 |
Главная |


Тема 3. Адаптивные методы прогнозирования
|
из
5.00
|
Задание. Построение прогнозов на основе методов экспоненциального сглаживания, моделей Брауна и Хольта.
Исполнение: выполнение индивидуального задания с использованием ППП Statistica 6.0 и Statgraphics. Интерпретация результатов решения.
Оценка. Практическая реализация теоретических методов прогнозирования.
Время выполнения заданий: 4 часа.
Методические указания
На основе исходных данных (таблица 5) необходимо построить модели по рядам динамики, выполнить прогноз.
Таблица 5 – Исходные данные для лабораторной работы №3
| Год | Темп прироста производительности труда, % | Год | Темп прироста производительности труда, % |
| 1 | 10 | 15 | 4 |
| 2 | 6,4 | 16 | 6,2 |
| 3 | 6,8 | 17 | 6,9 |
| 4 | 8 | 18 | 6,1 |
| 5 | 11,1 | 19 | 5,1 |
| 6 | 6,7 | 20 | 7 |
| 7 | 6,9 | 21 | 6,5 |
| 8 | 7 | 22 | 5,3 |
| 9 | 8,2 | 23 | 6,3 |
| 10 | 6,1 | 24 | 6,4 |
| 11 | 3,8 | 25 | 5,8 |
| 12 | 6 | 26 | 3,4 |
| 13 | 5,2 | 27 | 4,1 |
| 14 | 2,9 |
Введем исходные данные. Переименуем показатели: год – t, темп прироста производительности труда – у.
Выберем процедуру Forecasting (прогнозирование) в модуле Time - Series Analysis (анализ временных рядов) из пункта Special (специальный) главного меню (рис. 2).

Рисунок 2 – Меню Special
Система выдаст входную панель Forecasting (рис. 3).
Введем в поле Date имя переменной у, установим переключатель Year ( s ). Number of Forecasts (период упреждения) примем равным пяти (рис. 3). Остальные поля оставим без изменения.

Рисунок 3 – Входная панель процедуры прогнозирования
STATGRAPHICS выдаст сводку предварительного анализа. Щелкнем на панели правой кнопкой мыши и во всплывшем меню выберем Analysis Options (опции анализа). STATGRAPHICS выведет панель Model Specification Options (опции спецификации модели). Она представлена на рис. 4.
Устанавливаем Linear Trend / OK. Система построит линейную модель (рис. 4).

Рис. 4 – Панель спецификации моделей прогнозирования
Вызовем панель Graphical Options (графические опции) и отметим флажком пункт Time Sequence Plot (график временной последовательности). STATGRAPHICS построит искомый график (рис. 5).
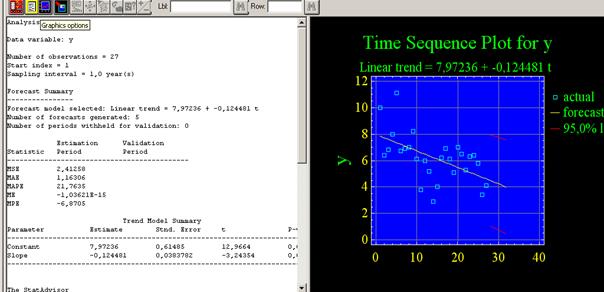
Рис. 5 – Окно анализа процедуры прогнозирования
Двойным щелчком левой кнопки мыши можно максимизировать или минимизировать панель. Щелчок правой кнопкой вызывает контекстное меню, пункты которого зависят от выбранной процедуры и типа панели (графическая или текстовая).
Результаты проведенного анализа можно сохранить в файле StatFolio .
В прогнозировании помимо построения линейного тренда используется широкий набор моделей. Динамические ряды также нуждаются в предварительном анализе. Данные процедуры позволяет сделать модуль в STATGRAPHICS Time - Series Analysis . Основные процедуры данного модуля представлены в таблице 6.
Используя процедуры сглаживания STATGRAPHICS, устраним случайные колебания исследуемого временного ряда. Воспользуемся процедурой Simple Moving Average, далее EWMA и Resistant Nonlinear Smoothing.
Выберем в модуле Time-Series Analysis процедуру Smoothing. Появится панель ввода, которая аналогична панели Forecasting. Введем имя переменной и установим переключатель Year ( s ) (рис. 6). ОК.
Таблица 6 – Основные процедуры модуля АВР STATGRAPHICS
| Процедура | Содержание | Описание |
| Descriptive Methods Analysis (описательные истоды анализа) | 1. Horizontal and Vertical Time Sequence Plot (горизонтальный и вертикальный график временной последовательности) 2. Autocorrelations (автокорреляция) 3. Periodogram and Periodogram Table (периодограммма: табличные значения и график) 4. Tests for Randomness (критерии случайности) 5. Crosscorrelations (кросскорреляция) | Процедура позволяет установить структуру временных рядов с использованием разнообразных критериев |
| Smoothing (сглаживание) | 1. Simple Moving Average (простая скользящая средняя) 2. Spencer/s 15-term/21-term MA (скользящие средние Спенсера по 15 и 21 точкам) 3. Henderson/s Weighted MA (взвешенная скользящая средняя Хендерсона) 4. EWMA (взвешенная скользящая средняя) 5. Resistant Nonlinear Smoothing (устойчивое нелинейное сглаживание) | Процедура осуществляет различные виды сглаживания |
| Seasonal Decomposition (сезонное разложение) | 1. Multiplicative and Additive Seasonal decomposition method (сезонное разложение по мультипликативной или аддитивной модели) 2. Seasons Indices (сезонные индексы) | Процедура проводит сезонное разложение временного ряда |
| Forecasting (прогнозирование) | 1. Random Walk (случайная выборка) 2. Mean (средняя) 3. Trend/s models (трендовые модели) 4. Exponential Smoothing (экспоненциальное сглаживание) 5. ARIMA Model (объединенная модель авторегрессии и скользящего среднего) | Процендура осуществляет прогнозы по различным моделям |

Рисунок 6 – Входящая панель процедуры сглаживания
Система выведет в рабочей области сводку простого пятиточного сглаживания, установленного по умолчанию. В табличных опциях устанавливаем флажок в поле Date Table (таблица данных), а в графических – Time Sequence Plot (график временной последовательности) (рис. 7, 8, 9, 10). Получим отчет (рис. 11).

Рис. 7
Рис. 8

Рис. 9

Рис. 10
Щелкнем правой кнопкой мыши на второй табличной панели – появится всплывающее меню, в котором выберем пункт Pane Options (опции панели). Система предоставит возможность изменить метод сглаживания. Установим переключатель в поле EWMA (рис. 11). Система рассчитает значения и построит график для взвешенного экспоненциального сглаживания с параметром 0,1.

Рис. 11 – Сглаживание уровней рядов динамики методом временной последовательности
Проведем аналогичные расчеты с помощью устойчивого нелинейного сглаживания.
Анализ графиков позволяет сделать вывод, что изменение темпов прироста выработки лучше всего аппроксимирует нелинейное устойчивое сглаживание. Кривые простого скользящего и взвешенного экспоненциального сглаживания менее информативны.

Рис. 12 – Панель установки опций сглаживания
Определив общие закономерности изменения выработки, можно приступить к подбору модели и расчету прогнозных значений моделируемого показателя. С этой целью воспользуемся процедурой Forecasting.
Свернем в пинктограмму окно анализа с результатами сглаживания и выберем указанную процедуру. Заполним верхнюю панель, введя имя переменной и количество лет прогноза, равное пяти (рис. 3). С целью проверки адекватности модели используем три последних наблюдения. Поэтому в поле Withhold for Validation (число точек для проверки правильности модели) введем цифру три.
Система поместит в рабочую область сводку прогноза по модели случайной выборки.
Учитывая, что STATGRAPHICS может сравнивать одновременно пять типов моделей, оптимизируя их параметры, выберем для анализа линейную модель (Liner trend), параболу (Quadratic trend), линейное экспоненциальное сглаживание Брауна (Brown/s linear exp. Smoothing), линейное экспоненциальное сглаживание Хольта (Holt/s linear exp. Smoothing), квадратическое экспоненциальное сглаживание Брауна (Brown/s quadratic exp. Smoothing). Напомним, что в STATGRAPHICS реализовано три типа сглаживания Брауна. Простое сглаживание основано на предположении стационарности изучаемого процесса, линейное предполагает линейный тренд в данных. Квадратическое сглаживание базируется на том, что моделируемый показатель может быть основан на том, что моделируемый показатель может быть описан полиномом второго порядка, т.е. параболой.
Указанные модели выбираются с помощью панели Model Specification Options (опции спецификации модели) (рис. 4). В области Model щелкнем на пункт А, а в области Type установим флажок Linear trend . Затем выберем пункт В и установим флажок Quadratic trend. Для модели С выберем Brown / s linear exp . Smoothing; для моделей D и E установим флажки на полях Holt / s linear exp . Smoothing и Brown / s quadratic exp . Smoothing. Остальные поля оставим со значениями по умолчанию, в т.ч. с флажком Optimize , активным для всех экспоненциальных моделей. Щелкаем ОК с установленным для модели С переключателем. Это означает, что все расчеты система выполнит для этой модели (рис. 13).

Рис. 13 – Анализ линейной модели Брауна
Результаты сравнительного анализа можно вывести, установив флажок Model Comparisons (сравнение моделей) табличных опций.
Получим листинг сравнения моделей (рис. 13). Кратко опишем его. В верхней части листинга приводится информация о данных и уравнениях или коэффициентах построенных моделей.
Наибольший интерес представляют таблицы со статиками прогнозирования, позволяющими оценить адекватность полученных зависимостей. К таким характеристикам относится средняя арифметическая ошибка (МЕ), описывающая отклонения фактических значений от выровненных. Чем ближе она к нулю, тем точнее осуществлена аппроксимация. Средняя квадратическая ошибка (MSE) и средняя абсолютная ошибка (МАЕ) используются для сравнения разных процедур прогнозирования.
Среднепроцентная ошибка (МРЕ) и среднеабсолютная процентная ошибка (МАРЕ) рассчитываются по остаткам одношагового выравнивания, которые делятся на фактическое значение выработки.
Листинг содержит также стандартную ошибку остатков (RMSE) и пять тестов RUNS, RUNM, AUTO, MEAN, VAR:
RUNS – тест на чрезмерное количество пиков и впадин (Test for excessive runs up and down) – рассчитывает число повышений или падений в последовательности анализируемых данных. Тест чувствителен к долгосрочным циклам;
RUNM – тест на чрезмерное количество отклонений от медианы (Test for excessive runs above and below median) – рассчитывает число наблюдений, значение которых выше или ниже медианы, значение которых выше или ниже медианы, и игнорируют значения, которые являются равными медиане. Тест чувствителен к наличию тренда в данных;
AUTO – тест на чрезмерную автокорреляцию (Box-Pierce test for excessive autocorrelation) – рассчитывает коэффициент сериальной корреляции Бокса-Пирса;
MEAN – тест на существенность разности средних (test for difference in mean 1st half to 2nd half) – служит для определения тенденции среднего значения;
VAR – тест на существенность разности дисперсий (test for difference in variance 1st half to 2nd half) – позволяет установить тенденцию вариабельности.
Модель прогнозирования будет адекватной, если все тесты будут иметь значение OK. Т.о., тесты остатков несущественны. Знак звездочки означает, что тест статистически существенен. Количество звездочек определяет уровень существенности критерия. Три звездочки означают, что тест значим с вероятностью, превышающей 99%.
Данные листинга, приведенного на рисунке 14, показывают, что линейная экспоненциальная модель Брауна наиболее удачно аппроксимирует фактические данные. Поэтому для расчетов используется эта модель. Текстовые и графические результаты прогнозирования можно вывести на экран, установив, например, флажки на полях Forecast Table (таблица прогнозов) табличных опций и Time Sequence Plot (график временной последовательности).

Рис. 14 – Сравнительный анализ моделей
На рисунке 15 показаны фактические и прогнозные значения темпов прироста выработки, полученные по линейной экспоненциальной модели Брауна (a=0,2145). Рассчитаем прогнозы по другим моделям и результаты сведем в таблицу 3.
Сравнивая различные варианты прогнозов на 5 лет, следует отметить неоднозначность полученных результатов (таблица 7).

Рис. 15 – Прогноз по линейной экспоненциальной модели Брауна
Таблица 7 – Прогноз темпов прироста производительности труда по различным моделям и методам
| Тип модели | Порядковый номер прогноза | ||||
| 28 | 29 | 30 | 31 | 32 | |
| 7,86123-0,112565*t | 4,71 | 4,6 | 4,48 | 4,37 | 4,25 |
| 9.67752-0.531709*t+0.016766*t2 | 7,93 | 8,36 | 8,81 | 9,31 | 9,83 |
| Brown/s linear wish a=0,2159 | 4,8 | 4,68 | 4,56 | 4,45 | 4,33 |
| Holt/s linear wish a=0,3144, b=0,076 | 4,57 | 4,44 | 4,32 | 4,19 | 4,07 |
| Brown/s quadratic wish a=0,1652 | 4,69 | 4,53 | 4,35 | 4,17 | 3,99 |
В качестве пессимистического варианта прогноза можно рассматривать результаты по квадратической экспоненциальной модели. При этом надо иметь в виду, что остатки у этой модели по тесту MEAN незначительно существенны.
Наиболее вероятен прогноз по линейной модели Брауна. Темп прироста выработки снизится с 4,8% до 4,33%.
|
из
5.00
|
Обсуждение в статье: Тема 3. Адаптивные методы прогнозирования |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы