 |
Главная |


Математическая статистика
|
из
5.00
|
Математическая статистика — это наука, которая занимается получением, обработкой и анализом данных, характеризующих количественные закономерности жизни общества в неразрывной связи с их качественным содержанием. Статистика, в узком смысле — это совокупность данных о каком-либо процессе или явлении. Основной задачей математической статистики является выяснение вероятностных свойств совокупности: распределения, числовых характеристик и т. д. с применением методов теории вероятности, позволяющих оценить надёжность и точность выводов, делаемых на основании ограниченного статистического материала (выборки) Совокупность объектов, или совокупность значений какого-то признака объектов, называется генеральной совокупностью. Обычно из генеральной совокупности делают выборку, т.е. исследуют некоторые ее объекты. Выборочной совокупностью или просто выборкой называют совокупность случайно отобранных объектов. С помощью выборки оценивают генеральную совокупность по вероятным свойствам. Чтобы оценки были достоверными, выборка должна быть представительной, т.е. ее вероятностные свойства должны совпадать или быть близкими к свойствам генеральной совокупности. Часто под генеральной совокупностью понимают и исследуемую случайную величину. Для исследования случайной величины при постоянных условиях выполняются испытания. Совокупность полученных значений также называется выборкой и обрабатывается статистически. Методы статистической обработки выборки аналогичны в обоих случаях. При исследовании объектов можно фиксировать или измерять значение одного или нескольких признаков, т.е. речь может идти об одномерной или многомерной выборках.
Корреляционный анализ
Корреляционная таблица
Две случайные величины могут быть связаны либо функциональной, либо статистической зависимостью, либо быть независимыми. Строгая функциональная зависимость реализуется редко в реальной жизни, так как обе величины или одна из них могут быть подвержены еще действию случайных факторов, причем среди них могут быть и общие для обеих величин. В этом случае возникает статистическая зависимость. Статистической называют зависимость, при которой изменение одной из величин влечет изменение распределения другой. В частности, статистическая зависимость проявляется в том, что при изменении одной из величин изменяется среднее значение другой; в этом случае статистическую зависимость называют корреляционной.
Предположим, что рассматриваемые случайные величины Х и У связаны корреляционной зависимостью. Так как при большом числе наблюдений одно и то же значение x может встретиться nx раз, и значения y — ny раз, одна и та же пара чисел (х,у) — nxy раз. Поэтому данные наблюдений группируют, т.е. подсчитывают частоты nx, ny, nxy. Все сгруппированные данные записывают в виде таблицы, которую называют корреляционной.
| X|Y | 4527,24 | 5792,65 | 7058,07 | 8323,48 | 9588,89 | 10854,30 | 12119,72 | 13385,13 | 14650,55 | 15915,96 | 17181,38 | Nx |
| 0,626667 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 0,831333 | 0 | 6 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8 |
| 1,036 | 0 | 0 | 10 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 16 |
| 1,240667 | 0 | 0 | 0 | 9 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 15 |
| 1,445333 | 0 | 0 | 0 | 0 | 8 | 3 | 0 | 0 | 0 | 0 | 0 | 11 |
| 1,65 | 0 | 0 | 0 | 0 | 1 | 13 | 2 | 0 | 0 | 0 | 0 | 16 |
| 1,854667 | 0 | 0 | 0 | 0 | 0 | 1 | 10 | 1 | 0 | 0 | 0 | 12 |
| 2,059333 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 6 |
| 2,264 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 1 | 4 |
| 2,468667 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 1 | 4 |
| 2,673333 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 6 | 7 |
| Ny | 1 | 6 | 12 | 15 | 15 | 17 | 12 | 6 | 3 | 5 | 8 | n=100 |
Таблица 2. Корреляционная таблица
Характеристики значений выборки
На основе данных корреляционной таблицы можно посчитать все характеристики наблюдаемых значений выборки намного быстрее и проще, но они будут иметь некоторые отклонения от выборочных характеристик, посчитанных по формулам. Это объясняется уменьшением размеров рассматриваемых величин, которое происходит из-за разбиения их на интервалы.
Посчитаем числовые характеристики для Х и Y по корреляционной таблице.
М 
атематическое ожидание для выборочной совокупности называетсявыборочной средней и находится по формуле:
Выборочной дисперсией называют среднее арифметическое квадратов отклонения наблюдаемых значений признака от их среднего значения:
В 

ыборочным средним квадратичным отклонением называют квадратный корень из выборочной дисперсии:
Корреляционным моментом (ковариацией, смешанной дисперсией) случайных величин Х и Y называют математическое ожидание произведения отклонений этих величин:
kxy = M[(x – M(x))(y – M(y))].
К 

оэффициентом корреляции случайных величин Х и Y называют отношение корреляционного момента к произведению средних квадратичных отклонений этих величин: при условии
Для данной работы:
М*(X) = 1,57018; М*(Y) = 10639,18813;
D*(X) = 0,278051305; D*(Y) = 10313962,39;
s* (X)= 0,527305704; s*(Y) = 3211,53583.
r*xy = 0,985735993; k*xy = 1671,654574.
Графический способ анализа данных
В данной курсовой работе необходимо наглядно изобразить различные зависимости величин друг от друга. Одним из лучших средств визуального изображения зависимостей являются:
· диаграмма рассеивания;
· гистограмма рассеяния;
· полигон относительных частот
· линейная регрессия .
· эмпирическая функция распределения
Диаграмма рассеивания
Диаграмма рассеивания получается путем нанесения данных всех пар чисел (100) на координатную плоскость (см. приложение, рис.1).
Гистограммы рассеивания
Гистограммы рассеивания также являются одним из способов наглядного представления распределения значений случайной величины. В данной курсовой построены гистограммы рассеивания относительных частот для случайных величин Х (уровень радиации) и Y (количество лейкоцитов в крови человека). Гистограммой относительных частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которых служат частичные интервалы длиной h, а высоты равны отношению pi*/n , (n –– общее количество точек). Приведем гистограмму относительных частот распределения уровня радиации и гистограмму относительных частот для количества лейкоцитов в крови человека (см. приложение, рис. 2, 3).
Полигон относительных частот — ломаная, соединяющая точки (x1, W1)…(xn, Wn). Для построения полигона относительных частот на оси абсцисс откладывают варианты xi, а на оси ординат — соответствующие им относительные частоты Wi. Приведены полигоны относительных частот распределения уровня радиации и количества лейкоцитов в крови человека (см. приложение, рис.4,5) Эмпирической функцией распределения называют функцию F*(x), определяющую для каждого значения x относительную частоту события X<x.
По определению, F*(x)=nx/n, где nx — число вариант , меньших x; n — объем выборки.
Функции распределения X и Y имеют вид (см. приложение, Рис. 6, 7).
Регрессионный анализ
Между переменными X и Y существует функциональная связь у = f(x), т.е. каждому значению аргумента Х соответствует единственное значение аргумента Y. Регрессия — зависимость среднего значения какой-либо величины Y от другой величины X. Понятие регрессии в некотором смысле обобщает понятие функциональной зависимости у = f(x). Только в случае регрессии одному и тому же значению x в различных случаях соответствуют различные значения y.
Регрессионный анализ заключается в определении аналитического выражения связи, в котором изменения одной величины (называемой зависимой или результативным признаком) обусловлено влиянием одной или нескольких независимых величин (факторов).
По форме зависимости различают:
1). Линейную регрессию, которая выражается уравнением прямой — линейной функцией вида: у =ax+b.
Если в результате n экспериментов точки на диаграмме рассеивания расположены таким образом, что прослеживается тенденция роста Y при росте X, то это предположение о линейной зависимости: у = f(x).
Эта зависимость определяется двумя параметрами — а и b. Подобрав эти параметры, можно получить уравнение регрессии.
2). Нелинейную (параболическую) регрессию: у =ах2 +bх+с.
3). Полиномную регрессию
— полином первой степени: у =ах+b (линейная регрессия);
— полином второй степени: у = ах2 +bх+с (параболическая регрессия);
— полином n-ой степени: y = anxn + … + a2x2 + a1x + a0.
Целью регрессионного анализа является оценка функциональной зависимости результативного признака (у) от факторных (x1, x2, …,Xn).
Метод наименьших квадратов (МНК)
Найдем по данным наблюдений выборочное уравнение прямой линии у = ах+b среднеквадратичной регрессии Y на X.
Это можно сделать с помощью метода наименьших квадратов (МНК). Этот метод, применяется в теории ошибок, для отыскания одной или нескольких величин по результатам измерений, содержащих случайные ошибки. МНК также используется для приближенного представления заданной функции другими (более простыми) функциями и часто оказывается полезным для обработки наблюдений.
Для того чтобы определить параметры a и b необходимо знать отклонения
(точки, находящиеся не на на прямой, а рядом). Суммарное отклонение будет равно:
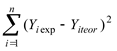
где Yiexp — экспериментальные точки (не обязательно лежащие на прямой), Yiteor — теоретические точки (лежащие на прямой).
Ч 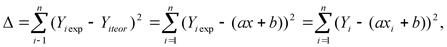
тобы все отклонения давали в суммарном отклонении положительные числа, надо возвести в квадрат эти отклонения:
где Δ — суммарное квадратичное отклонение, которое зависит от параметрова и b, Yi— экспериментальные значения Y, axi + b — теоретические значения Y.
Лучшими параметрами а и b являются такие, которые минимизируют Δ, следовательно, среди бесконечного множества прямых, которых дает прямая у = ax + b, наилучшей является прямая с такими значениями параметров а и b, для которых Δ(а, b) принимает минимальное значение.
Чтобы найти эти значения параметров а и b, необходимо найти точку минимума функции Δ(а, b). Для этого берется производная

и рассматривается система двух уравнений, решения которой — значения a и b:
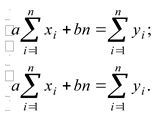
Для данных курсовой работы получаем:
a = 6041,9;
b = 1115,6.
Т.е. y = 6041,9x + 1115,6;
По тем же данным курсовой работы вычислим коэффициенты уравнения параболической регрессии.
Параболическое уравнение регрессии Y на X имеет вид
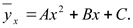
Неизвестные параметры A, B,C находят из системы уравнений:
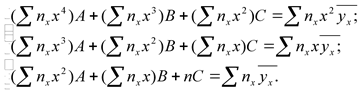
Для данных курсовой работы получаем:
A=-69,58; B=6266,7; C=954,82.
т.е. y =–69,58x2+6266,7x+954,82
Линии регрессий на диаграмме рассеивания имеют вид (см. приложение, рис. 8, 9).
На рис.10 приложения — сравнение двух регрессий.
Какая регрессия соответствует исходным данным:
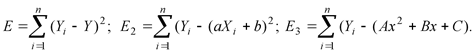
E2=7,93079*10-10
E3=8,0945*10-11
E2>E3  это параболическая регрессия.
это параболическая регрессия.
|
из
5.00
|
Обсуждение в статье: Математическая статистика |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы