 |
Главная |


Применение экстраполяции для оценки погрешности
|
из
5.00
|
Для тестовых примеров, имеющих аналитическое решение можно найти разность между приближенным и точным результатом. Распространение этой оценки на другие примеры очень ненадежно. Выход может быть найден, если вместо точного использовать приближенное, но более точное по сравнению с проверяемым значение. Однако при этом возникают два вопроса: как получить это более точное значение и как проверить, что оно действительно точнее исходного.
Более точное значение можно вычислить, пользуясь тем же способом, что и проверяемое. Но это приводит к дополнительным требованиям к ресурсам, которые могут оказаться невыполнимыми. Есть и другой способ: использовать более грубые результаты (с меньшим числом узлов и временем счета). Если погрешность метода подчиняется некоторому закону, то, зная этот закон (в виде характера зависимости, например, степенной, экспоненциальный и т.п.), можно по нескольким результатам провести идентификацию и приближенно предсказать значение, соответствующее бесконечному числу узлов.
Ответить на второй вопрос можно с помощью повторной экстраполяции, т.е. экстраполяцией экстраполированных результатов, полученных для разных наборов исходных данных. В этом случае получается оценка погрешности экстраполированных результатов (или размытость оценки погрешности). Если эта оценка удовлетворяет требованиям: в три и более раз меньше оценки погрешности исходных данных (относительная размытость меньше 1/3 [9]), то цель достигнута. Если нет, то данный способ оценки в конкретном случае следует признать ненадежным. Подробнее о критерии надежности сказано ниже.
Кроме того, при хороших оценках результаты экстраполяции можно использовать вместо вычисленных данных, как более точные. При этом необходима дополнительная экстраполяция, чтобы убедиться в надежности полученных таким способом результатов. В некоторых случаях путем повторной экстраполяции можно получить результаты, на многие порядки более точные, чем рассчитанные непосредственно с помощью численного метода, и чего невозможно было бы добиться прямым расчетом в связи с огромными затратами времени, превышающими разумные пределы.
Численная фильтрация
При экстраполяции требуется априорное знание характера зависимости результата расчетов от числа узлов (или математической модели погрешности), например
 , (26)
, (26)
где  – точное значение;
– точное значение;  – приближенный результат, полученный при числе узловых точек, равном n;
– приближенный результат, полученный при числе узловых точек, равном n; 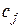 – коэффициенты, которые предполагаются не зависящими от n;
– коэффициенты, которые предполагаются не зависящими от n;  – величина, полагаемая малой по сравнению с
– величина, полагаемая малой по сравнению с  при тех значениях n, которые использовались в данных конкретных расчетах, k1,…, kL – произвольные действительные числа (предполагается, что k1<k2<…< <kL).
при тех значениях n, которые использовались в данных конкретных расчетах, k1,…, kL – произвольные действительные числа (предполагается, что k1<k2<…< <kL).
В математическом анализе обычно оценивается только первый член, поскольку остальные являются асимптотически (при n®¥) бесконечно малыми более высокого порядка. Однако для конечных n остальные слагаемые могут вносить существенный вклад и должны приниматься во внимание.
Если решение задачи представляет собой функцию с несколькими непрерывными производными, то можно допустить возможность его разложения по формуле Тейлора, тогда  – это часть ряда натуральных чисел. Тогда к задаче нахождения предельного при
– это часть ряда натуральных чисел. Тогда к задаче нахождения предельного при 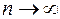 значения z можно подойти как к задаче интерполяции зависимости
значения z можно подойти как к задаче интерполяции зависимости 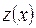 от параметра
от параметра 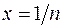 алгебраическим многочленом с последующей экстраполяцией до
алгебраическим многочленом с последующей экстраполяцией до 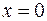 . Есть и другой подход, приводящий при условии постоянства
. Есть и другой подход, приводящий при условии постоянства 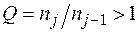 к тому же алгоритму, но не требующий целочисленности . Это решение задачи численной фильтрации, т.е. последовательное устранение степенных слагаемых суммы (26) при сохранении значения константы z. Рассмотрим два значения
к тому же алгоритму, но не требующий целочисленности . Это решение задачи численной фильтрации, т.е. последовательное устранение степенных слагаемых суммы (26) при сохранении значения константы z. Рассмотрим два значения 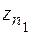 ,
,  , вычисленные при числе узлов, равном
, вычисленные при числе узлов, равном 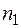 и
и 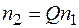 соответственно. Составим линейную комбинацию
соответственно. Составим линейную комбинацию
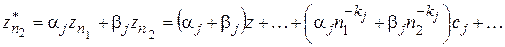
и потребуем, чтобы, суммарный коэффициент при z был равен 1, а при (для определенного j) равен 0. Отсюда получим формулу фильтрации, которая совпадает с экстраполяционной формулой Ричардсона [1]
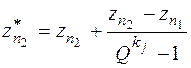 . (27)
. (27)
Проводя последовательно экстраполяцию по всем парам соседних значений, получим отфильтрованную зависимость, не содержащую члена с 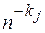
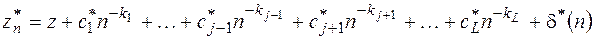 , (28)
, (28)
где 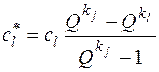 . (29)
. (29)
Заметим, что отфильтрованная последовательность 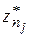 содержит на один член меньше, чем исходная. Если она содержит больше одного члена, то ее также можно отфильтровать, устранив степенную составляющую с
содержит на один член меньше, чем исходная. Если она содержит больше одного члена, то ее также можно отфильтровать, устранив степенную составляющую с  . Операции фильтрации можно повторять последовательно для
. Операции фильтрации можно повторять последовательно для 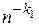 ,…,
,…,  , если исходная последовательность содержит достаточное количество членов. Результаты экстраполяций удобно представлять в виде треугольной матрицы
, если исходная последовательность содержит достаточное количество членов. Результаты экстраполяций удобно представлять в виде треугольной матрицы
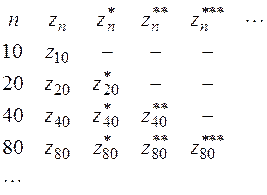 (30)
(30)
Применение повторной экстраполяции при kj=j известно под названием метода Ромберга. При его применении возникает ряд ограничений.
Применение повторной экстраполяции приводит к изменению коэффициентов суммы (26). При  увеличение абсолютной величины коэффициентов может оказаться весьма существенным. Это ограничивает число возможных экстраполяций.
увеличение абсолютной величины коэффициентов может оказаться весьма существенным. Это ограничивает число возможных экстраполяций.
Величина 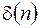 в (26) может оказаться суммой регулярной составляющей, имеющей вид
в (26) может оказаться суммой регулярной составляющей, имеющей вид 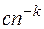 , и нерегулярной составляющей
, и нерегулярной составляющей 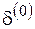 , обусловленной погрешностью исходных данных, которая, например, связана с ограниченной разрядностью чисел в машинном представлении. Тогда исходная нерегулярная часть погрешности, содержащаяся в вычисленных значениях
, обусловленной погрешностью исходных данных, которая, например, связана с ограниченной разрядностью чисел в машинном представлении. Тогда исходная нерегулярная часть погрешности, содержащаяся в вычисленных значениях  , при каждой экстраполяции умножается на коэффициент
, при каждой экстраполяции умножается на коэффициент
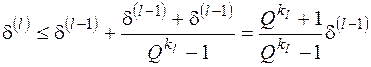 . (31)
. (31)
Для метода Ромберга, применяемого к последовательности (26) при  , произведение таких множителей ограничено числом, приблизительно равным 8 (получено численно), т.е. метод Ромберга является устойчивым к погрешности исходных данных, но сам уровень нерегулярной погрешности может ограничить число возможных экстраполяций.
, произведение таких множителей ограничено числом, приблизительно равным 8 (получено численно), т.е. метод Ромберга является устойчивым к погрешности исходных данных, но сам уровень нерегулярной погрешности может ограничить число возможных экстраполяций.
Метод Эйткена
При оценке погрешности частичных сумм значение k в (2.4) может быть неизвестно. В этом случае можно использовать следующую модификацию правила Ричардсона. Вычислим три значения z1, z2, z3 при трех номерах последовательности: n, nQ, nQ2 и составим систему трех уравнений [1, 9]
 (32)
(32)
Найдем разности
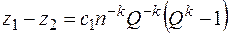 ,
,
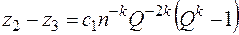 ,
,
и, разделив одну на другую, определим Qk
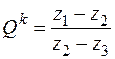 . (33)
. (33)
Теперь можно найти z
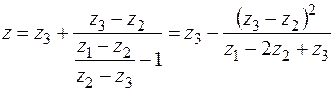 . (34)
. (34)
Как и в рассмотренных ранее случаях, мы нашли экстраполированное (уточненное) значение z=z*, а вместе с ним и оценку погрешности zi-z*.
Этот способ экстраполяции при неизвестном порядке точности принято называть алгоритмом Эйткена или d2-алгоритмом, который в более общем случае применяется для экстраполяции векторных последовательностей
 .
.
В последнем выражении zi – векторы, а скобками обозначается скалярное произведение.
|
из
5.00
|
Обсуждение в статье: Применение экстраполяции для оценки погрешности |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы