 |
Главная |


Структурные средние величины
|
из
5.00
|
К наиболее часто используемым структурным средним относятся статистическая мода и статистическая медиана.
Статистическая мода - это наиболее часто повторяющееся значение величины X в статистической совокупности.
Если X задан дискретно, то мода определяется без вычисления как значение признака с наибольшей частотой. В статистической совокупности бывает 2 и более моды, тогда она считается бимодальной(если моды две) илимультимодальной (если мод более двух), и это свидетельствует о неоднородности совокупности.
Например, на предприятии работает 16 человек: 4 из них - со стажем 1 год, 3 человека - со стажем 2 года, 5 - со стажем 3 года и 4 человека - со стажем 4 года. Таким образом, модальный стаж Мо=3 года, поскольку частота этого значения максимальна (f=5).
Если X задан равными интервалами, то сначала определяется модальный интервал как интервал с наибольшей частотой f. Внутри этого интервала находят условное значение моды по формуле:
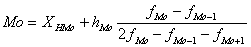
где Мо – мода;
ХНМо – нижняя граница модального интервала;
hМо – размах модального интервала (разность между его верхней и нижней границей);
fМо – частота модальноого интервала;
fМо-1 – частота интервала, предшествующего модальному;
fМо+1 – частота интервала, следующего за модальным.
Например, на предприятии 10 работников со стажем работы до 3 лет, 20 - со стажем от 3 до 5 лет, 5 работников - со стажем более 5 лет. Рассчитаем модальный стаж работы в модальном интервале от 3 до 5 лет: Мо = 3 + 2*(20-10)/(2*20-10-5) = 3,8 (года).
Если размах интервалов h разный, то вместо частот f необходимо использовать плотности интервалов, рассчитываемые путем деления частот f на размах интервала h.
Статистическая медиана – это значение величины X, которое делит упорядоченную по возрастанию или убыванию статистическую совокупность на 2 равных по численности части. В итоге у одной половины значение больше медианы, а у другой - меньше медианы.
Если X задан дискретно, то для определения медианы все значения нумеруются от 0 до N в порядке возрастания, тогда медиана при четном числе N будет лежать посередине между X c номерами 0,5N и (0,5N+1), а при нечетном числе N будет соответствовать значению X с номером 0,5(N+1).
Например, имеются данные о возрасте студентов-заочников в группе из 10 человек - X: 18, 19, 19, 20, 21, 23, 23, 25, 28, 30 лет. Эти данные уже упорядочены по возрастанию, а их количество N=10 - четное, поэтому медиана будет находиться между X с номерами 0,5*10=5 и (0,5*10+1)=6, которым соотвествует значения X5=21 и X6=23, тогда медиана: Ме = (21+23)/2 = 22 (года).
Если X задан в виде равных интервалов, то сначала определяется медианный интервал (интервал, в котором заканчивается одна половина частот f и начинается другая половина), в котором находят условное значение медианы по формуле:
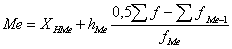
где Ме – медиана;
ХНМе – нижняя граница медианного интервала;
hМе – размах медианного интервала (разность между его верхней и нижней границей);
fМе – частота медианного интервала;
∑fМе-1 – сумма частот интервалов, предшествующих медианному.
В ранее рассмотренном примере при расчете модального стажа (на предприятии 10 работников со стажем работы до 3 лет, 20 - со стажем от 3 до 5 лет, 5 работников - со стажем более 5 лет) рассчитаем медианный стаж. Половина общего числа работников составляет (10+20+5)/2 = 17,5 и находится в интервале от 3 до 5 лет, а в первом интервале до 3 лет - только 10 работников, а в первых двух - (10+20)=30, что больше 17,5, значит интервал от 3 до 5 лет - медианный. Внутри него определяем условное значение медианы: Ме = 3+2*(0,5*30-10)/20 = 3,5 (года).
Также как и в случае с модой, при определении медианы если размах интервалов h разный, то вместо частот f необходимо использовать плотности интервалов, рассчитываемые путем деления частот f на размах интервала h.
Также в статистике применяются такие структурные средние величины как квартиль и дециль.
Статистический квартиль – это значение величины X, которое делит упорядоченную по возрастанию или убыванию статистическую совокупность на 4 равных по численности части. В итоге у одной половины значение больше медианы, а у другой - меньше медианы.
Статистический дециль – это значение величины X, которое делит упорядоченную по возрастанию или убыванию статистическую совокупность на 10 равных по численности части. В итоге у одной половины значение больше медианы, а у другой - меньше медианы.
Понятие вариации
Средняя величина дает обобщенную характеристику изучаемой совокупности по некоторому варьирующему (изменяющемуся) признаку, т.е. показывает типичный для данных условий уровень этого признака. Поскольку средняя величина - абстрактная величина, то для характеристики структуры ряда привлекаются описательные показатели – мода и медиана. Однако в двух совокупностях средние, мода и медиана могут быть одинаковыми, но отдельные значения признака при этом могут близко примыкаться к средней и мало от нее отличаться или, наоборот, могут далеко отставать (стоять) от средней и сильно от нее отличаться. Нетрудно сделать важный вывод по совокупности: в первом случае средняя будет хорошо представлять (характеризовать) всю совокупность, во втором случае средняя будет плохо представлять всю совокупность.
Следовательно наряду со средними величинами большое практическое и теоретическое значение имеет изучение отклонений от средних.
Оценки колеблемости отдельных значений от средней называют показателями вариации.
Термин «вариация» происходит от латинского слова variation – изменение, колеблемость, различие. Однако не всякие различия принято называть вариацией. Под вариацией в статистике понимают такие количественные изменения величин исследуемого признака в пределах качественно однородной совокупности, которые обусловлены взаимосвязанным (перекрещивающимся) воздействием различных факторов. Отсюда различают случайную и систематическую вариацию признака.
В статистических исследованиях особый интерес представляет анализ систематической вариации, т.к. изучая силу и характер вариации в исследуемой совокупности можно оценить насколько однородной является данная совокупность в количественном, а иногда и качественном отношении, а следовательно насколько характерной является исчисленная средняя величина. Поэтому средние характеристики необходимо дополнять показателями, измеряющими отклонения от средних.
Степень близости индивидуальных значений признака (вариант) к средней измеряется рядом абсолютных, средних и относительных статистических показателей. К ним относятся размах вариации, среднее линейное отклонение, дисперсия, среднее квадратическое отклонение, показатели степени вариации с порядковыми (ранговыми) характеристиками распределения, показатели относительного рассеивания.
Для всех показателей вариации общим является следующие:
• если показатель вариации близко к нулю (т.е. индивидуальные значения признака мало отличаются друг от друга), то средняя арифметическая будет достаточно показательной (надежной) характеристикой данной совокупности;
• если же ряд распределения характеризуется значительным рассеиванием (величина показателя вариации сильно отличается от нуля, является большой), то средняя арифметическая будет ненадежной и ее практическое применение будет ограничено.
Показатели вариации
Вариацию можно определить как количественное различие значений одного и того же признака у отдельных единиц совокупности. Термин «вариация» имеет латинское происхождение - variatio, что означает различие, изменение, колеблемость. Изучение вариации в статистической практике позволяет установить зависимость между изменением, которое происходит в исследуемом признаке, и теми факторами, которые вызывают данное изменение.
Вариация - это различие значений величин X у отдельных единиц статистической совокупности. Для изучения силы вариации рассчитывают следующие показатели вариации: размах вариации, среднее линейное отклонение, линейный коэффициент вариации, дисперсия, среднее квадратическое отклонение, квадратический коэффициент вариации.
Размах вариации – это разность между максимальным и минимальным значениями X из имеющихся в изучаемой статистической совокупности:
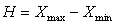
Недостатком показателя H является то, что он показывает только максимальное различие значений X и не может измерять силу вариации во всей совокупности.
Cреднее линейное отклонение - это средний модуль отклонений значений X от среднего арифметического значения. Его можно рассчитывать по формуле средней арифметической простой - получим среднее линейное отклонение простое:
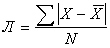
Например, студент сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Средняя арифметическая = 4. Рассчитаем среднее линейное отклонение простое: Л = (|3-4|+|4-4|+|4-4|+|5-4|)/4 = 0,5.
Если исходные данные X сгруппированы (имеются частоты f), то расчет среднего линейного отклонения выполняется по формуле средней арифметической взвешенной - получим среднее линейное отклонение взвешенное:
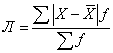
Вернемся к примеру про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5. Ранее уже была рассчитана средняя арифметическая = 4 и среднее линейное отклонение простое = 0,5. Рассчитаем среднее линейное отклонение взвешенное: Л = (|3-4|*1+|4-4|*2+|5-4|*1)/4 = 0,5.
Линейный коэффициент вариации - это отношение среднего линейного отклонение к средней арифметической:
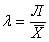
С помощью линейного коэффициента вариации можно сравнивать вариацию разных совокупностей, потому что в отличие от среднего линейного отклонения его значение не зависит от единиц измерения X.
В рассматриваемом примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, линейный коэффициент вариации составит 0,5/4 = 0,125 или 12,5%.
Дисперсия - это средний квадрат отклонений значений X от среднего арифметического значения. Дисперсию можно рассчитывать по формуле средней арифметической простой - получим дисперсию простую:

В уже знакомом нам примере про студента, который сдал 4 экзамена и получил оценки: 3, 4, 4 и 5, ранее уже была рассчитана средняя арифметическая = 4. Тогда дисперсия простая σ2 = ((3-4)2+(4-4)2+(4-4)2+(5-4)2)/4 = 0,5.
Если исходные данные X сгруппированы (имеются частоты f), то расчет дисперсии выполняется по формуле средней арифметической взвешенной - получим дисперисю взвешенную:

В рассматриваемом примере про студента, который сдал 4 экзамена и получил следующие оценки: 3, 4, 4 и 5, рассчитаем дисперсию взвешенную: Д = ((3-4)2*1+(4-4)2*2+(5-4)2*1)/4 = 0,5.
Свойства дисперсии:
Свойство 1. Дисперсия постоянной величины равна нулю.
Свойство 2. Уменьшение всех значений признака на одну и ту же величину A не меняет величины дисперсии 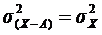 . Значит, средний квадрат отклонений можно вычислить не по заданным значениям признака, а по отклонениям их от какого-либо постоянного числа.
. Значит, средний квадрат отклонений можно вычислить не по заданным значениям признака, а по отклонениям их от какого-либо постоянного числа.
Свойство 3. Уменьшение всех значений признака в K раз уменьшает дисперсию в K2 раз, а среднее квадратическое отклонение в K раз 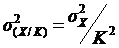 . Значит, все значения признака можно разделить на какое-то постоянное число, например, на величину интервала ряда, исчислить среднее квадратическое отклонение, а затем умножить его на постоянное число:
. Значит, все значения признака можно разделить на какое-то постоянное число, например, на величину интервала ряда, исчислить среднее квадратическое отклонение, а затем умножить его на постоянное число: 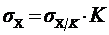 .
.
Свойство 4. Если вычислить средний квадрат отклонений от любой величины A, в той или иной степени отличающейся от средней арифметической (), то он всегда будет больше среднего квадрата отклонений, вычисленного от средней арифметической 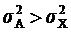 . Средний квадрат отклонений при этом будет больше на величину ( – A)2 :
. Средний квадрат отклонений при этом будет больше на величину ( – A)2 :
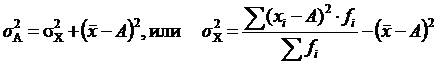 .
.
Значит, дисперсия от средней величины всегда меньше дисперсий, вычисленных от любых других величин, т.е. она имеет свойство минимальности.
На этих математических свойствах дисперсии основываются способы, которые позволяют упростить ее вычисление. Например, расчет дисперсии по способу моментов или способу отсчета от условного нуля применяется в вариационных рядах с равными интервалами. Расчет производится по формуле:
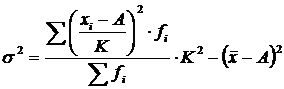 ,
,
где K – ширина интервала;
A – условный нуль, в качестве которого удобно использовать середину интервала, обладающего наибольшей частотой;
 – момент второго порядка.
– момент второго порядка.
Между средним линейным и средним квадратическим отклонениями существует примерное соотношение 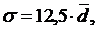 если фактическое распределение близко к нормальному.
если фактическое распределение близко к нормальному.
В условиях нормального распределения существует следующая зависимость между величиной среднего квадратического отклонения и количеством наблюдений:
1) в пределах ± 1σ располагается 68,3 % количества наблюдений;
2) в пределах ± 2σ – 95,4 %;
3) в пределах ± 3σ – 99,7 %;
В действительности, на практике почти не встречаются отклонения, которые превышают ±3σ. Отклонение 3σ может считаться максимально возможным. Это положение называют «правилом трех сигм».
Если значения X - это доли совокупности, то для расчета дисперсии используют частную формулу дисперсии доли:
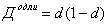 .
.
|
из
5.00
|
Обсуждение в статье: Структурные средние величины |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы