 |
Главная |


Технология тиражирования данных
|
из
5.00
|
Принципиальная характеристика тиражирования данных (Data Replication - DR) заключается в отказе от физического распределения данных. Суть DR состоит в том, что любая база данных (как для СУБД, так и для работающих с ней пользователей) всегда является локальной; данные размещаются локально на том узле сети, где они обрабатываются; все транзакции в системе завершаются локально.
Тиражирование данных - это асинхронный перенос изменений объектов исходной базы данных в базы, принадлежащим различным узлам распределенной системы. Функции DR выполняет, как правило, специальный модуль СУБД - сервер тиражирования данных, называемый репликатором (так устроены СУБД CA-OpenIngres и Sybase). В Informix-OnLine Dynamic Server репликатор встроен в сервер, в Oracle 7 для использования DR необходимо приобрести дополнительно к Oracle7 DBMS опцию Replication Option.
Специфика механизмов DR зависит от используемой СУБД. Простейший вариант DR - использование "моментальных снимков" (snapshot). Рассмотрим пример из Oracle:
CREATE SNAPSHOT unfilled_orders
REFRASH COMPLETE
START WITH TO_DATE ('DD-MON-YY HH23:MI:55')
NEXT SYSDATE + 7
AS SELECT customer_name, customer_address, order_date
FROM customer@paris, order@london
WHERE customer.cust_name = order.customer_number AND
order_complete_flag = "N";
"Моментальный снимок" в виде горизонтальной проекции объединения таблиц customer и order будет выполнен в 23:55 и будет повторятся каждые 7 дней. Каждый раз будут выбираться только завершенные заказы.
Реальные схемы тиражирования, разумеется, устроены более сложно. В качестве базиса для тиражирования выступает транзакция к базе данных. В то же время возможен перенос изменений группами транзакций, периодически или в некоторый момент времени, что дает возможность исследовать состояние принимающей базы на определенный момент времени.
Детали тиражирования данных полностью скрыты от прикладной программы; ее функционирование никак не зависят от работы репликатора, который целиком находится в ведении администратора базы данных. Следовательно, для переноса программы в распределенную среду с тиражируемыми данными не требуется ее модификации. В этом, собственно, состоит качество 6 в определении Дэйта.
Синхронное обновление DDB и DR-технология - в определенном смысле антиподы. Краеугольный камень первой - синхронное завершение транзакций одновременно на нескольких узлах распределенной системы, то есть синхронная фиксация изменений в DDB. Ee "Ахиллесова пята" - жесткие требования к производительности и надежности каналов связи. Если база данных распределена по нескольким территориально удаленным узлам, объединенным медленными и ненадежными каналами связи, а число одновременно работающих пользователей составляет сотни и выше, то вероятность того, что распределенная транзакция будет зафиксирована в обозримом временном интервале, становится чрезвычайно малой. В таких условиях (характерных, кстати, для большинства отечественных организаций) обработка распределенных данных практически невозможна.
DR-технология не требует синхронной фиксации изменений, и в этом ее сильная сторона. В действительности далеко не во всех задачах требуется обеспечение идентичности БД на различных узлах в любое время. Достаточно поддерживать тождественность данных лишь в определенные критичные моменты времени. Можно накапливать изменения в данных в виде транзакций в одном узле и периодически копировать эти изменения на другие узлы.
Налицо преимущества DR-технологии. Во-первых, данные всегда расположены там, где они обрабатываются - следовательно, скорость доступа к ним существенно увеличивается. Во-вторых, передача только операций, изменяющих данные (а не всех операций доступа к удаленным данным), и к тому же в асинхронном режиме позволяет значительно уменьшить трафик. В-третьих, со стороны исходной базы для принимающих баз репликатор выступает как процесс, инициированный одним пользователем, в то время как в физически распределенной среде с каждым локальным сервером работают все пользователи распределенной системы, конкурирующие за ресурсы друг с другом. Наконец, в-четвертых, никакой продолжительный сбой связи не в состоянии нарушить передачу изменений. Дело в том, что тиражирование предполагает буферизацию потока изменений (транзакций); после восстановления связи передача возобновляется с той транзакции, на которой тиражирование было прервано.
DR-технология данных не лишена недостатков. Например, невозможно полностью исключить конфликты между двумя версиями одной и той же записи. Он может возникнуть, когда вследствие все той же асинхронности два пользователя на разных узлах исправят одну и ту же запись в тот момент, пока изменения в данных из первой базы данных еще не были перенесены во вторую. При проектировании распределенной среды с использованием DR-технологии необходимо предусмотреть конфликтные ситуации и запрограммировать репликатор на какой-либо вариант их разрешения. В этом смысле применение DR-технологии - наиболее сильная угроза целостности DDB. На мой взгляд, DR-технологию нужно применять крайне осторожно, только для решения задач с жестко ограниченными условиями и по тщательно продуманной схеме, включающей осмысленный алгоритм разрешения конфликтов.
2. Архитектура "клиент-сервер"
Распределенные системы - это системы "клиент-сервер". Существует по меньшей мере три модели "клиент-сервер" (подробно о них рассказано в [2]):
· Модель доступа к удаленным данным (RDA-модель)
· Модель сервера базы данных (DBS-модель)
· Модель сервера приложений (AS-модель)
Первые две являются двухзвенными и не могут рассматриваться в качестве базовой модели распределенной системы (ниже будет показано, почему это так). Трехзвенная модель хороша тем, что в ней интерфейс с пользователем полностью независим от компонента обработки данных. Собственно, трехзвенной ее можно считать постольку, поскольку явно выделены:
· Компонент интерфейса с пользователем
· Компонент управления данными (и базами данных в том числе)
а между ними расположено программное обеспечение промежуточного слоя (middleware), выполняющее функции управления транзакциями и коммуникациями, транспортировки запросов, управления именами и множество других. Middleware - это ГЛАВНЫЙ компонент распределенных систем и, в частности, DDB-систем. Главная ошибка, которую мы совершаем на нынешнем этапе - полное игнорирование middleware и использование двухзвенных моделей "клиент-сервер" для реализации распределенных систем.
Существует фундаментальное различие между технологией "SQL-клиент - SQL-сервер" и технологией продуктов класса middleware (например, менеджера распределенных транзакций Tuxedo System). В первом случае клиент явным образом запрашивает данные, зная структуру базы данных (имеет место так называемый data shipping, то есть "поставка данных" клиенту). Клиент передает СУБД SQL-запрос, в ответ получает данные. Имеет место жесткая связь типа "точка- точка", для реализации которой все СУБД используют закрытый SQL-канал (например, Oracle SQL*Net). Он строится двумя процессами: SQL/Net на компьютере - клиенте и SQL/Net на компьютере-сервере и порождается по инициативе клиента оператором CONNECT. Канал закрыт в том смысле, что невозможно, например, написать программу, которая будет шифровать SQL- запросы по специальному алгоритму (стандартные алгоритмы шифрования, используемые, например, в Oracle SQL*Net, вряд ли будут сертифицированы ФАПСИ).
В случае трехзвенной схемы клиент явно запрашивает один из сервисов (предоставляемых прикладным компонентом), передавая ему некоторое сообщение (например) и получает ответ также в виде сообщения. Клиент направляет запрос в информационную шину (которую строит Tuxedo System), ничего не зная о месте расположения сервиса. Имеет место так называемый function shipping (то есть "поставка функций" клиенту). Важно, что для Клиента база данных (в том числе и DDB) закрыта слоем Сервисов. Более того, он вообще ничего не знает о ее существовании, так как все операции над базой данных выполняются внутри сервисов.
Сравним два подхода. В первом случае мы имеем жесткую схему связи "точка-точка" с передачей открытых SQL-запросов и данных, исключающую возможность модификации и работающую только в синхронном режиме "запрос-ответ". Во втором случае определен гибкий механизм передачи сообщений между клиентами и серверами, позволяющий организовывать взаимодействие между ними многочисленными способами.
Таким образом, речь идет о двух принципиально разных подходах к построению информационных систем "клиент-сервер". Первый из них устарел и явно уходит в прошлое. Дело в том, что SQL (ставший фактическим стандартом общения с реляционными СУБД) был задуман и реализован как декларативный язык запросов, но отнюдь не как средство взаимодействия "клиент-сервер" (об этой технологии тогда речи не было). Только потом он был "притянут за уши" разработчиками СУБД в качестве такого средства. На волне успеха реляционных СУБД в последние годы появилось множество систем быстрой разработки приложений для реляционных баз данных (VisualBasic, PowerBuilder, SQL Windows, JAM и т.д.). Все они опирались на принцип генерации кода приложения на основе связывания элементов интерфейса с пользователем (форм, меню и т.д.) с таблицами баз данных. И если для быстрого создания несложных приложений с небольшим числом пользователей этот метод подходит как нельзя лучше, то для создания корпоративных распределенных информационных систем он абсолютно непригоден.
Для этих задач необходимо применение существенно более гибких систем класса middleware (Tuxedo System, Teknekron), которые и составляют предмет нашей профессиональной деятельности и базовый инструментарий при реализации больших проектов.
Три модели
"Клиент-сервер" - это модель взаимодействия компьютеров в сети. Редко бывает так, чтобы они были совершенно равноправными. Как правило, один компьютер в сети располагает информационно-вычислительными ресурсами, такими как процессоры, файловая система, почтовая служба, служба печати, база данных. Другие же компьютеры пользуются ими. Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, желающий им воспользоваться - клиентом. Конкретный сервер характеризуется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого - обслуживать запросы клиентов, связанные с обработкой баз данных; если ресурс - это файловая система, то говорят о файловом сервере или файл-сервере и т.д.
Этот же принцип распространяется и на взаимодействие процессов. Если один из них выполняет некоторые функции, предоставляя другим соответствующий набор услуг, такой процесс рассматривается в качестве сервера. Процессы, пользующиеся этими услугами, принято называть клиентами.
Сегодня технология "клиент-сервер" получает все большее распространение, однако сама по себе она не предлагает универсальных рецептов. Она лишь дает общее представление о том, как должна быть организована современная распределенная информационная система. В то же время реализации этой технологии в конкретных программных продуктах и даже в видах программного обеспечения различаются весьма существенно.
Один из основных принципов технологии "клиент-сервер" заключается в разделении функций стандартного приложения на три группы, имеющие различную природу. Первая группа - это функция ввода и отображения данных. Вторая группа объединяет чисто прикладные функции, характерные для данной предметной области. Наконец, к третьей группе относятся фундаментальные функции хранения и управления данными (базами данных, файловыми системами и т.д.)
В соответствии с этим в любом приложении выделяются следующие логические компоненты:
· компонент представления (presentation), реализующий функции первой группы;
· прикладной компонент (business application), поддерживающий функции второй группы;
· компонент доступа к информационным ресурсам (resource acces) или менеджер ресурсов (Resource manager), поддерживающий функции третьей группы.
Различия в реализации приложений в рамках технологии "клиент-сервер" определяются тремя факторами. Во-первых, тем, какие механизмы используются для реализации функций всех трех групп. В-третьих - как логические компоненты распределяются между компьютерами в сети. Выделяются три подхода, каждый из которых реализован в соответствующей модели:
· модель доступа к удаленным данным (Remote Date Access - RDA);
· модель сервера базы данных (DateBase Server - DBS);
· модель сервера приложений (Application Server - AS).
В RDA-модели коды компонента представления и прикладного компонента совмещены и выполнятся на компьютере-клиенте, Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается, как правило, операторами специального языка (языка SQL, например, если речь идет о базах данных) или вызовами функций специальной библиотеки ( если имеется соответствующий API). Запросы к информационным ресурсам направляются по сети удаленному компьютеру (например, серверу базы данных). Последний обрабатывает и выполняет запросы и возвращает клиенту блоки данных (рисунок 1). Говоря об архитектуре "клиент-сервер", в большинстве случаев имеют в виду именно эту модель.
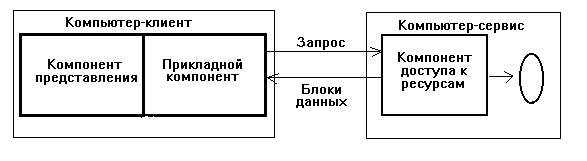
Рисунок 1.
Модель доступа к удаленным данным.
DSB-модель (рисунок 2) строится в предположении, что процесс, выполняемый на компьютере-клиенте, ограничивается функциями представления, в то время как собственно прикладные функции реализованы в хранимых процедурах (stored procedure), которые также называют компилируемыми резидентными процедурами, или процедурами базы данных Они хранятся непосредственно в базе данных и выполняются на компьютере-сервере базы данных (где функционирует и компонент, управляющий доступом к данным, то есть ядро СУБД). Понятие информационного ресурса сужено до баз данных, поскольку механизм хранимых процедур - отличительная характеристика DBS-модели - имеется пока только в СУБД, да и то не во всех.
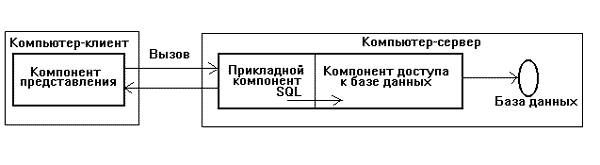
Рисунок 2.
Модель сервера базы данных.
На практике часто используются смешанные модели, когда поддержка целостности базы данных и некоторые простейшие прикладные функции поддерживаются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая выполняется на компьютере-клиенте (RDA-модель). Однако такие решения, включающие элементы сразу двух моделей, не могут принципиально изменить наших представлений о их соотношении.
В AS-модели (рисунок 3) процесс, выполняющийся на компьютере-клиенте, отвечает, как обычно, за ввод и отображение данных (то есть реализует функции первой группы). Прикладные функции выполняются группой процессов (серверов приложений), функционирующих на удаленном компьютере (или нескольких компьютерах). Доступ к информационным ресурсам, необходимым для решения прикладных задач, обеспечивается ровно тем же способом, что и в RDA-модели. Из прикладных компонентов доступны ресурсы различных типов - базы данных, индексированные файлы, очереди и др. Серверы приложений выполняются, как правило, на том же компьютере, где функционирует менеджер ресурсов, однако могут выполняться и на других компьютерах.
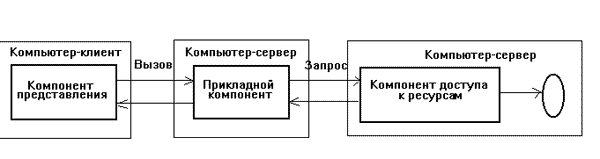
Рисунок 3.
Модель сервера приложений.
В чем заключается фундаментальное различие между этими моделями? RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во втором - интегрируется в компонент доступа к информационным ресурсам. Напротив, в AS-модели реализована классическая трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший элемент приложения, для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами. Собственно, из этой особенности AS-модели и вытекают ее преимущества, которые имеют важнейшее значение для чисто практической деятельности.
RDA-модель
Главное преимущество RDA-модели лежит в практической плоскости. Сегодня существует множество инструментальных средств, обеспечивающих быстрое создание desktop-приложений, работающих с SQL-ориентированными СУБД. Большинство из них поддерживают графический интерфейс пользователя в MS Windows, стандарт интерфейса ODBC, содержат средства автоматической генерации кода. Иными словами, основное достоинство RDA-модели заключается в унификации и широком выборе средств разработки приложений. Подавляющее большинство этих средств разработки на языках четвертого поколения ( включая и средства автоматизации программирования) как раз и создают коды, в которых смешаны прикладные функции и функции представления.
RDA-модель имеет ряд ограничений.
Во-первых, взаимодействие клиента и сервера посредством SQL-запросов существенно загружает сеть. Поскольку приложение является нераспределенным и вся его логика локализована на компьютере-клиенте, постольку приложение нуждается в передаче по сети данных большого объема, возможно, избыточных. Как только число клиентов возрастает, сеть превращается в "горлышко бутылки", тормозя быстродействие всей информационной системы.
Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно. Очевидно, что если различные по своей природе функции (функции представления и чисто прикладные функции) смешаны в одной и той же программе, написанной на языке 4GL, то при необходимости изменения прикладных функций приходится переписывать всю программу целиком. При коллективной работе над проектом, как правило, каждому разработчику поручается реализация отдельных прикладных функций, что делает невозможным контроль за их взаимной непротиворечивостью. Каждому из разработчиков приходится программировать интерфейс с пользователем, что ставит под вопрос единый стиль интерфейса и его целостность.
DBS-модель
Несмотря на широкое распространение, RDA-модель уступает место более технологичной DBS-модели. Последняя реализована в некоторых реляционных СУБД (Ingres, Sybase, Oracle). Ее основу составляет механизм хранимых процедур - средство программирования ядра СУБД. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует ядро СУБД. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД. Попытки стандартизации языка SQL, касающиеся хранимых процедур, пока не привели к ощутимому успеху. Кроме того, во многих реализациях процедуры являются интерпретируемыми, что делает их выполнение более медленным, нежели выполнение программ, написанных на языках третьего поколения. Механизм хранимых процедур - один из составных компонентов активного сервера базы данных [2].
В DBS-модели приложение является распределенным. Компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент (реализующий бизнес-функции) оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Преимущества DBS-модели перед RDA-моделью очевидны: это и возможность централизованного администрирования бизнес-функций, и снижение трафика сети, и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. Однако есть и недостатки.
Во-первых, средства, используемые для написания хранимых процедур, строго говоря, не являются языками программирования в полном смысле слова. Скорее, это - разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональным возможностям с языками третьего поколения, такими как C или Pascal. Они встроены в конкретные СУБД, и, естественно, рамки их использования ограничены. Следовательно, система, в которой прикладной компонент реализован при помощи хранимых процедур, не является мобильной относительно СУБД. Кроме того, в большинстве СУБД отсутствуют возможности отладки и тестирования хранимых процедур, что превращает последние в весьма опасный механизм. Действительно, сколько-нибудь сложная неотлаженная комбинация срабатывания триггеров и запуска процедур может, по меткому выражению одного из разработчиков, "полностью разнести всю базу данных".
Во-вторых, DBS-модель не обеспечивает требуемой эффективности использования вычислительных ресурсов. Объективные ограничения в ядре СУБД не позволяют пока организовать в его рамках эффективный баланс загрузки, миграцию процедур на другие компьютеры-серверы БД и реализовать другие полезные функции. Попытки разработчиков СУБД предусмотреть в своих системах эти возможности (распределенные хранимые процедуры, запросы с приоритетами и т. д.) пока не позволяют добиться желаемого эффекта.
В-третьих, децентрализация приложений (один из ключевых факторов современных информационных технологий) требует существенного разнообразия вариантов взаимодействия клиента и сервера. При реализации прикладной системы могут понадобиться такие механизмы взаимодействия, как хранимые очереди, асинхронные вызовы и т. д., которые в DBS-модели не поддерживаются.
Сегодня вряд ли можно говорить о том, что хранимые процедуры в их нынешнем состоянии представляют собой адекватный механизм для описания бизнес-функций и реализации прикладного компонента. Для того, чтобы превратить их в действительно мощное средство, разработчики СУБД должны воспроизвести в них следующие возможности:
· расширение изобразительный средства языков процедур;
· средства отладки и тестирования хранимых процедур;
· предотвращение конфликтов процедур с другими программами;
· поддержка приоритетной обработки запросов.
Между тем эти возможности уже реализованы в AS-модели, которая в наибольшей степени отражает сильные стороны технологии "клиент-сервер".
AS-модель
Основным элементом принятой в AS-модели трехзвенной схемы является сервер приложения. В его рамках реализовано несколько прикладных функций, каждая из которых оформлена как служба (service) и предоставляет некоторые услуги всем программам, которые желают и могут ими воспользоваться. Серверов приложений может быть несколько, и каждый их них предоставляет определенный набор услуг. Любая программа, которая пользуется ими, рассматривается как клиент приложения (Applicaation Client - AC). Детали реализации прикладных функций в сервере приложений полностью скрыты от клиента приложения. AC обращается с запросом к конкретной службе, но не к AS, то есть серверы приложений обезличены и служат лишь своего рода "рамкой" для оформления служб, что позволяет эффективно управлять балансом загрузки. Запросы, поступающие от АС, выстраиваются в очередь к AS-процессу, который извлекает и передает их для обработки службе в соответствии с приоритетами.
АС трактуется более широко, чем компонент представления. Он может поддерживать интерфейс с конечным пользователем (тогда он является компонентом представления), может обеспечивать поступление данных от некоторых устройств (например, датчиков), может, наконец, сам по себе быть AS. Последнее позволяет реализовать прикладную систему, содержащую AS нескольких уровней. Архитектура такой системы может выглядеть как ядро, окруженное концентрическими кольцами. Ядро состоит из серверов приложений, в которых реализованы базовые прикладные функции. Кольца символизируют наборы AS являющихся клиентами по отношению к серверам нижнего уровня. Число уровней серверов в AS-модели, вообще говоря, не ограничено.
Нетрудно видеть, что AS-модель имеет универсальный характер. Четкое разграничение логических компонентов и рациональный выбор программных средств для их реализации обеспечивают модели такой уровень гибкости и открытости, который пока недостижим в RDA- и DBS-моделях. Именно AS-модель используется в качестве фундамента относительно нового для наших пользователей вида программного обеспечения - мониторов транзакций.
Мониторы транзакций
Мониторы обработки транзакций (Transaction Processing Monitor - TPM), или, проще, мониторы транзакций - программные системы (которые часто относят к категории middleware), обеспечивающие эффективное управление информационно-вычислительными ресурсами в распределенной системе. Они представляют собой гибкую, открытую среду для разработки и управления мобильными приложениями, ориентированными на оперативную обработку распределенных транзакций. В числе важнейших характеристик ТРМ - масштабируемость, поддержка функциональной полноты и целостности приложений, достижение максимальной производительности при обработке данных при невысоких стоимостных показателях, поддержка целостности данных в гетерогенной среде.
|
из
5.00
|
Обсуждение в статье: Технология тиражирования данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы