 |
Главная |


ОСНОВЫ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ РЕЗУЛЬТАТОВ
|
из
5.00
|
При обработке результатов массового тестирования широко используется латентно–структурный анализ, представляющий собой современный методологический подход и использующий совокупность статистических методов, в основе которых лежит предположение о наличии функциональной связи между латентными параметрами испытуемых и наблюдаемыми результатами выполнения тестов. Такой подход нацелен на переход путем специальных преобразований наблюдаемых результатов выполнения теста к оценкам латентных параметров испытуемых, выражаемых тестовыми баллами, и уровня трудности заданий в ло–гитах. При организации современного контрольно–оценочного процесса решается задача установления пределов измеряемых характеристик, в рамках которых качество обучения соответствует требованиям. Вообще говоря, при решении этой задачи существуют два «врага» оценки качества: отклонения от плановых спецификаций (или нормы) и слишком большой разброс реальных характеристик относительно нормативных показателей.
Для обсуждения результатов массового тестирования при процедурах статистического анализа данных и для понимания «численной природы» педагогических измерений необходим краткий обзор элементарных понятий статистики. Что такое переменные, какие из них являются зависимыми и независимыми, какие существуют зависимости между переменными, что такое статистическая значимость и объем выборки? Каково значение нормального распределения в статистических рассуждениях? Как можно дифференцировать уровни подготовленности разных испытуемых? Эти и многие другие вопросы необходимы для работы с образовательной статистикой и для правильной интерпретации результатов тестового контроля, основанного на количественном определении переменных и установлении зависимостей между ними.
Переменные – это то, что можно измерять, контролировать или изменять в исследованиях. Их подразделяют на зависимые и независимые. Независимыми называются такие переменные, которые варьируются самим исследователем, тогда как зависимые переменные – это переменные, которые измеряются или регистрируются. Зависимость проявляется в ответной реакции исследуемого объекта на посланное на него воздействие. Экспериментатор, манипулируя независимыми переменными, приписывает объекты к экспериментальным группам, основываясь на некоторых их априорных свойствах. Например, пол респондентов является независимой переменной.
Анализ зависимых данных приводит к вычислению корреляций (зависимостей) между переменными и выявлению причинно–следственной связи между ними [36]. Например, если обнаружено, что всякий раз, когда изменяется переменная A, изменяется и переменная B, то можно сделать вывод о том, что переменная A оказывает влияние на переменную B, между переменными А и В имеется причинная зависимость, а следствием изменения величины В является изменение величины А.
Независимо от типа две или более переменные связаны (зависимы) между собой, если наблюдаемые значения этих переменных распределены согласованным образом. Другими словами, переменные зависимы, если их значения согласованы друг с другом в имеющихся наблюдениях. Например, рост связан с весом, обычно высокие индивиды тяжелее низких; IQ (коэффициент интеллекта) связан с количеством ошибок в тесте, а люди с высоким значением IQ делают меньше ошибок и т.д.
Конечная цель всякого исследования или научного анализа состоит в нахождении связей (зависимостей) между переменными в терминах их количественных или качественных зависимостей, корреляций. Можно отметить два самых простых свойства зависимости между переменными: величину зависимости и надежность зависимости.
Величину зависимости понять и измерить легче, чем надежность. Надежность – менее наглядное понятие, однако оно чрезвычайно важно, так как связано с репрезентативностью выборки, на основе которой строятся выводы. Другими словами, надежность говорит нам о том, насколько вероятно, что зависимость, подобная найденной, будет вновь обнаружена на данных другой выборки, извлеченной из той же самой генеральной выборки (всей совокупности исследуемых объектов). Надежность найденных зависимостей между переменными конкретной выборки можно количественно оценить и представить с помощью стандартной статистической меры (называемой p-уровнем или статистическим уровнем значимости).
Статистическая значимость результата представляет собой меру уверенности в его истинности (в смысле репрезентативности выборки), p-уровень (термин введен K.A. Brownlee, 1960) – это показатель, находящийся в убывающей зависимости от надежности результата [233]. Более высокий p – уровень соответствует более низкой зависимости между переменными, найденной в выборке. Именно p – уровень представляет собой вероятность ошибки, связанной с распространением наблюдаемого результата на генеральную выборку. Например, p –уровень, равный 0,05 (т.е. 1/20), показывает, что имеется 5% вероятности того, что найденная в выборке связь между переменными является случайной. Иными словами, если данная зависимость в генеральной выборке отсутствует, то примерно в одном из двадцати повторений эксперимента можно ожидать появления такой же или более сильной зависимости между переменными. Если между переменными генеральной выборки существует такая зависимость, то вероятность повторения результатов исследования, показывающих наличие этой зависимости, называется статистической мощностью плана. В большинстве исследований p – уровень, равный 0,05 (или 5%), рассматривается как приемлемая граница ошибки измерения.
Выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений множества данных. Результаты, значимые на уровне p = 0,01, обычно рассматриваются как статистически значимые, а результаты с уровнем p = 0,005 или p = 0,001 – как высокозначимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследований.
Понятно, что чем больше видов анализов проводится с совокупностью данных, тем большее число значимых (на выбранном уровне) результатов будет обнаружено чисто случайно. Например, если имеет место корреляция между 10 переменными из 45, то можно ожидать, что примерно два коэффициента корреляции (один на каждые 20) чисто случайно окажутся значимыми на уровне p= 0,05. Тем не менее многие статистические методы (особенно простые методы разведочного анализа данных) не предлагают какого–либо способа решения данной проблемы. Поэтому исследователь должен с осторожностью оценивать надежность неожиданных результатов: чем больше величина зависимости (связи) между переменными в выборке обычного объема, тем более она надежна.
Если предполагать отсутствие зависимости между соответствующими переменными в генеральной выборке, то наиболее вероятно ожидать, что в исследуемой выборке связь между этими переменными также будет отсутствовать. Таким образом, чем более сильная зависимость обнаружена в исследуемой выборке, тем менее вероятно, что этой зависимости нет в генеральной, из которой она извлечена. Таким образом, величина зависимости и ее значимость тесно связаны между собой. Однако указанная связь между зависимостью и значимостью имеет место только для данного объема выборки, поскольку при различных объемах выборки одна и та же зависимость может оказаться как высокозначимой, так и не значимой вовсе.
Если наблюдений мало, то, соответственно, имеется мало возможных комбинаций значений переменных, и, таким образом, вероятность случайного обнаружения комбинации значений, показьгаающигх сильную зависимость, относительно велика. Рассмотрим следующий пример. Если исследуется зависимость двух переменных и имеется только 4 субъекта в выборке, то вероятность того, что чисто случайно будет найдена 100%-ная зависимость между двумя переменными, равна 1/8. Если рассмотреть вероятность подобного совпадения для 100 субъектов, то легко видеть, что эта вероятность равна практически нулю. Очевидно, чем меньше объем выборки в каждом эксперименте, тем более вероятно появление ложных результатов, когда такая зависимость на самом деле отсутствует.
Если зависимость между переменными почти отсутствует, объем выборки, необходимый для значимого обнаружения зависимости, предполагается бесконечным. Статистическая значимость представляет вероятность того, что подобный результат получен при проверке всей генеральной, бесконечно большой выборки.
Статистиками разработано много различных мер взаимосвязи между переменными. Выбор определенной меры в конкретном исследовании зависит от числа переменных, используемых шкал измерения, природы зависимости и т.д. Большинство таких мер между переменными подчиняется общему принципу статистической значимости: оценивание наблюдаемой зависимости с помощью сравнения ее с максимально мыслимой зависимостью – критерием. Значение статистических критериев состоит в оценивании зависимости между переменными. Однако, чтобы определить уровень статистической значимости, нужна функция, которая представляла бы зависимость между «величиной» и «значимостью» зависимости между переменными для каждого объема выборки. Большинство функций имеет характер нормального распределения (рис. 40), представляющего собой одну из эмпирически проверенных истин общей природы статистически значимого числа объектов и один из фундаментальных законов природы. Форма нормального распределения – характерная колоколообразная кривая – определяется двумя параметрами: средним и стандартным отклонением. Более точную информацию о форме распределения можно получить с помощью критериев нормальности. Однако ни один из критериев не может заменить визуальную проверку нормальности с помощью гистограммы (частоты попаданий значений переменной в отдельные интервалы).
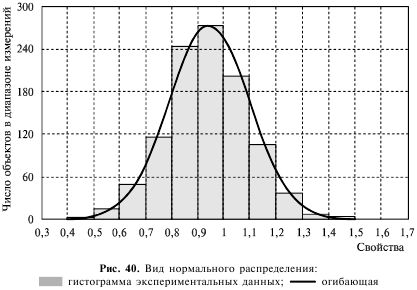
Гистограмма позволяет качественно и наглядно оценить различные характеристики распределения, на нее может накладываться кривая нормального распределения. Например, если асимметрия существенно отличается от 0, то распределение несимметрично, в то время как нормальное распределение абсолютно симметрично, а его асимметрия равна 0. Асимметрия распределения с длинным правым хвостом положительна. Если распределение имеет длинный левый хвост, то его асимметрия отрицательна. На гистограмме можно увидеть, к примеру, что распределение бимодально (имеет 2 пика), это может быть вызвано тем, что выборка неоднородна, возможно, извлечена из двух разных по свойствам, каждая из которых более или менее нормальна. В таких ситуациях, чтобы понять природу наблюдаемых переменных, можно попытаться найти качественный способ разделения выборки на две части.
При возрастании объема выборки форма выборочного распределения приближается к нормальной, даже если распределение исследуемых переменных не является нормальным. Центральная предельная теорема гласит, что при размере выборки n > 30 выборочное распределение уже почти нормально.
Важным способом описания переменной является форма ее распределения, которая показывает, с какой частотой значения переменной попадают в определенные интервалы. Эти интервалы, называемые интервалами группировки, выбираются исследователем, которого интересует, насколько точно распределение можно аппроксимировать нормальным. Характерное свойство нормального распределения состоит в том, что 68% всех его наблюдений лежат в диапазоне ±1 стандартного отклонения от среднего, а диапазон ±2 стандартных отклонения содержит 95% значений. Другими словами, при нормальном распределении стандартизованные наблюдения меньше–2 или больше +2 имеют относительную частоту менее 5%.
Для характеристики меры изменчивости распределения используют показатель вариации или стандартное отклонение, представляющее собой корень квадратный из дисперсии:
Иногда используют стандартизованное наблюдение, которое означает, что из исходного значения вычтено среднее и результат поделен на стандартное отклонение.
Исследователю часто бывают необходимы такие статистики, которые позволяют сделать вывод относительно свойств генеральной выборки в целом. Для этого используются описательные статистики, оперирующие такими понятиями, как истинное среднее и доверительный интервал. Среднее генеральной выборки является информативной мерой положения наблюдаемой переменной в доверительном интервале. Доверительный интервал представляет собой интервал, в котором с заранее выбранной вероятностью, близкой к единице (меньшей единицы на величину выбранного уровня значимости критерия), можно утверждать, что с данным уровнем доверия находится истинное значение оцениваемого параметра. Ширина доверительного интервала зависит от объема или размера выборки, а также от разброса (изменчивости) данных. Увеличение размера выборки делает оценку среднего более надежной.
Например, если среднее выборки равно 23, а нижняя и верхняя границы доверительного интервала с уровнем p = 95 равны 19 и 27 соответственно, то можно заключить, что с вероятностью
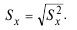
95% интервал с границами 19 и 27 накрывает среднее генеральной выборки. Если установить больший уровень доверия, то интервал станет шире, возрастет вероятность, с которой он накрывает неизвестное среднее генеральной выборки, и наоборот. Известно, что чем неопределеннее прогноз погоды (т.е. шире доверительный интервал), тем вероятнее, что он будет правильным. Увеличение разброса наблюдаемых значений уменьшает надежность оценки. Вычисление доверительных интервалов основывается на предположении нормальности наблюдаемых величин. Если это предположение не выполнено, то оценка может оказаться плохой, особенно для малых выборок. При увеличении объема выборки, скажем, до 100 или более качество оценки улучшается и без предположения о нормальности выборки [237].
Во многих областях исследований точное измерение переменных само по себе представляет сложную задачу, например в психологии точное измерение личностных характеристик или отношений к чему–либо. В целом, очевидно, во всех социальных дисциплинах ненадежные измерения будут препятствовать попытке правильно предсказать результат. В прикладных исследованиях, когда наблюдения над переменными затруднены, важна точность измерений.
Надежность и точность позволяют построить шкалы измерений или улучшить используемые с помощью классической теории тестирования. В этом контексте надежность понимается непосредственно: измерение является надежным, если его основную часть по отношению к погрешности составляет истинное значение. Оценивание надежности шкалы основано на корреляциях между индивидуальными позициями или измерениями, составляющими шкалу, и дисперсиями этих позиций. Показатель разброса некоторого множества результатов измерений вокруг среднего арифметического называется дисперсией, величина которой определяется по формуле:
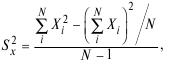
где X – число правильно выполненных заданий N испытуемьши.
Каждое измерение (ответ на вопрос) включает в себя как истинное значение, так и частично не контролируемую, случайную погрешность. Для эффективного функционирования контрольно–оценочной системы необходимы высокая надежность и валид–ность педагогических измерений. Под надежностью понимают точность измерений, а также устойчивость результатов к действию случайных факторов. Тест считается надежным, если он обеспечивает высокую точность измерений, а также дает при повторном выполнении на той же выборке близкие результаты при условии того, что подготовка испытуемых не изменилась за время до повторного выполнения теста.
На протяжении десятилетий вопросы надежности исследовались многочисленными теоретиками и практиками в области педагогических измерений. Особо следует отметить работу R.L. Linn [241], в которой рассматриваются не только процедуры оценки надежности, но и методологические вопросы обоснования качества тестовых измерений. Его подход оправдан тем, что в требовании проверки теста на надежность реализуется важная идея методологического характера, связанная с неизбежностью ошибок измерения, порождаемых группой случайных факторов. В самой общей трактовке надежность тестов можно рассматривать как характеристику существующих различий между результатами педагогических измерений и истинными баллами испытуемых (подготовленностью) в той мере, в какой эти различия порождаются случайными ошибками измерения. В теории педагогических измерений ошибка трактуется как статистическая величина, отражающая степень отклонения наблюдаемого балла от истинного балла ученика или студента.
Существование ошибки измерения закладывается и привносится в теорию педагогических измерений основными аксиомами классической теории тестов. К числу наиболее важных аксиом, закладывающих научный фундамент обоснования теории надежности тестов, можно отнести равенство:
Xik= Ti+ Eik,
где Xk – наблюдаемый результат i – го испытуемого выборки по тестовой форме k ; Ti – его истинный балл; Eik – суммарная ошибка измерения при оценке i – го испытуемого с помощью k – й формы теста.
Использование аксиом и предположения о нормальном характере распределения статистик по тесту приводит к фундаментальному соотношению классической теории тестов, связывающему дисперсию наблюдаемых баллов Sx2, дисперсию истинных баллов Sт2 и дисперсию ошибок измерения Sе2 согласно которому Sx2= Sт2+ Sе2,
где Sx2 , в свою очередь, состоит из двух слагаемых, одно из которых – наиболее важная общая часть дисперсии, составляющая основу корреляционных и дисперсионных методов исследования качества теста, а другое – специфическая часть. Принято счи тать, что общая часть определяется различиями в подготовке испытуемых, в то время как специфическая часть дисперсии порождается различиями в содержании заданий теста. Разделив на Sx2 почленно равенство, получим
Sx2/ Sx2 = Sт2 / Sx2 + Sт2/ Sx2, или Sт2 / Sx2 = 1 – Sе2/ Sx2
где следует понимать как среднее арифметическое дисперсий ошибок для различных испытуемых из генеральной совокупности, поскольку ошибка при оценке истинного балла будет меняться для различных испытуемых группы.
Естественно предположить, что чем ближе Sx2 к Sт2 , тем выше корреляция между множеством наблюдаемых баллов X и множеством истинных баллов T и, следовательно, тем надежнее тест. Поэтому отношение Sт2/ Sx2 = rн обычно трактуют как характеристику надежности теста.
Одним из способов вычисления надежности суммарной шкалы является разбиение суммарной шкалы случайным образом на две половины. Если суммарная шкала совершенно надежна, то следует ожидать, что обе части абсолютно коррелированы (т.е. r = 1,0). Если суммарная шкала не является абсолютно надежной, то коэффициент корреляции будет меньше 1. Можно оценить надежность суммарной шкалы посредством коэффициента Спирме–на—Брауна:
rсб = 2rxy /(1 + rxy),
где rсб – коэффициент надежности; rxy – корреляция между двумя половинами шкалы х иу.
Если используемая шкала коррелирует с измеряемым показателем, то можно говорить о достоверности шкалы, т.е. о том, что она действительно измеряет то, для чего создана, а не что–нибудь другое. Построение достоверной выборки – это продолжительный процесс, при котором исследователь изменяет шкалу в соответствии с различными внешними критериями, теоретически связанными с той концепцией, для подтверждения которой и строится шкала. Фактически достоверность шкалы всегда ограничивается ее надежностью, поэтому важной составляющей анализа данных является корреляция, представляющая собой меру взаимозависимости переменных. При заданной надежности двух связанных между собой измерений (т.е. шкалы и исследуемого показателя) можно оценить корреляцию между истинными значениями разных измерений. Это изменение корреляции обусловлено либо значениями, задаваемыми пользователем, либо реальными исходными данными.
Наиболее известна корреляция Пирсона. При вычислении корреляции Пирсона предполагается, что переменные измерены, как минимум, в интервальной шкале. Некоторые другие коэффициенты корреляции могут быть вычислены для менее информативных шкал (порядковых). Коэффициенты корреляции, как правило, изменяются в пределах от–1,00 до +1,00. Значение–1,00 показ ы вает, что переменные имеют строгую отрицательную корреляцию. Значение +1,00 свидетельствует, что переменные имеют строгую положительную корреляцию, а значение 0,00 соответствует отсутствию корреляции.
Наиболее часто используемый коэффициент корреляции Пирсона r называется также линейной корреляцией и измеряет степень линейных связей между переменными. Корреляция Пирсона (далее – корреляция) определяет степень, с которой значения двух переменных пропорциональны друг другу, значение коэффициента корреляции не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же, независимо от того, проводились измерения в дюймах и фунтах или в сантиметрах и килограммах. Корреляция высокая, если на графике зависимость можно представить прямой линией с положительным или отрицательным углом наклона. Такая прямая называется прямой регрессии, или прямой, построенной методом наименьших квадратов. Последний термин связан с тем, что сумма квадратов расстояний (вычисленных по оси Y) от наблюдаемых точек до прямой является минимальной. Заметим, что использование квадратов расстояний приводит к тому, что оценки параметров прямой сильно реагируют на выбросы.
Коэффициент корреляции Пирсона (r) представляет собой меру линейной зависимости двух переменных x и y :
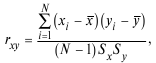
где Sx , Sy – стандартные отклонения переменных.
Если возвести его в квадрат, то полученное значение коэффициента детерминации r2представляет долю вариации, общую для двух переменных, или степень зависимости (связанности этих переменных). Чтобы оценить зависимость между переменными, нужно знать как величину корреляции, так и ее значимость. Уровень значимости, вычисленный для каждой корреляции, зависит от объема выборок и представляет собой главный источник информации о надежности корреляции. Критерий значимости основывается на предположении о том, что распределение отклонений наблюдений от регрессионной прямой для зависимой переменной Y является нормальным с постоянной дисперсией для всех значений независимой переменной X. По определению, выбросы являются нетипичными, резко выделяющимися наблюдениями. Так как при построении прямой регрессии используется сумма квадратов расстояний наблюдаемых точек до прямой, то выбросы могут существенно повлиять на наклон прямой и, следовательно, на значение коэффициента корреляции. Поэтому единичный выброс (значение которого возводится в квадрат) способен существенно изменить наклон прямой и, следовательно, значение корреляции. Если размер выборки относительно мал, то добавление или исключение некоторых данных способно оказать существенное влияние на прямую регресии и коэффициент корреляции. Выбросы могут не только искусственно увеличить значение коэффициента корреляции, но и реально уменьшить существующую корреляцию. Считается, что выбросы представляют собой случайную ошибку, которую следует контролировать. Чтобы не быть введенными в заблуждение полученными значениями, необходимо проверить на диаграмме рассеяния каждый важный случай значимой корреляции.
Другим возможным источником трудностей, связанным с линейной корреляцией Пирсонаr, является форма зависимости. Корреляция Пирсона r хорошо подходит для описания линейной зависимости. Отклонения от линейности увеличивают общую сумму квадратов расстояний от регрессионной прямой, даже если она представляет истинные и очень тесные связи между переменными. Если кривая монотонна (монотонно возрастает или, напротив, монотонно убывает), то можно преобразовать одну или обе переменные, чтобы сделать зависимость линейной, а затем уже вынислить корреляцию между преобразованными величинами.
Иногда исследователи применяют численные методы удаления выбросов. К сожалению, в общем случае определение выбросов субъективно, и решение должно приниматься индивидуально в каждом эксперименте с учетом его особенностей или сложившейся практики в данной области. Во многих случаях первый шаг анализа состоит в вычислении корреляционной матрицы всех переменных и проверке значимых (ожидаемых и неожиданных) корреляций. После того как это сделано, следует понять общую природу обнаруженной статистической значимости и понять, почему одни коэффициенты корреляции значимы, а другие нет. Однако следует иметь в виду, если используется несколько критериев, значимые результаты могут появляться часто, и это будет происходить чисто случайным образом. Например, коэффициент, значимый на уровне 0,05, будет встречаться чисто случайно один раз в каждом из 20 подвергнутых исследованию коэффициентов. Поэтому следует подходить с осторожностью ко всем непредсказанным или заранее не запланированным результатам и погштаться соотнести их с другими (надежными) результатами. В конечном счете самый убедительный способ проверки состоит в проведении повторного экспериментального исследования. Такое положение является общим для всех методов анализа, использующих множественные сравнения и статистическую значимость.
Следует иметь в виду, что коэффициенты корреляции не являются аддитивными: усредненный коэффициент корреляции, вычисленный по нескольким выборкам, не совпадает со средней корреляцией во всех этих выборках. Причина в том, что коэффициент корреляции не является линейной функцией величины зависимости между переменными. Коэффициенты корреляции не могут быть просто усреднены. Для получения среднего коэффициента корреляции следует преобразовать коэффициенты корреляции каждой выборки в такую меру зависимости, которая будет аддитивной. Например, до того как усреднить коэффициенты корреляции, их можно возвести в квадрат, получить коэффициенты детерминации, которые уже будут аддитивными. Если необходимо выявить различия средних в нескольких исследуемых группах, то подходящим является однофакторный дисперсионный анализ, дающий различие дисперсий. Дисперсионный анализ – это статистический метод изучения влияния отдельных переменных на изменчивость измеряемой (исследуемой) переменной.
Апостериорные сравнения средних после получения статистически значимого результата в дисперсионном анализе позволяют узнать, какие средние вызвали наблюдаемый эффект. Процедуры апостериорного сравнения специально рассчитаны так, чтобы учитывать более двух выборок. Группировку с дискриминант–ным анализом можно рассматривать как первый шаг к другому типу анализа – дискриминативному, который исследует различия между группами с помощью значений независимой переменной. Именно, в дискриминантном анализе находят такие линейные комбинации зависимых переменных, которые наилучшим образом определяют принадлежность наблюдения к определенному классу, причем число классов задается заранее.
Дискриминантный анализ используется для принятия решения о том, какие переменные различают (дискриминируют) две или более возникающие совокупности (группы). Например, некий исследователь в области образования может захотеть исследовать, какие переменные относят выпускника средней школы к одной из трех категорий: 1) поступающий в колледж; 2) поступающий в профессиональную школу; 3) отказывающийся от дальнейшего образования или профессиональной подготовки. Для этой цели исследователь может собрать данные о различных переменных, связанных с учащимися школы. После выпуска большинство учащихся, естественно, должны попасть в одну из названных категорий. Затем можно использовать дискриминантный анализ для определения того, какие переменные дают наилучшее предсказание выбора учащимися дальнейшего пути. Например, предположим, что имеются две совокупности выпускников средней школы – те, кто выбрал поступление в колледж, и те, кто не собирается это делать. Если средние для двух совокупностей (тех, кто в настоящее время собирается продолжить образование, и тех, кто отказывается) различны, то это позволяет разделить учащихся на тех, кто собирается и кто не собирается поступать в колледж (и эта информация может быть использована членами школьного совета для подходящего руководства соответствующими учащимися).
Дисперсионный анализ, в частности, позволяет выявить, являются ли две или более совокупности значимо отличающимися одна от другой по среднему значению какой–либо конкретной переменной. Для изучения вопроса о том, как можно проверить статистическую значимость отличия в среднем между различными совокупностями, должно быть ясно, что если среднее значение определенной переменной значимо различно для двух совокупностей, то переменная их разделяет.
При применении дискриминантного и дисперсионного анализа обычно имеются несколько переменных, и задача состоит в том, чтобы установить, какие из них вносят существенный вклад в дискриминацию между совокупностями. Если анализируется влияние нескольких переменных, то проводится пошаговый факторный анализ. В пошаговом анализе модель дискриминации (дискриминантных функций) строится по шагам. Точнее, на каждом шаге просматриваются все переменные и находится та из них, которая вносит наибольший вклад в различие между совокупностями. Эта переменная должна быть включена в модель на данном шаге, а далее осуществляется переход к следующему шагу. В общем, получается линейное уравнение типа:
Группа = a + b 1 x 1 + b 2 x 2 + … + b m x m ,
где a – константа, и b1, ..., bm – коэффициенты регрессии. Интерпретация результатов задачи с двумя совокупностями следует логике применения множественной регрессии: переменные с наибольшими регрессионными коэффициентами вносят наибольший вклад в дискриминацию.
Главными целями факторного анализа являются сокращение числа переменных (редукция данных) и определение структуры взаимосвязей между переменными, т.е. классификация переменных. Поэтому факторный анализ используется или как метод сокращения данных, или как метод классификации (Wherry, 1984). Факторный анализ рассматривается как метод редукции данных. Например, измерение роста людей в дюймах и сантиметрах: имеются две переменные. Если исследовать, например, влияние различных пищевых добавок на рост, нужно ли использовать обе переменные? Вероятно, нет, так как рост является одной характеристикой человека, независимо от того, в каких единицах он измеряется. Итак, фактически сократили число переменных и заменили две одной. Если пример с двумя переменными распространить на большее число переменных, то вычисления становятся сложнее, однако основной принцип представления двух или более зависимых переменных одним фактором остается в силе.
Факторный анализ как метод классификации включает как анализ главных компонентов, так и анализ главных факторов. Чтобы проиллюстрировать, каким образом это может быть сделано, производятся действия в обратном порядке, т. е. начинают с некоторой осмысленной структуры, а затем смотрят, как она отражается на результатах. Действительные значения факторов можно оценить для отдельных наблюдений путем выделения главных факторов. На языке факторного анализа доля дисперсии отдельной переменной, принадлежащая общим факторам, называется общностью. Поэтому дополнительной работой, стоящей перед исследователем при применении этой модели, является оценка общностей для каждой переменной, т.е. доли дисперсии, которая является общей для всех пунктов. Доля дисперсии, за которую отвечает каждый пункт, равна тогда суммарной дисперсии, соответствующей всем переменным, минус общность.
Основное различие двух моделей факторного анализа состоит в том, что в анализе главных компонент предполагается, что должна быть использована вся изменчивость переменных, тогда как в анализе главных факторов используется только изменчивость переменной, общая и для других переменных. Анализ главных компонент часто более предпочтителен как метод сокращения данных, в то время как анализ главных факторов лучше применять с целью определения структуры данных.
Для определения того, к какой группе наиболее вероятно может быть отнесен каждый объект, предназначены функции классификации, их выделяется столько же, сколько требуется групп по общим признакам. Каждая функция позволяет для каждого образца и для каждой совокупности вычислить веса классификации по формуле:
Si= ci+ wi1 · x1+wi2 · x2+ ... + wim · xm,
где Si – результат показателя классификации; обозначает соответствующую совокупность, а индексы 1, 2, ..., m обозначают m переменных; ci – константы для i – й совокупности,wij – веса для j – й переменной при вычислении показателя классификации для i – й совокупности; Xj – наблюдаемое значение для соответствующего образца j – й переменной. Можно использовать функции классификации для прямого вычисления показателя классификации для всех значений переменных. Расчет показателей классификации позволяет производить классификацию наблюдений.
На практике исследователю необходимо задать себе вопрос, является ли неодинаковое число наблюдений в различных совокупностях в первоначальной выборке отражением истинного распределения или это только (случайный) результат процедуры выбора. В первом случае используются априорные вероятности пропорционально объемам совокупностей в выборке; во втором – априорные вероятности одинаковы для каждой совокупности. Спецификация различных априорных вероятностей может сильно влиять на точность классификации. Для увеличения точности классификаций используются апостериорные вероятности – это вероятности, вычисленные с использованием знания значений других переменных для образцов из частной совокупности. В последнее время созданы программные пакеты, автоматически вычисляющие апостериорные вероятности для различных видов наблюдений. Общим результатом является матрица классификации.
При повторной итерации апостериорная классификация того, что случилось в прошлом, не очень трудна. Нетрудно получить очень хорошую классификацию тех образцов, по которым была оценена функция классификации. Для получения сведений, насколько хорошо работает процедура классификации на самом деле, следует классифицировать (априорно) различные наблюдения, которые не использовались при оценке функции классификации, гибко использовать условия отбора для включения их в число наблюдений или, напротив, исключения. Матрица классификации может быть вычислена по старым образцам столь же успешно, как и по новым. Но только классификация новых наблюдений позволяет определить качество функции классификации, классификация старых наблюдений позволяет лишь провести успешную диагностику наличия выбросов или области, где функция классификации кажется менее адекватной.
Дискриминантный, дисперсионный и фактор
|
из
5.00
|
Обсуждение в статье: ОСНОВЫ СТАТИСТИЧЕСКОЙ ОБРАБОТКИ РЕЗУЛЬТАТОВ |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы