 |
Главная |


Анализ главных компонентов алгоритмами самообучения нейронных сетей
|
из
5.00
|
Главной задачей в статистическом распознавании является выделение признаков (feature selection) или извлечение признаков (feature extraction). Под выделением признаков понимается процесс, в котором пространство данных (data space) преобразуется в пространство признаков (feature space), теоретически имеющее ту же размерность, что и исходное пространство. Однако обычно преобразования выполняются таким образом, чтобы пространство данных могло быть представлено сокращенным количеством "эффективных" признаков. Таким образом, остается только существенная часть информации, содержащейся в данных. Другими словами, множество данных подвергается сокращению размерности (dimensionality reduction). Для большей конкретизации предположим, что существует некоторый вектор х размерности т, который мы хотим передать с помощью i чисел, где i < т. Если мы просто обрежем вектор х, это приведет к тому, что среднеквадратическая ошибка будет равна сумме дисперсий элементов, "вырезанных" из вектора х. Поэтому возникает вопрос: "Существует ли такое обратимое линейное преобразование Т, для которого обрезание вектора Тх будет оптимальным в смысле среднеквадратической ошибки?" Естественно, при этом преобразование Т должно иметь свойство маленькой дисперсии своих отдельных компонентов. Анализ главных компонентов (в теорий информации он называется преобразование Карунена—Лоева (Karhunen-Loeve transformation)) максимизирует скорость уменьшения дисперсии и, таким образом, вероятность правильного выбора. В этой главе описываются алгоритмы обучения, основанные на принципах Хебба, которые осуществляют анализ главных компонентов интересующего вектора данных.
Пусть X — m-мерный случайный вектор, представляющий интересующую нас среду. Предполагается, что он имеет нулевое среднее значение
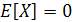 ,
,
гдеE — оператор статистического ожидания. Если X имеет ненулевое среднее, можно вычесть это значение еще до начала анализа. Пусть q—единичный вектор (unit vector) размерности т, на который проектируется вектор X. Эта проекция определяется как скалярное произведение векторов X и q:
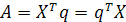 (1.3)
(1.3)
при ограничении
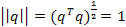 (1.4)
(1.4)
Проекция А представляет собой случайную переменную со средним значением и с дисперсией, связанными со статистикой случайного вектора X. В предположении, что случайный вектор X имеет нулевое среднее значение, среднее значение его проекции А также будет нулевым:
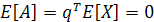
Таким образом, дисперсия А равна
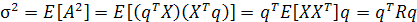 (1.5)
(1.5)
Матрица R размерности т х т является матрицей корреляции случайного вектора X. определяемой как ожидание произведения случайного вектора X самого на себя:
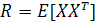 (1.6)
(1.6)
Матрица R является симметричной, т.е.
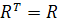 (1.7)
(1.7)
Из этого следует, что если а и b — произвольные векторы размерности т х 1, то
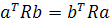 (1.8)
(1.8)
Из выражения (1.5) видно, что дисперсия  2 проекции А является функцией единичного вектора q. Таким образом, можно записать:
2 проекции А является функцией единичного вектора q. Таким образом, можно записать:
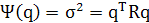 (1.9)
(1.9)
на основании чего ψ(q) можно представить как дисперсионный зонд (variance probe).
|
из
5.00
|
Обсуждение в статье: Анализ главных компонентов алгоритмами самообучения нейронных сетей |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы