании не столь существенны. Но если создается большая база, в которой будут сохраняться многие тысячи записей, то ошибки при проектировании могут стоить очень дорого. Основные последствия неправильного проектирования — избыточность информации, ее противоречивость, потеря целостности, т.е. взаимосвязи между данными. В результате БД может оказаться неработоспособной и потребовать дорогостоящей переделки.
Теория реляционных баз данных была разработана в 1970-х гг. Е.Коддом. Он предложил технологию проектирования баз данных, в результате применения которой в полученной БД не возникает отмеченных выше недостатков. Сущность этой технологии сводится к приведению таблиц, составляющих БД, к третьей нормальной форме. Этот процесс называется нормализацией данных: сначала все данные, которые планируется включить в БД, представляются в первой нормальной форме, затем преобразуются ко второй и на последнем шаге — к третьей нормальной форме. Проиллюстрируем процесс нормализации данных на примере.
Ставится задача: создать БД, содержащую сведения о посещении пациентами поликлиники своего участкового врача. Сначала строится одна таблица, в которую заносятся фамилия пациента, его дата рождения, номер участка, к которому приписан пациент, фамилия участкового врача, дата посещения врача и установленный диагноз болезни. Ниже приведен пример такой таблицы.
Таблица 2
БД «Поликлиника»
| Фамилия пациента | Дата рождения | Номер участка | Фамилия врача | Дата посещения | Диагноз |
| Лосев О.И. | 20.04.65 | 2 | Петрова О.И. | 11.04.98 | грипп |
| Орлова Е.Ю. | 25.01.47 | 1 | Андреева И. В. | 05.05.98 | ОРЗ |
| Лосев О.И. | 20.04.65 | 2 | Петрова О.И. | 26.07.98 | бронхит |
| Дуров М.Т. | 05.03.30 | 2 | Петрова О.И. | 14.03.98 | стенокардия |
| Жукова Л. Г. | 30.01.70 | 2 | Петрова О.И. | 11.04.98 | ангина |
| Орлова Е.Ю. | 25.01.47 | 1 | Андреева И. В. | 11.07.98 | гастрит |
| Быкова А.А. | 01.04.75 | 1 | Андреева И. В. | 15.06.98 | ОРЗ |
| Дуров М.Т. | 05.03.30 | 2 | Петрова О.И. | 26.07.98 | ОРЗ |
Нетрудно понять недостатки такой организации данных. Во-первых, очевидна избыточность информации: повторение даты рождения одного и того же человека, повторение фамилии врача одного и того же участка. В такой БД велика вероятность иметь недостоверные, противоречивые данные. Например, если на втором участке сменится врач, то придется просматривать всю базу и вносить изменения во все записи, относящиеся к этому участку. При этом велика вероятность что-то пропустить. После каждого нового посещения пациентом больницы потребуется снова вводить его дату рождения, номер участка, фамилию врача, т.е. информацию, уже существующую в БД.
Полученная таблица соответствует первой нормальной форме. Для устранения отмеченных недостатков требуется ее дальнейшая нормализация. Структура такой таблицы (отношения) описывается следующим образом:
ПОЛИКЛИНИКА (ФАМИЛИЯ, ДАТА_РОЖДЕНИЯ, УЧАСТОК, ВРАЧ, ДАТА ПОСЕЩЕНИЯ, ДИАГНОЗ)
Необходимо установить ключ записей. Здесь ключ составной, который включает в себя два поля: ФАМИЛИЯ и ДАТА_ПОСЕЩЕНИЯ. Каждая запись — это информация о конкретном посещении пациентом больницы. Если допустить, что в течение одного дня данный пациент может сделать только один визит к участковому врачу, то в разных записях не будет повторяться комбинация двух полей: фамилии пациента и даты посещения врача.
Согласно определению второй нормальной формы, все неключевые поля должны функционально зависеть от полного ключа. В данной таблице лишь ДИАГНОЗ определяется одновременно фамилией пациента и датой посещения. Остальные поля связаны лишь с фамилией, т. е. от даты посещения они не зависят. Для преобразования ко второй нормальной форме таблицу нужно разбить на две следующие:
ПОСЕЩЕНИЯ (ФАМИЛИЯ, ДАТА ПОСЕЩЕНИЯ, ДИАГНОЗ)
ПАЦИЕНТЫ (ФАМИЛИЯ, ДАТА_РОЖДЕНИЯ, УЧАСТОК, ВРАЧ)
В отношении ПОСЕЩЕНИЯ по-прежнему действует составной ключ из двух полей, а в отношении ПАЦИЕНТЫ — одно ключевое поле ФАМИЛИЯ.
Во втором отношении имеется так называемая транзитивная зависимость. Она отображается следующим образом:
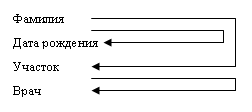 |
Значение поля ВРАЧ связано с фамилией пациента транзитивно через поле УЧАСТОК. В самом деле, всякий участковый врач приписан к своему участку и обслуживает больных, относящихся к данному участку.
Согласно определению третьей нормальной формы в отношении не должно быть транзитивных зависимостей. Значит, требуется еще одно разбиение отношения ПАЦИЕНТЫ на два отношения.
В итоге получаем базу данных, состоящую из трех отношений:
ПОСЕЩЕНИЯ (ФАМИЛИЯ, ДАТА ПОСЕЩЕНИЯ, ДИАГНОЗ)
ПАЦИЕНТЫ (ФАМИЛИЯ, ДАТА_РОЖДЕНИЯ, УЧАСТОК)
ВРАЧИ (УЧАСТОК, ВРАЧ)
В третьем отношении ключом является номер участка, поскольку он повторяться не может. В то же время возможна ситуация, когда один врач обслуживает больше одного участка. Полученная структура БД удовлетворяет требованиям третьей нормальной формы: в таблицах все неключевые поля полностью функционально зависят от своих ключей и отсутствуют транзитивные зависимости.
Еще одним важным свойством полученной БД является то, что между тремя отношениями существует взаимосвязь через общие поля. Отношения ПОСЕЩЕНИЯ и ПАЦИЕНТЫ связаны общим полем ФАМИЛИЯ. Отношения ПАЦИЕНТЫ и ВРАЧИ связаны через поле УЧАСТОК. Для связанных таблиц существует еще одно понятие: тип связи. Возможны три варианта типа связей: «один — к—одному», «один—ко—многим», «многие — ко — многим». В нашем примере между связанными таблицами существуют связи типа «один — ко — многим», и схематически они отображаются так:
 |
Смысл следующий: у каждого врача (на каждом участке) много пациентов; каждый пациент посещает врача множество раз.
В приведенном примере показана процедура нормализации в строгом соответствии с теорией реляционных баз данных. Понимание смысла этой процедуры очень полезно для учителя.
На примере приведенной выше таблицы ПОЛИКЛИНИКА нужно увидеть три различных типа объектов, к которым относится данная информация: это пациенты поликлиники, врачи и посещения пациентами врачей. Соответственно строятся три таблицы, содержащие атрибуты, относящиеся к этим трем типам объектов и связанные между собой через общие поля.
Информационное моделирование и электронные таблицы
Изучаемые вопросы:
• Что такое математическая модель.
• Понятия: компьютерная математическая модель, численный эксперимент.
• Пример реализации математической модели на электронной таблице.
Электронные таблицы являются удобной инструментальной средой для решения задач математического моделирования.
Что же такое математическая модель? Это описание состояния или поведения некоторой реальной системы (объекта, процесса) на языке математики, т.е. с помощью формул, уравнений и других математических соотношений. Характерная конфигурация всякой математической модели представлена на рис. 2.

Рис.2. Обобщенная структура математической модели
Здесь Х и У — некоторые количественные характеристики моделируемой системы.
Реализация математической модели — это применение определенного метода расчетов значений выходных параметров по значениям входных параметров. Технология электронных таблиц — один из возможных методов реализации математической модели. Другими методами реализации математической модели может быть составление программ на языках программирования, применение математических пакетов (MathCAD, Математика и др.), применение специализированных программных систем для моделирования. Реализованные такими средствами математические модели будем называть компьютерными математическими моделями.
Цель создания компьютерной математической модели — проведение численного эксперимента, позволяющего исследовать моделируемую систему, спрогнозировать ее поведение, подобрать оптимальные параметры и пр.
Итак, характерные признаки компьютерной математической модели следующие:
• наличие реального объекта моделирования;
• наличие количественных характеристик объекта: входных и выходных параметров;
• наличие математической связи между входными и выходными параметрами;
• реализация модели с помощью определенных компьютерных средств.
В качестве примера использования электронных таблиц для математического моделирования рассмотрим задачу о выборе места строительства железнодорожной станции из учебников.
Условие задачи. Пять населенных пунктов расположены вблизи прямолинейного участка железной дороги. Требуется выбрать место строительства железнодорожной станции, исходя из следующего критерия: расстояние от станции до самого удаленного пункта должно быть минимально возможным.
Для решения задачи выбирается система координат, в которой ось Х направлена по железнодорожной линии. В этой системе задаются координаты населенных пунктов. Допустим, что расстояние между самыми удаленными в направлении оси Х пунктами равно 10 км. Начало координат выберем так, чтобы Х-координата самого левого пункта была равна 0. Тогда Х-координата самого правого пункта будет равна 10. Пусть координаты всех населенных пунктов в этой системе будут следующими:
1 - (0, 6); 2 - (2, 4); 3 - (5, -3); 4 - (7, 3); 5 - (10, 2).
В данном списке указан порядковый номер пункта и его координаты.
Ниже приводится проект электронной таблицы (табл. 10.3), решающей эту задачу.
Таблица 3
| А | В | С | D | Е | F | G | Н | I | |
| 1 | Шаг= | 2 | км | ||||||
| 2 | Координаты
| Положение | станции | ||||||
| 3 | № | X | У | 0 | DЗ+$Е$1 | ЕЗ+$Е$1 | FЗ+$Е$1 | C3+$Е$1 | НЗ+$Е$1 |
| 4 | 1 | 0 | 6 | К(1,1) | R(1,2) | R(1,3) | R(1,4) | R(1,5) | R(1,6) |
| 5 | 2 | 2 | 4 | R(2,1) | R(2,2) | R(2,3) | R(2,4) | R(2,5) | R(2,6) |
| 6 | 3 | 5 | -3 | R(3,1) | R(3,2) | R(3,3) | R(3,4) | R(3,5) | R(3,6) |
| 7 | 4 | 7 | 3 | R(4,1) | R(4,2) | R(4,3) | R(4,4) | R(4,5) | R(4,6) |
| 8 | 5 | 10 | 2 | R(5,1) | R(5,2) | R(5,3) | R(5,4) | R(5,5) | R(5,6) |
| 9 | Макс.: | Мах (D4.-D8) | Мах (Е4.-Е8) | Мах (F4.-F8) | Мах (G4:G8) | Мах (Н4:Н8) | Мах (I4:I8) | ||
| 10 | Миним. | расст.: | Min (D9:D9) | ||||||
Для решения задачи применяется метод дискретизации: на участке железной дороги, ограниченном Х координатами от 0 до 10, рассматривается конечное число возможных положений станции, отстоящих друг от друга на равных расстояниях (шаг дискретизации). Для каждого положения станции вычисляются расстояния до каждого населенного пункта и среди них выбирается наибольшее расстояние. Искомым результатом является положение станции, соответствующее минимальному из этих выбранных величин.
Очевидно, что точность найденного решения зависит от шага перемещения станции (шага дискретизации). В приведенной таблице идя уменьшения ее размера выбран довольно грубый шаг, равный 2 км. Тогда на всем участке помещается 5 таких шагов и, следовательно, анализируется 6 возможных положений станции (включая положение, соответствующее Х = 0).
В табл. 3 формулы вычисления расстояний условно обозначены R(i,j). Здесь первый индекс обозначает номер населенного пункта (от 1 до 5), а второй — номер положения станции (от 1 до 6). Вот примеры некоторых формул на языке электронной таблицы МS Ехсеl:
R(1,1) = КОРЕНЬ(($В4-D$3)^2+$С4^2)
R(1, 2) = КОРЕНЬ(($B5D$3)^2+$C5^2) и т.д.
Таблица 4
| А | В | С | D | Е | F | G | Н | I | |
| 1 | Шаг= | 2 | км | ||||||
| 2 | Координаты
| Положение | станции | ||||||
| 3 | № | X | У | 0 | 2 | 4 | 6 | 8 | 10 |
| 4 | 1 | 0 | 6 | 6,00000 | 6,32456 | 7.21110 | 8,48528 | 10,00000 | 11,66190 |
| 5 | 2 | 2 | 4 | 4,47214 | 4,00000 | 4.47214 | 5,65685 | 7,21110 | 8,94427 |
| 6 | 3 | 5 | -3 | 5,83095 | 4,24264 | 3.16228 | 3,16228 | 4,24264 | 5,83095 |
| 7 | 4 | 7 | 3 | 7,61577 | 5,83095 | 4.24264 | 3,16228 | 3,16228 | 4,24264 |
| 8 | 5 | 10 | 2 | 10,19800 | 8,24621 | 6.32456 | 4,47214 | 2,82843 | 2,00000 |
| 9 | Макс.: | 10,19800 | 8,24621 | 7.21110 | 8,48528 | 10,00000 | 11,66190 | ||
| 10 | Миним. | расст.: | 7.21110 | ||||||
В табл. 4 приведены числовые результаты расчетов решения данной задачи. Окончательный ответ следующий: железнодорожную станцию следует размещать в 4 км от начала координат. При этом самым удаленным от нее окажется населенный пункт номер 1 — на расстоянии 7,21 км. Следует иметь в виду, что полученный результат довольно грубый, поскольку его погрешность по порядку величины равна шагу (2 км).
Такой способ решения задачи оказывается, в некотором смысле, полуавтоматическим. Ученик приходит к окончательному ответу, анализируя полученную числовую таблицу. Визуально он определяет, какому положению станции соответствует (в каком столбце таблицы находится) найденное оптимальное расстояние 7,21 км. Если требуется уменьшить шаг дискретизации, то, изменив величину шага в ячейке Е1, нужно будет увеличивать число столбцов в расчетной таблице. Делается это легко, простым копированием столбцов. Максимальный размер электронной таблицы, хотя и ограничен, но все-таки достаточно большой (в Exsel — 256 столбцов). Правда, в этом случае придется подправить формулу в ячейке D10.
Все эти дополнительные проблемы компенсируются прозрачностью модели. Ученик видит все промежуточные результаты расчетов, видит весь механизм работы выбранной модели. Понятие вычислительного эксперимента становится для учеников более содержательным, более наглядным.
Электронная таблица — средство более высокого уровня, чем язык программирования. В то же время задача проектирования расчетной таблицы того же типа, что нами рассмотрена, совсем не тривиальна. Можно говорить о том, что язык электронных таблиц — это своеобразный язык программирования — язык табличных алгоритмов. Следовательно, этап алгоритмизации в табличном способе математического моделирования тоже присутствует. Большим достоинством электронных таблиц является возможность легко осуществлять графическую обработку данных, что бывает очень важным в математическом моделировании.
|
из
5.00
|
Обсуждение в статье: Линия моделирования и базы данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы