 |
Главная |


Идея сингулярного разложения матрицы данных
|
из
5.00
|
Если  — матрица, составленная из векторов-строк центрированных данных, то выборочная ковариационная матрица
— матрица, составленная из векторов-строк центрированных данных, то выборочная ковариационная матрица
 и задача о спектральном разложении ковариационной матрицы
и задача о спектральном разложении ковариационной матрицы  превращается в задачу о сингулярном разложении матрицы данных X.
превращается в задачу о сингулярном разложении матрицы данных X.
Число σ³0 называется сингулярным числом матрицы  тогда и только тогда, когда существуют правый и левый сингулярные векторы: такие
тогда и только тогда, когда существуют правый и левый сингулярные векторы: такие  -мерный вектор-строка
-мерный вектор-строка  и
и  -мерный вектор-столбец
-мерный вектор-столбец  (оба единичной длины), что выполнено два равенства:
(оба единичной длины), что выполнено два равенства:
 ;
; 
Пусть 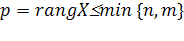 — ранг матрицы данных. Сингулярное разложение матрицы данных X— это её представление в виде
— ранг матрицы данных. Сингулярное разложение матрицы данных X— это её представление в виде

где  — сингулярное число,
— сингулярное число,  — соответствующий правый сингулярный вектор-столбец, а
— соответствующий правый сингулярный вектор-столбец, а  — соответствующий левый сингулярный вектор-строка (
— соответствующий левый сингулярный вектор-строка ( 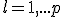 ). Правые сингулярные векторы-столбцы
). Правые сингулярные векторы-столбцы  , участвующие в этом разложении, являются векторами главных компонент и собственными векторами эмпирической ковариационной матрицы
, участвующие в этом разложении, являются векторами главных компонент и собственными векторами эмпирической ковариационной матрицы  , отвечающими положительным собственным числам
, отвечающими положительным собственным числам  .
.
Хотя формально задачи сингулярного разложения матрицы данных и спектрального разложения ковариационной матрицы совпадают, алгоритмы вычисления сингулярного разложения напрямую, без вычисления спектра ковариационной матрицы, более эффективны и устойчивы. Это следует из того, что задача сингулярного разложения матрицы лучше обусловлена, чем задача разложения матрицы  : для ненулевых собственных и сингулярных чисел
: для ненулевых собственных и сингулярных чисел

Простой итерационный алгоритм сингулярного разложения
Основная процедура — поиск наилучшего приближения произвольной m x n матрицы 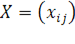 матрицей вида
матрицей вида 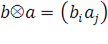 (где b— m-мерный вектор, а a— n-мерный вектор) методом наименьших квадратов:
(где b— m-мерный вектор, а a— n-мерный вектор) методом наименьших квадратов:

Решение этой задачи дается последовательными итерациями по явным формулам. При фиксированном векторе  значения
значения  , доставляющие минимум форме F(b,a), однозначно и явно определяются из равенств
, доставляющие минимум форме F(b,a), однозначно и явно определяются из равенств

Аналогично, при фиксированном векторе  определяются значения:
определяются значения:
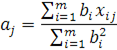
B качестве начального приближения вектора  возьмем случайный вектор единичной длины, вычисляем вектор b, далее для этого вектора
возьмем случайный вектор единичной длины, вычисляем вектор b, далее для этого вектора  вычисляем вектор и т. д. Каждый шаг уменьшает значение F(b,a). В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала F(b,a)за шаг итерации (∆F/F) или малость самого значения F.
вычисляем вектор и т. д. Каждый шаг уменьшает значение F(b,a). В качестве критерия остановки используется малость относительного уменьшения значения минимизируемого функционала F(b,a)за шаг итерации (∆F/F) или малость самого значения F.
В результате для матрицы X=(  )получили наилучшее приближение матрицей
)получили наилучшее приближение матрицей  вида
вида  (здесь верхним индексом обозначен номер итерации). Далее, из матрицы
(здесь верхним индексом обозначен номер итерации). Далее, из матрицы  вычитаем полученную матрицу
вычитаем полученную матрицу  , и для полученной матрицы уклонений
, и для полученной матрицы уклонений 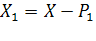 вновь ищем наилучшее приближение
вновь ищем наилучшее приближение  этого же вида и т. д., пока, например, норма
этого же вида и т. д., пока, например, норма  не станет достаточно малой. В результате получили итерационную процедуру разложения матрицы X в виде суммы матриц ранга 1, то есть
не станет достаточно малой. В результате получили итерационную процедуру разложения матрицы X в виде суммы матриц ранга 1, то есть 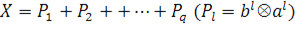 . Полагаем
. Полагаем  и нормируем векторы
и нормируем векторы  :
:  В результате получена аппроксимация сингулярных чисел
В результате получена аппроксимация сингулярных чисел  и сингулярных векторов (правых —
и сингулярных векторов (правых —  и левых —
и левых —  ).
).
К достоинствам этого алгоритма относится его исключительная простота и возможность почти без изменений перенести его на данные с пробелами, а также взвешенные данные.
Существуют различные модификации базового алгоритма, улучшающие точность и устойчивость. Например, векторы главных компонент  при разных l должны быть ортогональны «по построению», однако при большом числе итерации (большая размерность, много компонент) малые отклонения от ортогональности накапливаются и может потребоваться специальная коррекция
при разных l должны быть ортогональны «по построению», однако при большом числе итерации (большая размерность, много компонент) малые отклонения от ортогональности накапливаются и может потребоваться специальная коррекция  на каждом шаге, обеспечивающая его ортогональность ранее найденным главным компонентам.
на каждом шаге, обеспечивающая его ортогональность ранее найденным главным компонентам.
Для квадратных симметричных положительно определённых матриц описанный алгоритм превращается в метод прямых итераций для поиска собственных векторов.
Линейный МНК
Задача аппроксимации линейным МНК в матричной форме записывается, как

Иногда к задаче добавляются ограничения:

Здесь c обозначает искомый вектор коэффициентов. Столбцы матрицы F соответствуют базисным функциям (всего M столбцов), строки - экспериментальным точкам (всего N строк), Fij содержит значение j-ой базисной функции в i-ой точке набора данных. Вектор y содержит значения аппроксимируемой функции в точках, соответствующих строкам матрицы F. Матрица W является диагональной матрицей весовых коэффициентов, элементы которой соответствуют важности той или иной точки. Матрица C задает дополнительные ограничения, которым должна удовлетворять аппроксимируемая функция - минимум ошибки ищется среди функций, точно удовлетворяющих заданным ограничениям. В такой формулировке задача сводится к решению системы линейных уравнений. Полученная система линейных уравнений, как правило, является переопределенной - число уравнений намного больше числа неизвестных. Для решения используется основанный на QR-разложении солвер. Сначала матрица A представляется в виде произведения прямоугольной ортогональной матрицы Q и квадратной верхнетреугольной матрицы R. Затем решается система уравнений Rx = Q Tb. Если матрица R вырождена, алгоритм использует SVD-разложение, которое позволяет добиться решения независимо от свойств матрицы коэффициентов. Трудоемкость решения такой задачи составляет O(N·M 2).
Модуль lsfit содержит четыре подпрограммы для линейной аппроксимации: LSFitLinear (простейшая задача - нет ограничений, W - единичная матрица), LSFitLinearW (взвешенная аппроксимация без ограничений), LSFitLinearC (аппроксимация с ограничениями, без весовых коэффициентов) и LSFitLinearWC (аппроксимация с индивидуальными весовыми коэффициентами и ограничениями).
|
из
5.00
|
Обсуждение в статье: Идея сингулярного разложения матрицы данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы