 |
Главная |


Математические модели надёжности комплексов программ
|
из
5.00
|
Математические модели позволяют оценивать характеристики ошибок в программах и прогнозировать их надёжность при проектировании и эксплуатации. Модели имеют вероятностный характер, и достоверность прогнозов зависит от точности исходных данных и глубины прогнозирования по времени. Эти математические модели предназначены для оценки:
- показателей надёжности комплексов программ в процессе отладки;
- количества ошибок, оставшихся невыявленными;
- времени, необходимого для обнаружения следующей ошибки в функционирующей программе;
- времени, необходимого для выявления всех ошибок с заданной вероятностью.
Использование моделей позволяет эффективно и целеустремлённо проводить отладку и испытания комплексов программ, помогает принять рациональное решение о времени прекращения отладочных работ.
В настоящее время предложен ряд математических моделей, основными из которых являются:
- экспоненциальная модель изменения ошибок в зависимости от времени отладки;
- модель, учитывающая дискретно - понижающуюся частоту появления ошибок как линейную функцию времени тестирования и испытаний;
- модель, базирующаяся на распределении Вейбула;
- модель, основанная на дискретном гипергеометрическом распределении.
При обосновании математических моделей выдвигаются некоторые гипотезы о характере проявления ошибок в комплексе программ. Наиболее обоснованными представляются предположения, на которых базируется первая экспоненциальная модель изменения ошибок в процессе отладки и которые заключаются в следующем:
1. Любые ошибки в программе являются независимыми и проявляются в случайные моменты времени.
2. Время работы между ошибками определяется средним временем выполнения команды на данной ЭВМ и средним числом команд, исполняемым между ошибками. Это означает, что интенсивность проявления ошибок при реальном функционировании программы зависит от среднего быстродействия ЭВМ.
3. Выбор отладочных тестов должен быть представительным и случайным, с тем чтобы исключить концентрацию необнаруженных ошибок для некоторых реальных условий функционирования программы.
4. Ошибка, являющаяся причиной искажения результатов, фиксируется и исправляется после завершения тестирования либо вообще не обнаруживается.
Из этих свойств следует, что при нормальных условиях эксплуатации количество ошибок, проявляющихся в некотором интервале времени, распределено по закону Пуассона. В результате длительность непрерывной работы между искажениями распределена экспоненциально.
Предположим, что в начале отладки комплекса программ при t = 0 в нём содержалось  ошибок. После отладки в течении времени t осталось
ошибок. После отладки в течении времени t осталось  ошибок и устранено n ошибок ( + n = ). При этом время t соответствует длительности исполнения программ на вычислительной системе (ВС) для обнаружения ошибок и не учитывает простои машины, необходимые для анализа результатов и проведения корректировок.
ошибок и устранено n ошибок ( + n = ). При этом время t соответствует длительности исполнения программ на вычислительной системе (ВС) для обнаружения ошибок и не учитывает простои машины, необходимые для анализа результатов и проведения корректировок.
Интенсивность обнаружения ошибок в программе dn/dt и абсолютное количество устранённых ошибок связываются уравнением
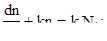 (3.13)
(3.13)
где k - коэффициент.
Если предположить, что в начале отладки при t = 0 отсутствуют обнаруженные ошибки, то решение уранения (3.13) имеет вид
 (3.14)
(3.14)
Количество оставшихся ошибок в комплексе программ

пропорционально интенсивности обнаружения dn/dt с точностью до коэффициента k.
Время безотказной работы программ до отказа T или наработка на отказ, который рассматривается как обнаруживаемое искажение программ, данных или вычислительного процесса, нарушающее работоспособность, равно величине, обратной интенсивности обнаружения отказов (ошибок):
 (3.15)
(3.15)
Если учесть, что до начала тестирования в комплексе программ содержалось ошибок и этому соответствовала наработка на отказ  , то функцию наработки на отказ от длительности проверок можно представить в следующем виде:
, то функцию наработки на отказ от длительности проверок можно представить в следующем виде:
 (3.16)
(3.16)
Если известны моменты обнаружения ошибок  и каждый раз в эти моменты обнаруживается и достоверно устраняется одна ошибка, то, используя метод максимального правдоподобия, можно получить уравнение для определения значения начального числа ошибок :
и каждый раз в эти моменты обнаруживается и достоверно устраняется одна ошибка, то, используя метод максимального правдоподобия, можно получить уравнение для определения значения начального числа ошибок :
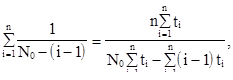 (3.17)
(3.17)
а также выражение для расчёта коэффициента пропорциональности
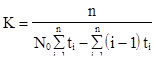 ; (3.18)
; (3.18)
В результате можно рассчитать число оставшихся в программе ошибок и среднюю наработку на отказ Tср = 1/l , т.е. получить оценку времени до обнаружения следующей ошибки.
В процессе отладки и испытаний программ для повышения наработки на отказ от 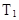 до
до  необходимо обнаружить и устранить Dn ошибок. Величина Dn определяется соотношением:
необходимо обнаружить и устранить Dn ошибок. Величина Dn определяется соотношением:
 ; (3.19)
; (3.19)
Выражение для определения затрат времени Dt на проведение отладки, которые позволяют устранить Dn ошибок и соответственно повысить наработку на отказ от значения до , имеет вид:
 (3.20)
(3.20)
Вторая модель построена на основе гипотезы о том, что частота проявления ошибок (интенсивность отказов) линейно зависит от времени испытания между моментами обнаружения последовательных i - й и (i - 1) - й ошибок.
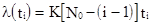 , (3.21)
, (3.21)
где - начальное количество ошибок; K - коэффициент пропорциональности, обеспечивающий равенство единице площади под кривой вероятности обнаружения ошибок.
Для оценки наработки на отказ получается выражение, соответствующее распределению Релея:
 (3.22)
(3.22)
где  .
.
Отсюда плотность распределения времени наработки на отказ
 . (3.23)
. (3.23)
Использовав функцию максимального правдоподобия, получим оценку для общего количества ошибок и коэффициента K.
 (3.24)
(3.24)
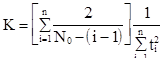 (3.25)
(3.25)
Особенностью третьей модели является учёт ступенчатого характера изменения надёжности при устранении очередной ошибки. В качестве основной функции рассматривается распределение времени наработки на отказ P(t). Если ошибки не устраняются, то интенсивность отказов является постоянной, что приводит к экспоненциальной модели для распределения:

Отсюда плотность распределения наработки на отказ T определяется выражением:

где t > 0, l > 0 и 1/l - среднее время наработки на отказ, т.е. Тср=1/l. Здесь Тср - среднее время наработки на отказ.
Для аппроксимации изменения интенсивности от времени при обнаружении и устранении ошибок используется функция следующего вида:
 ;
;
Если 0 < b < 1, то интенсивность отказов снижается по мере отладки или в процессе эксплуатации. При таком виде функции l(t) плотность функции распределения наработки на отказ описывается двухпараметрическим распределением Вейбулла:
 .
.
Распределение Вейбулла достаточно хорошо отражает реальные зависимости при расчёте функции наработки на отказ.
|
из
5.00
|
Обсуждение в статье: Математические модели надёжности комплексов программ |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы