 |
Главная |


Суть метода семантического дифференциала
|
из
5.00
|
Семантический дифференциал (СД) – один из проективных методов социологии, опирается на достижения психосемантики, был разработан группой американских психологов во главе с Ч. Осгудом в 1952 году. Он применяется в исследованиях, связанных с восприятием и поведением человека, с анализом социальных установок и личностных смыслов. Метод СД является комбинацией метода контролируемых ассоциаций и процедур шкалирования.
Психосемантические методы переводят информацию с когнитивного уровня (а исследовательская задача всегда сформулирована в его понятиях), на аффективный уровень, где эта информация закодирована не языковыми формами, а разнообразными ощущениями.
Метод семантического дифференциала основывается на явлении синестезии (мышления по аналогии, когда одни чувственные восприятия возникают под воздействием других) и является операциональным способом “улавливания” эмоциональной стороны смысла, воспринимаемых индивидом в объектах. СД позволяет выявить бессознательные ассоциативные связи между объектами в сознании людей.
Метод СД позволяет найти систему латентных факторов, в рамках которых индивид оценивает объекты. По существу, семантическое пространство – исследовательская модель структуры индивидуального сознания, и задача состоит в определении того, где в этом пространстве находится изучаемый объект.
Тестируемые объекты (название, марка, упаковка и т.п.) оцениваются по ряду бимодальных семибалльных шкал, полюса которых обычно задаются вербально при помощи антонимов: хороший – плохой, теплый – холодный, активный – пассивный и т.п. Предполагается, что человек способен оценить изучаемый объект, соотнося интенсивность внутреннего переживания по поводу объекта с заданной оценочной шкалой. Деления шкалы фиксируют различные степени данного качества объекта. Шкалы, коррелирующие между собой, группируются в независимые факторы, образующие семантическое пространство.
Наряду с вербальными, разработаны также невербальные семантические дифференциалы, где в качестве полюсов шкал используются графические оппозиции, живописные картины, фотопортреты.
В исследованиях часто используются монополярные шкалы, с помощью которых объекты оцениваются по выраженности одного свойства: насколько объект хороший, насколько теплый и т.п. В случае бимодальных шкал респондент оценивает где находится для него объект “А” по шкале “дорогой – дешевый”, а при унимодальных шкалах оценивается насколько свойство “дороговизна” присуще объекту “А”. Применение унимодальных шкал вызвано тем, что зачастую антонимичные прилагательные на самом деле не являются полными противоположностями – нехороший не всегда является плохим.
В классическом варианте Ч. Осгуда в качестве шкал использовались исключительно коннотативные признаки, которые отражали не объективные свойства оцениваемого предмета, понятия, а субъективно-значимые для респондента стороны предмета, понятия.
В маркетинговых исследованиях признанным инструментом исследования имиджа корпорации, торговой марки или товара являются денотативные шкалы, которые не всегда состоят только из прилагательных–антонимов, но представляют собой, как правило, словосочетания, фразы, которые выражают ожидания, характеристики товара, как негативные, так и положительные. Аналогичные товары разных компаний-производителей можно оценивать по шкале “стоит своих денег”, например, банки – по уровню надежности, выгодности и.т.п.
Для сохранения “духа” метода и фиксации все же аффективных элементов установки используется набор шкал (15–25 шкал). Результатом методики являются не напрямую рассчитанные средние значения объектов по каждой из шкал, а получаемые в ходе особой процедуры анализа латентные факторы, на основе которых и формируется семантическое пространство восприятия объектов и строится карта их взаиморасположения. Важно выбирать достаточное количество шкал и тестировать их на экспертах или проводить ассоциативный эксперимент на представителях целевой группы, чтобы избежать опасности субъективности исследователя при выборе шкал.
Шкалы СД не описывают реальность, а являются метафорическим выражением состояний и отношений субъекта (инструкция, которую получают респонденты, призывает: “ставя оценки, ориентируйтесь на собственные ощущения, а не знания”). В полученном пространстве аффективных значений фиксируется сближение понятий, на которые человек реагирует сходным образом, и разведение понятий, имеющих различный эмоциональный фон. Расстояние между понятиями выражается определенным числом, что в общем виде позволяет различать оценки: а) одного и того же понятия разными индивидами (или разными группами); б) разных понятий одним и тем же индивидом (или группой); в) одного понятия одним и тем же индивидом (или группой) в разное время.
Число выделяемых факторов соответствует структуре эмоционального восприятия данного класса объектов, так, например, при оценке банка могут выявиться только два фактора: надежность и выгодность, в то время как автомобиль может оцениваться по критериям “модности, стильности”, “престижа, статуса”, “цены”, “экономичности эксплуатации”, “сервисные сети послепродажного обслуживания” и т.п.
Процедура формирования методики семантического дифференциала в рамках конкретного исследовательского проекта состоит обычно из следующих этапов:
1) Формирование и тестирование списка прилагательных, утверждений, для описания тестируемых объектов (названий, концепций, видов упаковки, брендов и т.п.). От выбранных признаков зависит тот уровень осознанности, на котором респондент будет оценивать измеряемый объект. Делая упор на денотативные шкалы, мы расширяем семантическое пространство, увеличивая информацию об объектах и неизбежно теряя информацию о субъектах, что в маркетинговых исследованиях не так критично.
2) Математическая обработка полученной матрицы данных: объект – респондент – шкала. Обычно используется процедура факторного анализа, которая позволяет выявить латентные критерии оценивания, в которые складываются первоначальные шкалы. Важно отметить, что для получения значимых результатов достаточно относительно небольших выборок – 30–50 человек, в связи с тем, что единицей анализа является не респондент, а оценки, которые он выставляет объектам. Учитывая, что каждый из 30–50 респондентов оценивает 7–10 объектов по 15–25 шкалам, то общий объем выборки оказывается вполне достаточным для того, чтобы делать статистически значимые выводы.
3) Размещение в построенном семантическом пространстве оцениваемых объектов, анализ получившегося распределения. Оценка расстояния между тестируемыми объектами и идеальным объектом (например, идеальный йогурт, автомобиль, “я сам” и т.п.), для определения “положительных” полюсов факторов. Например, если мы получили фактор “модность, стильность, яркость” автомобиля, то важно понять являются ли высокие оценки нашей марки по этому фактору позитивом для целевой аудитории или нет. Быть может для них идеальный автомобиль – это надежный, консервативный “железный конь”, экономичный по расходу топлива и без особых причуд в дизайне.
Этап 1 Формирование и тестирование списка утверждений.
Инструментарий, используемый в методике семантического дифференциала, обычно состоит из таблицы следующего вида: по строкам размещаются шкалы, а в столбцах – оцениваемые объекты. Инструкция, предлагаемая респонденту, формулируется примерно следующим образом: “Оцените, пожалуйста, характеристики каждой из марок «…» по шкале от 0 до 5, где 0 – нет такого свойства, а 5 – свойство выражено максимально. В графе “идеальное …” запишите, какими свойствами должно обладать хорошее…, используя шкалу от 0 до 5, где 0 – такого свойства не должно быть, а 5 – свойство должно быть присуще товару в максимальной степени”.
Учитывая, что вполне достаточной выборкой для гомогенной группы респондентов в рамках данной методики является 30–50 человек, то часто сбор информации удобно проводить параллельно с фокус-групповым исследованием. Учитывая, что обычно выведение нового бренда, названия, упаковки сопровождается проведением серии фокус-групп, то в ходе 3–5 групп можно собрать 30–50 анкет. Такой объем выборки оказывается вполне достаточным для того, чтобы дополнить сознательную, рациональную информацию, предоставляемую респондентами, еще и оценками аффективных элементов установки, т.е. собрать внесознательные, эмоциональные, нерациональные данные, которые позволяет получить методика семантического дифференциала.
| Качества / марка | Марка 1 | Марка 2 | Марка 3 | Идеальное значение |
| Высокая репутация компании производителя | 5 | 4 | 1 | 5 |
| Нет защиты от подделки | 1 | 2 | 3 | 0 |
| Надежное | 4 | 2 | 0 | 4 |
| Оптимальное соотношение цены и качества | ... | |||
| Сложно найти |
Рисунок 4 - Пример таблицы семантического дифференциала для оценивания объектов
Этап 2. Математическая обработка результатов и их интерпретация
Методика СД позволяет достаточно четко с помощью простейших статистических характеристик произвести обработку результатов и интерпретировать их. В качестве таких характеристик предлагаются среднее значение измеряемой величины, среднее квадратическое отклонение, коэффициент корреляции. Первичная обработка результатов заключается в составлении статистического ряда измеряемой величины для каждого исследуемого объекта. Затем подсчитывается среднее статистическое значение измеряемой величины по выборке и мера единодушия оценок, выраженная средним квадратическим отклонением. После того как выявлены средние оценки каждого объекта по трем измеряемым показателям, интересно проследить их взаимозависимость. Таким образом, алгоритм математической обработки результатов СД следующий:
Шаг 1. Составление статистического ряда в виде таблицы.
| Хi | -3 | – 2 | – 1 | 0 | 1 | 2 | 3 |
| ni | n1 | n2 | n3 | n4 | n5 | n6 | n7 |
Xi – оценка определенного качества объекта по семибалльной шкале;
ni – частота значения Xi, т.е. сколько раз был поставлен балл Xi при оценке объекта по исследуемому параметру всеми респондентами в совокупности.
Шаг 2. Подсчет среднего значения величины.
Если в опросе участвовало К респондентов, то среднее значение величины вычисляется по формуле:
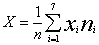 ,
,
где
n=М*K, так как исследуемое качество оценивается К респондентами в разработанном бланке М раз (в М парах антонимичных прилагательных). Среднее значение X служит показателем совокупного оценивания данного качества объекта всем классом, являясь при этом достаточно объективной характеристикой, так как позволяет нивелировать влияние субъективных факторов (например, предвзятость отдельных респондентов по отношению к данному объекту на момент опроса).
Шаг 3. Подсчет среднего квадратического отклонения.
Среднее квадратическое отклонение служит показателем меры рассеивания значений величины около ее среднего значения X, т.е. меры единодушия, сплоченности респондентов в оценке данного качества объекта. Среднее квадратическое отклонение вычисляется как корень квадратный из дисперсии σх=√Дх, где дисперсия Дх, в свою очередь, вычисляется по формуле:
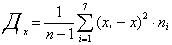
Описанные три шага математической обработки данных диагностики выявляют картину восприятия исследуемых объектов респондентами. Это позволяет наглядно представить результаты анализа.
Данные, полученные после вышеописанной обработки, могут быть сопоставлены между собой путем подсчета их корреляции. Этот этап обработки имеет целью установить, в какой степени отношение респондентов к объекту связано с его отдельными характеристиками.
Шаг 4. Расчет корреляции полученных оценок.
При определении коэффициента корреляции, во-первых, подсчитывается среднее значение оценок каждого из показателей для всех оцениваемых объектов. Допустим, респондентом оценивается n объектов. По активности 1-й объект был оценен средним значением Аj . Тогда средняя оценка показателя А всех объектов:

Средняя оценка показателя П:

Тогда коэффициент корреляции А и П rА,П:
 ,
,
где 
(ковариация); 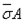 ,
,  – средние квадратические отклонения величин Aj и Oj от их средних значений, которые находятся так:
– средние квадратические отклонения величин Aj и Oj от их средних значений, которые находятся так:
 ;
; 
 ;
;  ;
;
В результате расчета корреляции оценок можно наглядно увидеть психологический механизм построения отношения оценок респондентов к исследуемым объектам.
Этап 3. Представление расположения тестируемых марок в семантическом пространстве.
После проведения этапа математической обработки можно выделить несколько основных факторов и представить расположение тестируемых марок в семантическом пространстве, образуемом выделенными латентными факторами.
Результаты в итоге оказываются вполне наглядными и довольно легко интерпретируемыми: из рисунка видно, что идеальный товар должен иметь высокое качество и приемлемую цену (для наглядности примера отобраны довольно очевидные свойства). По фактору качества наиболее близкими к идеальному продукту оказываются марки 1 и 2, а по фактору цены 4 и 5. Оценивая совокупность критериев можно сделать вывод о том, что наиболее близкой к идеалу является марка 1.
Аналогичным образом можно тестировать, например, варианты названий, выбирая названия, вызывающие наиболее позитивные эмоции, при этом, связанные с конкретным продуктом и вызывающие образ, ассоциацию с соответствующими ценными качествами.
Интересные результаты можно получить, сравнивая не конкурирующие между собой товары, но обладающие сходной основой, что делает возможным сравнение и помогает выявить новые позитивно оцениваемые качества товара, бренда и перенести их на новое товарное поле (изобретение на применение).
Например, оценка пластиковых карт вообще, для того, чтобы понять какие свойства топливных пластиковых карт нуждаются в развитии, и использование которых помогло бы в захвате рынка топливных карт.
Методика семантического дифференциала позволяет при исследовании бренда выявить эмоциональное отношение к нему (аффективный компонент установки), не отягощенное рационализирующими мотивами (когнитивным аспектом). Выявить то, что потенциальный потребитель чувствует по поводу бренда, т.е. прогнозировать его реальное поведение, а не слова о действиях.
Семантический дифференциал позволяет делать статистически значимые выводы на небольших выборках (достаточный материал можно собрать на 3–5 гомогенных фокус-группах) за счет того, что единицей анализа является не респондент, а оценка (в среднем каждый респондент оценивает по 7–10 объектов по 15–25 шкалам, т.е. выставляет 100-250 оценок).
Метод СД позволяет выявить структуру латентных факторов, критериев, на основе которых респонденты конструируют оценки различных брендов. Соответственно, с помощью метода СД можно построить карту размещения интересующих брендов в структуре факторов, получив при этом наглядный, относительно легко интерпретируемый результат исследования.
Использование в методике СД “идеального” объекта, наряду с тестируемыми брендами, позволяет определить желаемые направления развития, возможные угрозы бренду, наиболее значимые (хотя иногда и неосознаваемые потребителем) свойства товара.
Применение методики СД в маркетинговых исследованиях позволяет оценивать бренд и его элементы (название, упаковка, фирменный стиль и т.п.), получая в ходе относительно недорогого и немасштабного исследования статистически значимые оценки глубинных структур сознания потребителей.
1.7. Информационное обеспечение оценки имиджа методом семантического дифференциала
Информационное обеспечение - комплекс мер по обеспечению информационными ресурсами, включающий в себя механизмы поиска, получения, хранения, накопления, передачи, обработки информации; организация банков данных.
|
из
5.00
|
Обсуждение в статье: Суть метода семантического дифференциала |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы