 |
Главная |


Общее описание технологии хранилищ данных
|
из
5.00
|
Хранилище данных и OLAP-технология, как правило, упоминаются вместе, хотя на самом деле это две разные технологии. Хранилище данных (ХД) обеспечивает сбор, хранение и быстрый доступ к ключевой информации, создаваемой в учетных системах (OLTP), а OLAP — построение высокоинтерактивных отчетов, анализ данных. Вместе с тем, как правило, в комплексных решениях обе технологии применяются как неразрывное целое, поэтому их совместное рассмотрение вполне оправдано. Пользователями этих продуктов являются менеджеры и ведущие специалисты, люди, от которых зависят принятие ключевых решений, оперативное и стратегическое планирование и управление.
Задачей хранилища данных является интеграция, актуализация и согласование оперативных данных из разнородных источников для формирования единого непротиворечивого взгляда на объект управления в целом. На основе хранилищ данных возможно составление всевозможной отчетности, а также проведение оперативной аналитической обработки и Data Mining.
Рассмотрим несколько определений ХД.
Хранилище данных (Data Warehouse) — это система, предназначенная для информационного обеспечения управления организацией, интегрирующая в себе данные, необходимые для управления, из учетных автоматизированных систем, консолидирующая данные филиалов. Хранилище собирает, очищает, загружает, агрегирует, хранит данные и предоставляет к ним быстрый доступ.
Еще одно определение:
Хранилище данных – система, содержащая непротиворечивую интегрированную предметно-ориентированную совокупность исторических данных крупной корпорации или иной организации с целью поддержки принятия стратегических решений.
Хранилище данных предоставляет разнообразные инструментальные средства для анализа данных. Информационные ресурсы хранилища данных формируются на основе извлечения на протяжении продолжительного периода времени моментальных снимков баз данных операциональной информационной системы данной корпорации и, возможно, также из различных внешних источников. Потребности аналитической обработки данных для поддержки принятия решений не согласуются с условиями функционирования и особенностями операциональных информационных систем. Именно в связи с этим обстоятельством и возникает потребность в самостоятельном источнике данных для таких целей. На практике используются как централизованные, так и распределенные хранилища данных. Объем представленных в них данных обычно является весьма большим и может достигать многих гигабайт, что предъявляет особые требования к механизмам их функционирования.
Хранилища данных используют технологии баз данных, OLAP, глубинного анализа данных, визуализации данных. Термин Data Warehouse был введен Б. Инмоном (Bill Inmon) в 1990 г.
Билл Инмон определяет хранилища данных как "предметно ориентированные, интегрированные, неизменчивые, поддерживающие хронологию наборы данных, организованные с целью поддержки управления" и призванные выступать в роли "единого и единственного источника истины", который обеспечивает менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений.
Предметная ориентация хранилища данных означает, что данные объединены в категории и сохраняются соответственно областям, которые они описывают, а не применениям, их использующим.
Интегрированность означает, что данные удовлетворяют требованиям всего предприятия, а не одной функции бизнеса. Этим хранилище данных гарантирует, что одинаковые отчеты, сгенерированные для разных аналитиков, будут содержать одинаковые результаты.
Привязка ко времени означает, что хранилище можно рассматривать как совокупность "исторических" данных: возможно восстановление данных на любой момент времени. Атрибут времени явно присутствует в структурах хранилища данных.
Неизменность означает, что, попав один раз в хранилище, данные там сохраняются и не изменяются. Данные в хранилище могут лишь добавляться.
Ричард Хакаторн, другой основоположник этой концепции, писал, что цель Хранилищ Данных - обеспечить для организации "единый образ существующей реальности".
Другими словами, хранилище данных представляет собой своеобразный накопитель информации о деятельности предприятия.
Хранилище данных специализированное (Data Mart) – хранилище данных, связанных с какими-либо конкретными аспектами деятельности организации. Используется для поддержки принятия решений в интересах какого-либо подразделения организации или обеспечения какой-либо сферы ее деятельности. Источником данных для специализированного хранилища данных может быть общее хранилище данных организации, или оно создается и функционирует независимо. Объем данных в специализированном хранилище данных и его потребности в вычислительных ресурсах обычно существенно ограничены по сравнению с общим хранилищем данных. В отечественной компьютерной периодике термин Data Mart часто переводят как "витрина данных".
Преимущества использования хранилищ данных в сравнении с использованием оперативных систем или баз данных:
ü В отличие от оперативных систем, хранилище данных содержит информацию за весь требуемый временной интервал - вплоть до нескольких десятилетий - в едином информационном пространстве, что делает такие хранилища идеальной основой для выявления трендов, сезонных зависимостей и других важных аналитических показателей.
ü Как правило, информационные системы предприятия хранят и представляют аналогичные данные по-разному. Например, одни и те же показатели могут храниться в различных единицах измерения. Одна и та же продукция или одни и те же клиенты могут именоваться по-разному. В системах хранилищ несоответствия в данных устраняются на этапе сбора информации и погружения ее в единую базу данных. При этом организуются единые справочники, все показатели в которых приводятся к одинаковым единицам измерения.
ü Очень часто оперативные системы вследствие ошибок операторов содержат некоторое количество неверных данных. На этапе помещения в хранилище данных информация предварительно обрабатывается. Данные по специальной технологии проверяются на соответствие заданным ограничениям и при необходимости корректируются (очищаются). Технология обеспечивает построение аналитических отчетов на основе надежных данных и своевременное оповещение администратора хранилища об ошибках во входящей информации.
ü Универсализация доступа к данным. Хранилище данных предоставляет уникальную возможность получать любые отчеты о деятельности предприятия на основе одного источника информации. Это позволяет интегрировать данные, вводимые и накапливаемые в различных оперативных системах, легко и просто сравнивать их. При этом в процессе создания отчетов пользователь не связан различиями в доступе к данным оперативных систем.
ü Ускорение получения аналитических отчетов. Получение отчетов при помощи средств, предоставляемых оперативными системами, - способ неоптимальный. Эти системы затрачивают значительное время на агрегирование информации (расчет суммарных, средних, минимальных, максимальных значений). Кроме того, в текущей базе оперативной системы находятся только самые необходимые и свежие данные, в то время как информация за прошлые периоды помещается в архив. Если данные приходится получать из архива, продолжительность построения отчета возрастает еще в два-три раза. Следует также учитывать, что сервер оперативной системы зачастую не обеспечивает необходимую производительность при одновременном построении сложных отчетов и вводе информации. Это может катастрофически сказываться на работе предприятия, так как операторы не смогут оформлять накладные, фиксировать отгрузку или получение продукции в то время, когда выполняется построение очередного отчета. Хранилище данных позволяет решить эти проблемы. Во-первых, работа сервера хранилища не мешает работе операторов. Во-вторых, в хранилище помимо детальной информации содержатся и заранее рассчитанные агрегированные значения. В-третьих, в хранилище архивная информация всегда доступна для включения в отчеты. Все это позволяет значительно сократить время создания отчетов и избежать проблем в оперативной работе.
ü Построение произвольных запросов. Информацию в хранилище данных недостаточно только централизовать и структурировать. Аналитику нужны средства визуализации этой информации, инструмент, с помощью которого легко получать данные, необходимые для принятия своевременных решений. Одно из главных требований любого аналитика - простота формирования отчетов и их наглядность. В случае оперативных систем построение отчетов часто лишено гибкости; чтобы создать новый отчет, приходится задействовать специалистов ИТ-отдела, которые объединяют данные нескольких систем. В случае же использования хранилища данных решение проблемы предоставляет технология OLAP (On-Line Analytical Processing). Эта технология обеспечивает доступ к данным в терминах, привычных для аналитика. Технология OLAP базируется на концепции многомерного представления данных. Действительно, каждое числовое значение, содержащееся в хранилище данных, имеет до нескольких десятков атрибутов (например, количество продаж определенным менеджером в определенном регионе на определенную дату и т.п.). Таким образом, можно считать, что работа идет с многомерными структурами данных (многомерными кубами), в которых числовые значения расположены на пересечении нескольких измерений. Именно этот подход используется в OLAP-системах. Они предоставляют гибкие средства навигации по многомерным структурам - так называемые OLAP-манипуляции. С их помощью аналитик может получать различные срезы данных, "крутить" данные.
Общий принцип работы ХД состоит в следующем: в оперативных OLTP-системах выполняются учетные операции, ежедневно, в конце операционного дня (или чаще), данные из учетных систем поступают в Хранилище, откуда выпускаются управленческие отчеты.
В отличие от учетных информационных систем, Хранилища данных изначально технологически оптимизированы не для ввода, а для быстрого поиска и анализа информации. Поэтому такие системы имеют принципиально другую архитектуру базы данных, обеспечивающую высокую скорость выполнения запросов к огромным массивам информации. Как правило, структура ХД денормализована (это позволяет повысить скорость выполнения запросов), поэтому может допускать избыточность данных. ХД отличает иное построение пользовательского интерфейса, предоставляющего специальные средства поиска информации, ее обобщения, углубления в детали.
Современное Хранилище данных не только собирает данные, но и позволяет изменять их — расставлять аналитические признаки, выполнять управленческие корректировки, довводить недостающие (например, неизвестные филиалам) данные.
Хранилище данных состоит из нескольких функциональных блоков.
· База данных. Принципиальное отличие базы данных ХД состоит в том, что ее структура оптимизирована для быстрой загрузки и быстрого извлечения данных, а не для быстрого выполнения транзакций. В случае реализации на основе реляционной БД (ROLAP) основными составляющими структуры хранилища данных являются таблица фактов (fact table) и таблицы измерений (dimension tables), а основными схемами организации – схема «звезда» и схема «снежинка».
· Инструменты настройки базы данных и управления метаданными. Эти инструменты предназначены для настройки информационной модели Хранилища данных при внедрении и изменении этой модели в процессе эксплуатации, для постепенного расширения функциональности Хранилища данных.
· Инструменты сбора, очистки и загрузки данных. Специальная технология сбора данных обеспечивает регулярное и бесперебойное получение данных из удаленных филиалов, дополнительных офисов, из различных информационных систем. Она включает в себя форматы данных, технологию их генерации, бизнес-правила, регламентирующие извлечение данных из внешних источников, дистрибуцию метаданных (нормативно-справочной информации) и многое другое. Кроме того, ХД обеспечивает входной контроль данных, автоматическое исправление ошибок, приведение данных к единым стандартам, загрузку больших массивов данных, многоуровневую журнализацию.
Для сбора данных из внешних источников и удаленных подразделений применяются два принципиально разных подхода.
1) ETL-системы. Первый способ сбора данных - применение средств ETL (Extract, Transformation, Loadin g – извлечение, трансформация, загрузка) – специальных систем для извлечения данных из других баз данных, трансформации по описанным в этой системе правилам и загрузке в ХД.
2) Корпоративный стандарт формата обмена данными. Второй подход — применение стандартного формата для сбора данных и разработка процедур выгрузки данных на стороне источника. Это позволяет, во-первых, собирать однородные данные из разнородных систем, децентрализовать разработку процедур выгрузки данных, предоставляя решение этой задачи специалистам, обладающим знанием об исходной системе.
· Аппарат выполнения расчетов. Специальный аппарат выполнения расчетов обеспечивает:
ü агрегацию данных — расчет обобщенных показателей (например, вычисление месячного, квартального и годового баланса);
ü консолидацию данных — суммирование данных по организационной иерархии (например, вычисление сводного баланса банка);
ü расчет производных показателей (таких, как фактическое исполнение бюджета, ликвидность, маржа и др.).
· Механизмы выполнения произвольных запросов. Чем шире номенклатура данных, собираемых в ХД, тем сложнее их связи и многообразнее запросы, которые пользователи хотят выполнять к базе данных. Это делает практически невозможными разработку и оптимизацию запросов, включающую создание необходимых индексов, на этапе создания системы. Поэтому неотъемлемой частью ХД являются средства генерации запросов. В продвинутых системах одновременно с запросом могут генерироваться и недостающие индексы для повышения скорости его выполнения.
· Пользовательские интерфейсы и отчеты. Хранилище данных, накапливая ценную информацию, должно обеспечивать ее максимальное использование сотрудниками. Для этого оно имеет специальные пользовательские интерфейсы, разработанные для быстрого получения данных, и развитую технологию создания и выпуска отчетов. Интерфейсы для внешних систем. Хранилище данных предоставляет информацию внешним аналитическим системам и генераторам отчетов, для чего применяются промышленные стандарты доступа к данным.
Т.о., конечным продуктом Хранилища данных является отчет. Большое корпоративное ХД должно обеспечивать выпуск всех видов отчетов, требующихся организации. Для этого ХД должно иметь встроенные инструменты настройки и выпуска отчетов или быть интегрировано с внешними специализированными системами:
ü генераторами отчетов;
ü OLAP-инструментами;
ü электронными таблицами.
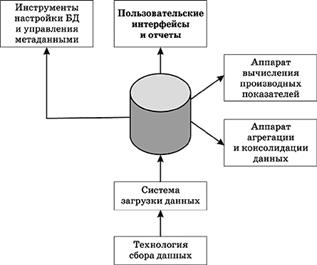
Рис. 2.10 . Архитектура Хранилища данных
2.12. Data Mining[23]
Что такое Data Mining
Корпоративная база данных любого современного предприятия обычно содержит набор таблиц, хранящих записи о тех или иных фактах либо объектах (например, о товарах, их продажах, клиентах, счетах). Как правило, каждая запись в подобной таблице описывает какой-то конкретный объект или факт. Например, запись в таблице продаж отражает тот факт, что такой-то товар продан такому-то клиенту тогда-то таким-то менеджером, и по большому счету ничего, кроме этих сведений, не содержит. Однако совокупность большого количества таких записей, накопленных за несколько лет, может стать источником дополнительной, гораздо более ценной информации, которую нельзя получить на основе одной конкретной записи, а именно — сведений о закономерностях, тенденциях или взаимозависимостях между какими-либо данными. Примерами подобной информации являются сведения о том, как зависят продажи определенного товара от дня недели, времени суток или времени года, какие категории покупателей чаще всего приобретают тот или иной товар, какая часть покупателей одного конкретного товара приобретает другой конкретный товар, какая категория клиентов чаще всего вовремя не отдает предоставленный кредит.
Подобного рода информация обычно используется при прогнозировании, стратегическом планировании, анализе рисков, и ценность ее для предприятия очень высока. Видимо, поэтому процесс ее поиска и получил название Data Mining (mining по-английски означает «добыча полезных ископаемых», а поиск закономерностей в огромном наборе фактических данных действительно сродни этому). Термин Data Mining обозначает не столько конкретную технологию, сколько сам процесс поиска корреляций, тенденций, взаимосвязей и закономерностей посредством различных математических и статистических алгоритмов: кластеризации, создания субвыборок, регрессионного и корреляционного анализа.
Цель этого поиска — представить данные в виде, четко отражающем бизнес-процессы, а также построить модель, при помощи которой можно прогнозировать процессы, критичные для планирования бизнеса (например, динамику спроса на те или иные товары или услуги либо зависимость их приобретения от каких-то характеристик потребителя).
Отметим, что традиционная математическая статистика, долгое время остававшаяся основным инструментом анализа данных, равно как и средства оперативной аналитической обработки данных (online analytical processing, OLAP), не всегда могут успешно применяться для решения таких задач. Обычно статистические методы и OLAP используются для проверки заранее сформулированных гипотез. Однако нередко именно формулировка гипотезы оказывается самой сложной задачей при реализации бизнес-анализа для последующего принятия решений, поскольку далеко не все закономерности в данных очевидны с первого взгляда.
В основу современной технологии Data Mining положена концепция шаблонов, отражающих закономерности, свойственные подвыборкам данных. Поиск шаблонов производится методами, не использующими никаких априорных предположений об этих подвыборках. Если при статистическом анализе или при применении OLAP обычно формулируются вопросы типа «Каково среднее число неоплаченных счетов заказчиками данной услуги?», то применение Data Mining, как правило, то подразумевает ответы на вопросы типа «Существует ли типичная категория клиентов, не оплачивающих счета?». При этом именно ответ на второй вопрос нередко обеспечивает более нетривиальный подход к маркетинговой политике и к организации работы с клиентами.
Ниже представлены другие сравнительные примеры вопросов, характерных для OLAP и Data Mining.
| OLAP | Data Mining |
| Каковы средние показатели травматизма для курящих и некурящих? | Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму? |
| Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов (отказавшихся от услуг телефонной компании)? | Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании? |
| Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? | Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными карточками? |
Важной особенностью Data Mining является нестандартность и неочевидность разыскиваемых шаблонов. Иными словами, средства Data Mining отличаются от инструментов статистической обработки данных и средств OLAP тем, что вместо проверки заранее предполагаемых пользователями взаимозависимостей они на основании имеющихся данных способны находить такие и строить гипотезы об их характере.
Следует отметить, что применение средств Data Mining не исключает использования статистических инструментов и OLAP-средств, поскольку результаты обработки данных с помощью последних, как правило, способствуют лучшему пониманию характера закономерностей, которые следует искать.
2.12.2. Понятие Data Mining[24]
Технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро (Gregory Piatetsky-Shapiro) - один из основателей этого направления:
Data Mining – это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Суть и цель технологии Data Mining можно охарактеризовать так: это технология, которая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей.
Неочевидных – это значит, что найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным путем.
Объективных – это значит, что обнаруженные закономерности будут полностью соответствовать действительности, в отличие от экспертного мнения, которое всегда является субъективным.
Практически полезных – это значит, что выводы имеют конкретное значение, которому можно найти практическое применение.
Знания – совокупность сведений, которая образует целостное описание, соответствующее некоторому уровню осведомленности об описываемом вопросе, предмете, проблеме и т.д.
Использование знаний (knowledge deployment) означает действительное применение найденных знаний для достижения конкретных преимуществ (например, в конкурентной борьбе за рынок).
Приведем еще несколько определений понятия Data Mining.
Data Mining – это процесс выделения из данных неявной и неструктурированной информации и представления ее в виде, пригодном для использования.
Data Mining – это процесс выделения, исследования и моделирования больших объемов данных для обнаружения неизвестных до этого структур (patterns) с целью достижения преимуществ в бизнесе (определение SAS Institute).
Data Mining – это процесс, цель которого - обнаружить новые значимые корреляции, образцы и тенденции в результате просеивания большого объема хранимых данных с использованием методик распознавания образцов плюс применение статистических и математических методов (определение Gartner Group).
Как было сказано выше, в основу технологии Data Mining положена концепция шаблонов (patterns), которые представляют собой закономерности, свойственные подвыборкам данных, которые могут быть выражены в форме, понятной человеку.
"Mining" по-английски означает "добыча полезных ископаемых", а поиск закономерностей в огромном количестве данных действительно сродни этому процессу.
Цель поиска закономерностей – представление данных в виде, отражающем искомые процессы. Построение моделей прогнозирования также является целью поиска закономерностей.
|
из
5.00
|
Обсуждение в статье: Общее описание технологии хранилищ данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы