 |
Главная |


Трендовые модели прогнозирования
|
из
5.00
|
Статистические наблюдения в социально-экономических исследованиях обычно проводятся регулярно через равные отрезки времени и представляются в виде временных рядов xt, где t = 1, 2, ..., п. В качестве инструмента статистического прогнозирования временных рядов служат трендовые регрессионные модели, параметры которых оцениваются по имеющейся статистической базе, а затем основные тенденции (тренды) экстраполируются на заданный интервал времени.
Методология статистического прогнозирования предполагает построение и испытание многих моделей для каждого временного ряда,ихсравнение на основе статистических критериев и отбор наилучшихизних для прогнозирования.
При моделировании сезонных явлений в статистических исследованиях различают два типа колебаний: мультипликативные и аддитивные. В мультипликативном случае размах сезонных колебаний изменяется во времени пропорционально уровню тренда и отражается в статистической модели множителем. При аддитивной сезонности предполагается, что амплитуда сезонных отклонений постоянна и не зависит от уровня тренда, а сами колебания представлены в модели слагаемым.
Основой большинства методов прогнозирования является экстраполяция, связанная с распространением закономерностей, связей и соотношений, действующих в изучаемом периоде, за его пределы, или — в более широком смысле слова — это получение представлений о будущем на основе информации, относящейся к прошлому и настоящему.
Наиболее известны и широко применяются трендовые и адаптивные методы прогнозирования. Среди последних можно выделить такие, как методы авторегрессии, скользящего среднего (Бокса — Дженкинса и адаптивной фильтрации), методы экспоненциального сглаживания (Хольта, Брауна и экспоненциальной средней) и др.
Для оценки качества исследуемой модели прогноза используют несколько статистических критериев.
Наиболее распространенными критериями являются следующие.
Относительная ошибка аппроксимации:

где et = хt -  — ошибка прогноза;
— ошибка прогноза;
хt — фактическое значение показателя;
— прогнозируемое значение.
Данный показатель используется в случае сравнения точности прогнозов по нескольким моделям. При этом считают, что точность модели является высокой, когда 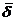 < 10%, хорошей — при = 10—20% и удовлетворительной — при = 20—50%.
< 10%, хорошей — при = 10—20% и удовлетворительной — при = 20—50%.
Средняя квадратическая ошибка:

где k — число оцениваемых коэффициентов уравнения.
Наряду с точечным в практике прогнозирования широко используют интервальный прогноз. При этом доверительный интервал чаще всего задается неравенствами 
где tα — табличное значение, определяемое по t-распределению Стьюдента при уровне значимости α и числе степеней свободы п - k.
В литературе представлено большое число математико-статистических моделей для адекватного описания разнообразных тенденций временных рядов.
Наиболее распространенными видами трендовых моделей, характеризующих монотонное возрастание или убывание исследуемого явления, являются:
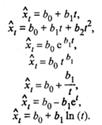 (54.4)
(54.4)
Правильно выбранная модель должна соответствовать характеру изменений тенденции исследуемого явления; При этом величина еt должна носить случайный характер с нулевой средней.
Кроме того, ошибки аппроксимации et должны быть независимыми между собой и подчиняться нормальному закону распределения et Î N (0, σ). Независимость ошибок et, т.е. отсутствие автокорреляции остатков, обычно проверяется по критерию Дарбина—Уотсона, основанного на статистике:
 (54.5)
(54.5)
где et = xt - .
Если отклонения не коррелированы, то величина DW приблизительно равна двум. При наличии положительной автокорреляции 0 ≤ DW ≤2,а отрицательной — 2 ≤ D W ≤ 4.
О коррелированности остатков можно также судить по коррелограмме для отклонений от тренда, которая представляет собой график функции относительно τ коэффициента автокорреляции, который вычисляется по формуле
 (54.6)
(54.6)
где τ = 0, 1, 2 ... .
После выбора наиболее подходящей аналитической функции для тренда его используют для прогнозирования на основе экстраполяции на заданное число временных интервалов.
Рассмотрим задачу сглаживания сезонных колебаний, исходя из ряда Vt = хt - , где xt — значение исходного временного ряда в момент t, а — оценка соответствующего значения тренда (t = 1, 2, ..., п).
Так как сезонные колебания представляют собой циклический, повторяющийся во времени процесс, то в качестве сглаживающих функций используется гармонический ряд (ряд Фурье) следующего вида:
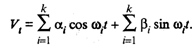
11)) Прогнозирование на основе экспоненциального сглаживания
Экстраполяция - это метод научного исследования, который основан на распространении прошлых и настоящих тенденций, закономерностей, связей на будущее развитие объекта прогнозирования. К методам экстраполяции относятся метод скользящей средней, метод экспоненциального сглаживания, метод наименьших квадратов.
Прогнозирование методом экспоненциального сглаживания является одним из самых простых способов прогнозирования. Прогноз может быть получен только на один период вперед. Если прогнозирование ведется в разрезе дней, то только на один день вперед, если недель, то на одну неделю.
Метод экспоненциального сглаживания наиболее эффективен при разработке среднесрочных прогнозов. Он приемлем при прогнозировании только на один период вперед. Его основные достоинства простота процедуры вычислений и возможность учета весов исходной информации. Рабочая формула метода экспоненциального сглаживания 
|
где t – период, предшествующий прогнозному; t+1 – прогнозный период; Ut+1 - прогнозируемый показатель; α - параметр сглаживания; Уt - фактическое значение исследуемого показателя за период, предшествующий прогнозному; Ut - экспоненциально взвешенная средняя для периода, предшествующего прогнозному.
При прогнозировании данным методом возникает два затруднения:
выбор значения параметра сглаживания α;
определение начального значения Uo.
Экспоненциально взвешенное скользящее среднее — разновидность взвешенной скользящей средней, веса которой убывают экспоненциально и никогда не равны нулю[3]. Определяется следующей формулой

где EMA t — значение экспоненциального скользящего среднего в точке  (последнее значение, в случае временного ряда), EMA t - 1 — значение экспоненциального скользящего среднего в точке t-1 (предыдущее значение в случае временного ряда), Pt — значение исходной функции в момент времени t (последнее значение, в случае временного ряда),
(последнее значение, в случае временного ряда), EMA t - 1 — значение экспоненциального скользящего среднего в точке t-1 (предыдущее значение в случае временного ряда), Pt — значение исходной функции в момент времени t (последнее значение, в случае временного ряда),  (сглаживающая константа от англ. smoothing constant) — коэффициент характеризующий скорость уменьшения весов, принимает значение от 0 и до 1, чем меньше его значение тем больше влияние предыдущих значений на текущую величину среднего.
(сглаживающая константа от англ. smoothing constant) — коэффициент характеризующий скорость уменьшения весов, принимает значение от 0 и до 1, чем меньше его значение тем больше влияние предыдущих значений на текущую величину среднего.
Первое значение экспоненциального скользящего среднего, обычно принимается равным первому значению исходной функции: EMA0 = P0
Коэффициент , может быть выбран произвольным образом, в пределах от 0 до 1, например, выражен через величину окна усреднения:

От величины α зависит, как быстро снижается вес влияния предшествующих наблюдений. Чем больше α, тем меньше сказывается влияние предшествующих лет. Если значение α близко к единице, то это приводит к учету при прогнозе в основном влияния лишь последних наблюдений. Если значение α близко к нулю, то веса, по которым взвешиваются уровни временного ряда, убывают медленно, т.е. при прогнозе учитываются все (или почти все) прошлые наблюдения.
Таким образом, если есть уверенность, что начальные условия, на основании которых разрабатывается прогноз, достоверны, следует использовать небольшую величину параметра сглаживания (α→0). Когда параметр сглаживания мал, то исследуемая функция ведет себя как средняя из большого числа прошлых уровней. Если нет достаточной уверенности в начальных условиях прогнозирования, то следует использовать большую величину α, что приведет к учету при прогнозе в основном влияния последних наблюдений.
Точного метода для выбора оптимальной величины параметра сглаживания α нет. В отдельных случаях автор данного метода профессор Браун предлагал определять величину α, исходя из длины интервала сглаживания. При этом α вычисляется по формуле: 
|
где n – число наблюдений, входящих в интервал сглаживания.
Алгоритм расчета экспоненциально сглаженных значений в любой точке ряда i основан на трех величинах:
фактическое значение Ai в данной точке ряда i,
прогноз в точке ряда Fi
некоторый заранее заданный коэффициент сглаживания W, постоянный по всему ряду.
Новый прогноз можно записать формулой:
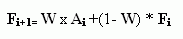
Расчет экспоненциально сглаженных значений
При практическом использовании метода экспоненциального сглаживания возникает две проблемы: выбор коэффициента сглаживания (W), который в значительной степени влияет на результаты и определение начального условия (Fi). С одной стороны, для сглаживания случайных отклонений величину нужно уменьшать. С другой стороны, для увеличения веса новых измерений нужно увеличивать.
Хотя, в принципе, W может принимать любые значения из диапазона 0 < W < 1, обычно ограничиваются интервалом от 0,2 до 0,5. При высоких значениях коэффициента сглаживания в большей степени учитываются мгновенные текущие наблюдения отклика (для динамично развивающихся фирм) и, наоборот, при низких его значениях сглаженная величина определяется в большей степени прошлой тенденцией развития, нежели текущим состоянием отклика системы (в условиях стабильного развития рынка).
Выбор коэффициента постоянной сглаживания является субъективным. Аналитики большинства фирм при обработке рядов используют свои традиционные значения W.
12)) Автокорреляция уровней ряда. Свойства коэффициентов автокорреляции. Коррелограмма
Автокорреляция уровней ряда. При наличии во временном ряде тенденции и циклических колебаний значения каждого последующего уровня ряда зависят от предыдущих. Зависимость значений уровней временного ряда от предыдущего (сдвиг на один временной интервал), предпредыдущего (сдвиг на два временных интервала) и т.д. уровней того же временного ряда называется автокорреляцией во временном ряду. Наличие автокорреляции указывает на взаимосвязанность уровней ряда динамики, на сильную зависимость последующих уровней от предшествующих. Так как методика корреляционного анализа применима лишь в случае, когда уровни каждого из взаимосвязанных рядов являются статистически независимыми, необходимо всегда проверять наличие автокорреляции в исследуемых рядах динамики. Количественно ее можно измерить с помощью линейного коэффициента корреляции между уровнями исходного временного ряда и уровнями этого ряда, сдвинутыми на несколько шагов во времени. Наиболее важным из различных коэффициентов корреляции является первый  , измеряющий тесноту связи между уровнями
, измеряющий тесноту связи между уровнями  и
и  Среди природных и общественных явлений нередко встречаются такие, которые связаны между собой не в одном и том же периоде времени, а с некоторым запозданием - по-английски - lag, откуда пошел термин лаг. Таким образом, лаг – число периодов, по которым рассчитывается коэффициент автокорреляции между парами элементов ряда
Среди природных и общественных явлений нередко встречаются такие, которые связаны между собой не в одном и том же периоде времени, а с некоторым запозданием - по-английски - lag, откуда пошел термин лаг. Таким образом, лаг – число периодов, по которым рассчитывается коэффициент автокорреляции между парами элементов ряда
|
из
5.00
|
Обсуждение в статье: Трендовые модели прогнозирования |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы