 |
Главная |


Анализ таблиц сопряжённости
|
из
5.00
|
Рассмотрим два номинальных признака Х и Y. Признак Х может принимать значения Х1, X2,…,Xr, а признак Y принимает значения Y1, Y2,…,Ys.


Будем предполагать, что выборка сформирована методом перекрестного отбора, то есть из генеральной совокупности случайным образом отобрано n объектов, и для каждого из них зафиксированы значения признаков X и Y.
Выдвинем гипотезы:

где pij - вероятность того, что Х=Хi и Y=Yj; pi* - вероятность того, что Х=Хi; pj* - вероятность того, что Y=Yj;
Для проверки гипотезы по критерию Пирсона используется статистика
 .
.
При справедливости Н0 эта статистика имеет распределение χ2 с числом степеней свободы ν=(r-1)(s-1). Так как r=s=2, то ν=1.
Меры связи признаков Х и Y таблицы сопряженности 2*2:
. Фи-коэффициент

. Коэффициент сопряженности Пирсона

. Коэффициент контингенции

. Тау-коэффициент Гудмана и Краскала

5. Коэффициент ассоциации (коэффициент Юла)

При n→∞  ,
, 
Доверительный интервал с надежностью γ для коэффициента ассоциации:


. Коэффициент коллигации

. Отношение перекрестных произведений

Меры связи признаков Х и Y таблицы сопряженности r*s:
) Меры связи, основанные на статистике «Хи-квадрат»
. Фи-коэффициент

. Коэффициент Чупрова

. Коэффициент Крамера

. Коэффициент сопряженности Пирсона

При n→∞ последние три коэффициента согласно закону больших чисел подчиняются нормальному закону распределения.

где

Доверительные интервалы с доверительной вероятностью γ для генеральных коэффициентов сопряженности:

) Меры связи Гудмана и Краскала λа, λв, λ.
λв - асимметричный коэффициент, изучает зависимость Y от Х.
 ,
,
где nimax - максимальная частота i-й строки; n*max - максимальный элемент итоговой строки.
Значение коэффициента λв показывает, что вероятность ошибки предсказания признака Y при известной информации о принадлежности наблюдения к классу признака Х снизится на λв*100% по сравнению с ситуацией, когда такой информации нет.
Интервальная оценка 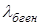 - генеральной оценки коэффициента λв;
- генеральной оценки коэффициента λв;
 - сумма только таких максимальных элементов строк nimax, для которых значения i обеспечивают попадание как раз в тот столбец, где находится наибольший итог.
- сумма только таких максимальных элементов строк nimax, для которых значения i обеспечивают попадание как раз в тот столбец, где находится наибольший итог.


λа эквивалентен λв с учетом перемены строк и столбцов между собой, является асимметричным коэффициентом, определяет степень зависимости Х от Y.
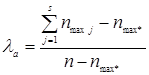 ,
,
где nmaxj - максимальная частота j-го столбца; nmax* - максимальный элемент итогового столбца.
Коэффициент λа показывает, что улучшение средней величины относительного изменения вероятности ошибки предсказания категории признака, располагающегося по столбцам таблицы, при изменении категории признака, располагающегося по строкам, составит λа *100%.
Для получения интервальных оценок воспользуемся статистикой, имеющей приближенное единичное нормальное распределение:
 - генеральная оценка коэффициента λв;
- генеральная оценка коэффициента λв;  - сумма только таких максимальных элементов столбцов nmaxj, для которых значения j обеспечивают попадание в ту строку, где находится наибольший итог.
- сумма только таких максимальных элементов столбцов nmaxj, для которых значения j обеспечивают попадание в ту строку, где находится наибольший итог.

Если при анализе таблиц сопряженности не интересует последовательность расположения классов по признакам, то есть не важно, зависит Х от Y или наоборот, то используется коэффициент λ. Этот коэффициент находит усредненную величину прогноза между переменными.

) Меры связи Гудмана и Краскала τа, τв, τ.
При построении коэффициентов λ возникают трудности, связанные с обращением коэффициентов λ в ноль. Коэффициенты τа, τв, τ лишены этих недостатков. τ-меры предсказывают различные категории в пропорции, которая имеет место для их наблюдаемых итогов.
Коэффициент τв сравнивает случайный, пропорциональный прогноз признака Y со вторым признаком Х и рассчитывает условное, пропорциональное предсказание класса Y, при предположении, что имеется информация о принадлежности объекта к одному из классов признака Х. Этот коэффициент связи является асимметричным.

При прогнозировании категорий признака Х в зависимости от Y, то есть строк таблицы сопряженности в зависимости от столбцов, применяется коэффициент τа:

Данная мера показывает, что неправильный прогноз категории признака Х для случайно взятого объекта при условном пропорциональном прогнозировании по сравнению с безусловным пропорциональном прогнозом уменьшится на  *100%.
*100%.
Для получения симметричной меры τ случайно выбранный объект с вероятностью ½ прогнозируется по признаку Х или по признаку Y. Этот симметричный коэффициент получается в виде усредненных коэффициентов τа, τв:

Логлинейный анализ
Логлинейная модель называется насыщенной, если она включает влияние всех факторов и всех взаимодействий факторов. Насыщенная логлинейная модель для трёхмерной таблицы сопряжённости размерности (r x s x t) имеет вид  , где для насыщенной модели
, где для насыщенной модели  .
.  - среднее значение логарифма частоты (общий эффект),
- среднее значение логарифма частоты (общий эффект),  - влияние признака Х,
- влияние признака Х,  - влияние признака Y,
- влияние признака Y, 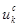 - влияние признака Z,
- влияние признака Z,  - влияние взаимодействия признаков X и Y,
- влияние взаимодействия признаков X и Y,  - влияние взаимодействия всех трёх признаков.
- влияние взаимодействия всех трёх признаков.
Ограничения на параметры насыщенной логлинейной модели имеют вид
 .
.
Для трёхмерной таблицы сопряжённости можно построить 18 иерархических ненасыщенных моделей. Логлинейная модель называется иерархической, если выполняется правило: если в модель включён параметр, зависящий от множества p факторов, то в модель должны быть включены и все параметры, зависящие от любого подмножества факторов из множества p. Пример модели, не являющейся иерархической:  .
.
Выполнение задания 1
Рассчитаем теоретические частоты в таблице сопряжённости:
Таблица 1 - теоретические частоты в таблице сопряжённости
| Удовл | Не удовл | ||
| Мужчины | 468,5649 | 72,43515 | 541 |
| Женщины | 359,4351 | 55,56485 | 415 |
| 828 | 128 | 956 | |
Проверим гипотезу  (о независимости значения признака «Удовлетворённость качеством» от пола покупателя), используя критерий «Хи-квадрат».
(о независимости значения признака «Удовлетворённость качеством» от пола покупателя), используя критерий «Хи-квадрат».  ,
,  .
.  , следовательно, гипотезу о независимости принимаем на уровне значимости 0,05.
, следовательно, гипотезу о независимости принимаем на уровне значимости 0,05.
Вычислим оценки коэффициентов связи: 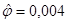 ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
, 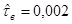 ,
,  .
.
По малым значениям коэффициентов связи мы можем судить о независимости признаков.
Выполнение задания 2
Рассчитаем теоретические частоты в таблице сопряжённости:
Таблица 2 - теоретические частоты в таблице сопряжённости.
| Знакомы | Не знак. | Уклонилсь | ||
| Участвуют | 446,04234 | 393,84589 | 94,1117697 | 934 |
| Не участвуют | 64,948349 | 57,34801 | 13,703641 | 136 |
| Затруднились | 53,009314 | 46,806097 | 11,1845893 | 111 |
| 564 | 498 | 119 | 1181 |
Проверим гипотезу  (о независимости значения признака «Знакомы с программами депутатов» от готовности участия в выборах), используя критерий «Хи-квадрат».
(о независимости значения признака «Знакомы с программами депутатов» от готовности участия в выборах), используя критерий «Хи-квадрат».  ,
,  .
. 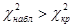 , значит, гипотезу о независимости отвергаем на уровне значимости 0,05.
, значит, гипотезу о независимости отвергаем на уровне значимости 0,05.
Вычислим оценки коэффициентов связи: 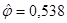 ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  ,
,  .
.
По значениям коэффициентов связи делаем вывод - существует слабая связь между значениями признаков «Знакомы с программами депутатов» и «Готовность к участию в выборах». Исходя из значения коэффициентов  и
и  , можем сделать вывод о наличии связи средней силы.
, можем сделать вывод о наличии связи средней силы.
Построим доверительные интервалы для коэффициентов связи:  ,
,  ,
,  ,
,  ,
,  .
.
Выполнение задания 3
Насыщенная модель имеет вид

Рассчитаем параметры для насыщенной модели и проверим их значимость:
| Коэф-ты | Нормир. | Значим? | |
| u0 | 4,332103 | 83,79929 | Значим |
| u1(a) | -0,0162 | -0,31341 | Незначим |
| u1(b) | 0,485375 | 9,388996 | Значим |
| u1(с) | 0,944783 | 18,27569 | Значим |
| u2(a) | 0,016202 | 0,313415 | Незначим |
| u2(b) | -0,48538 | -9,389 | Значим |
| u2(с) | -0,94478 | -18,2757 | Значим |
| u11(ab) | 0,063678 | 1,23178 | Незначим |
| u11(aс) | -0,055 | -1,06399 | Незначим |
| u11(bс) | 0,088763 | 1,717014 | Незначим |
| u12(ab) | -0,06368 | -1,23178 | Незначим |
| u12(aс) | 0,055004 | 1,063994 | Незначим |
| u12(bс) | -0,08876 | -1,71701 | Незначим |
| u21(ab) | -0,06368 | -1,23178 | Незначим |
| u21(aс) | 0,055004 | 1,063994 | Незначим |
| u21(bc) | -0,06368 | -1,23178 | Незначим |
| u22(aс) | 0,063678 | 1,23178 | Незначим |
| u22(ab) | -0,055 | -1,06399 | Незначим |
| u22(bс) | 0,088763 | 1,717014 | Незначим |
| u111(abc) | 0,125212 | 2,422067 | Значим |
| u112(abc) | -0,12521 | -2,42207 | Значим |
| u121(abc) | -0,12521 | -2,42207 | Значим |
| u122(abc) | 0,125212 | 2,422067 | Значим |
| u211(abc) | -0,12521 | -2,42207 | Значим |
| u212(abc) | 0,125212 | 2,422067 | Значим |
| u221(abc) | 0,125212 | 2,422067 | Значим |
| u222(abc) | -0,12521 | -2,42207 | Значим |
Из таблицы следует, что значимое влияние на исследуемые показатели оказывают факторы «Удовлетворённость сроками» и «Удовлетворённость качеством», а также взаимодействие всех трёх факторов (включая «Клиенты фирмы»).

Рисунок 1 - проверка модели AB/BC в программном пакете Statistica
Среди ненасыщенных иерархических моделей наиболее адекватной является модель AB/BC. Она имеет вид  Рассчитаем теоретические частоты и оценки коэффициентов в модели AB/BC.
Рассчитаем теоретические частоты и оценки коэффициентов в модели AB/BC.
Теоретические частоты в трёхмерной таблице сопряжённости:
| Удовл. сроками | Удовл. кач-вом | ||
| Да | Нет | ||
| Орг-ии | Да | 385,53299 | 48,46701 |
| Нет | 91,029851 | 15,97015 | |
| Частные лица | Да | 314,46701 | 39,53299 |
| Нет | 136,97015 | 24,02985 | |
Получим 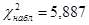 ,
,  .
.  , следовательно, данная ненасыщенная модель адекватна исходным данным.
, следовательно, данная ненасыщенная модель адекватна исходным данным.
Рассчитаем параметры для данной ненасыщенной модели:
| Коэф-ты | Нормир. | Значим? | |
| u0 | 4,330562 | 83,00143 | Значим |
| u11(ab) | 0,153081 | 2,934013 | Значим |
| u11(bс) | 0,083319 | 1,596935 | Незначим |
| u12(ab) | -0,15308 | -2,93401 | Значим |
| u12(bс) | -0,08332 | -1,59693 | Незначим |
| u21(ab) | -0,15308 | -2,93401 | Значим |
| u21(bс) | -0,08332 | -1,59693 | Незначим |
| u22(ab) | 0,153081 | -2,93401 | Значим |
| u22(bс) | 0,083319 | 2,934013 | Значим |
Из таблицы следует, что значимое влияние на результативный показатель оказывает взаимодействие факторов «Клиенты фирмы» и «Удовлетворённость сроками».
|
из
5.00
|
Обсуждение в статье: Анализ таблиц сопряжённости |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы