 |
Главная |


Импорт и экспорт данных
|
из
5.00
|
Часто может возникнуть ситуация, когда данные для последующей обработки в SPSS были заранее подготовлены в других программах или, напротив, содержимое таблицы файла данных SPSS пользователю по какой-то причине надо разместить в документе, подготовленном в другой программе, например в тексте статьи, созданной в Word. Как поступать в этих случаях.
Случай первый – импорт.
Импорт в программу наиболее удобно осуществляется через буфер обмена (стандартным набором действий «копировать-вставить»). Однако следует помнить правила:
- содержимое выделенных ячеек может быть скопировано непосредственно;
- название (имена) переменных должны быть составлены (там, где документ создавался) латинскими буквами, и этих букв в названии должно быть не более восьми. В противном случае SPSS не дает гарантии, что имена переменных отобразятся корректно. Гораздо «спокойнее» переносить через буфер обмена только содержимое ячеек, а имена переменным присваивать уже в SPSS;
- Документ, из которого производится импорт, может быть практически любым – рабочей книгой Excel, документом Word, документом, созданным в программе «Блокнот», и даже документом формата TXT. В двух последних случаях, а так же в случае, если документ Word оформлен не как таблица, а данные его расположены в строку и по столбцам, нужно соблюдать правило: последующее значение отделять от предыдущего не пробелом, а клавишей табуляции, переход на новую строку осуществлять клавишей ввода («Enter»). Если же исходный документ – таблица, созданная в Excel или Word, - выделенная таблица может переноситься непосредственно, и SPSS корректно отобразит ее содержимое.
Случай второй – экспорт.
Экспорт данных, созданных в SPSS, так же возможен, и производится через буфер обмена. Однако при этом может произойти потеря части информации. Этой потерянной информацией окажутся так называемые «метки переменных» и «метки значений» - носящие характер напоминающих подсказок. (Речь о них пойдет ниже - при описании процедуры задания свойств переменной.)
В SPSS существуют так называемые «файлы вывода» - в них в относительно удобной для восприятия форме каждый раз представляются результаты обработки данных посредством какой-либо процедуры. Информация из этих файлов тоже может быть перенесена в другие программы через буфер обмена, причем как полностью, так и по частям, с помощью выделения отдельных строк текста, таблиц или ячеек таблицы.
Вид окна ввода данных и окна задания свойств переменной, переход между окнами.

Рисунок 24.

Рисунок 25.
Интерфейс программы SPSS создан таким образом, что в нем имеется два главных типа окон – окно ввода данных и окно задания свойств переменной. Переход между окнами осуществляется так, как показано на рисунке 24 – путем нажатия на соответствующую кнопку, обе из которых расположены в левом нижнем углу экрана. (Того же самого результата можно достичь двойным щелчком по какому-либо из номеров строк таблицы.)
Нажмем на кнопку «Вид переменной». Теперь перед нами окно, очень похожее на предыдущее и, действительно, визуально очень мало от него отличимое. Большинство ошибок пользователей-новичков совершается именно из-за того, что они полагают, будто работают в одном окне, тогда как, на самом деле, находятся в другом. Отличия окон состоят в том, что в строке, где раньше располагались сокращения «Var – Var – Var…» - то есть будущие имена переменных, теперь находятся «таинственные» слова, содержание которых мы раскроем в следующем пункте этого раздела.
Итак, для чего же нужны два вида окон?
Как мы помним, случайная дискретная величина, исследованием которой мы, собственно, и занимаемся, а в терминологии данной программы – ПЕРЕМЕННАЯ, обладает рядом специфических свойств. Окно переменной служит для удобства наделения каждой переменной такими свойствами. «Таинственные» слова в верхней строке – названия этих свойств. Присваивая переменной те или иные свойства, мы тем самым полностью ее характеризуем, выписываем ей своеобразное «удостоверение личности», по которому она теперь имеет законное право на существование.
7. Назначение кнопок и содержание раскрывающихся списков окна задания свойств переменной.
Если окно данных было устроено так, что переменные располагались в нем по столбцам, а их значения – по строкам, то окно переменной «переворачивает» картину под прямым углом, и теперь все новые переменные, которые пользователь будет вводить и описывать, станут располагаться в строку. Первая переменная – первая строка сверху, вторая переменная – вторая строка, и т.д.
Дадим характеристику содержания колонок этого окна:
(1) Name. Здесь вводится имя переменной, и после оно будет отображаться так же и в шапке переменной окна ввода данных. Имя переменной, как уже говорилось, предпочтительнее задавать латинскими буквами, даже если программа русифицирована. Существует возможность удлинить имя – задать ширину ячейки более 8 символов (см. пункты Width, Decimals и Columns).
(2) Type / Тип. Здесь пользователю необходимо указать из списка всплывающего окна тип данной переменной (рисунок 26).
Программа SPSS различает несколько типов переменных. По умолчанию, каждая новая переменная, если не менять ее тип, рассматривается как Численная (Numeric). Этот тип переменной наиболее общий, в нем могут производиться практически любые статистические операции. Мы будем использовать его в тех случаях, когда значения переменной будут числами, например: показатель IQ; время в секундах, затраченное на решение задачи, и т.п.
Из прочих типов данных следует знать еще два:
String / Строковый. (Слово «строковый» следует понимать как «текстовый»). Переменные этого типа содержат текст не только в названии шапки, но и в ячейках. Такими переменными могут быть, например, списки испытуемых, где в строках вместо чисел стоят имена и фамилии. Очевидно, что переменные этого типа уже не могут быть подвергнуты никакой статистической обработке, а нужны в качестве ремарок, для наглядности. Если бы такие переменные не были предусмотрены программой, каждому испытуемому пришлось бы заранее присваивать порядковый номер или код.
Date / Дата. (В буквальном (date), а не в программистском (data) смысле – даты календарные). Переменные этого типа используются для работы с единицами времени. Этот тип удобен, например, при анализе временных серий, при построении прогнозов и т.п. Способ записи даты выбирается из предложенного списка, например, «день-месяц-год».
Важно: в тех случаях, когда время измерено «абсолютно» и значения будут сопоставляться между собой (т.е. представляют собой интервальную шкалу или шкалу отношений), нет необходимости выбирать этот тип переменной – в гораздо большей степени сюда подойдет числовой тип. Пример: время решения задачи разными испытуемыми, измеренное в секундах.

Рисунок 26.
(3) и (4). Width, Decimals. Эти столбцы регулируют количество знаков до и после запятой – соответственно. (Рисунок 27).

Рисунок 27.
Выбор числа знаков в обоих столбцах совершенно одинаков и осуществляется путем щелчка по полю соответствующей ячейки, а затем – нажатием на появившиеся стрелки-треугольники. По умолчанию, любая численная переменная будет отображаться с восьмью знаками до запятой и двумя десятичными знаками (после запятой). Часто бывает, что для наглядности полезно убрать десятичные знаки, если ваша экспериментальная величина все равно выражается целым числом (например, выбранное количество альтернатив из веера ответов анкеты). Впрочем, наличие или отсутствие десятичных знаков не влияет на точность работы программы. Следует знать, что если ваше число, напротив, имеет много разрядов после запятой, то это не означает, что вы обязаны менять значение «Decimals». Даже если сохранится режим «по умолчанию» (два десятичных знака), машина все равно точно запомнит ваше число и корректно произведет все расчеты (хотя и отобразит на экране только два знака после запятой).
Сказанное также относится и к переменным типа String / текстовым, кроме, разумеется, десятичных знаков. В этом случае столбец Width задает длину текста в ячейках этой переменной.
(5) и (6). Label и Values. Здесь можно вставить текстовый комментарий к переменной, носящий характер напоминающей подсказки. После наведения курсора на шапку переменной возникнет всплывающая подсказка с введенным текстом. Для переменной длина его не более 256 символов, для конкретного значения – не более 60 символов. Например, можно указать, что какое-то конкретное значение является средним, или получено в результате повторного тестирования, и т.п. Снабжать метками значения, как правило, имеет смысл тогда, когда вариантов значений не слишком много. Присвоение меток переменным и конкретным значениям – не обязательная процедура. Она служит для облегчения вспоминания содержания Вашего файла данных, и полезна, если с файлом могут работать несколько пользователей.
(7) Missing / Пропущенные значения. В этом столбце, после обычного щелчка по нужной ячейке и появления маленькой кнопки с изображенным на ней многоточием, после щелчка по этому многоточию, открывается окно, предоставляющее пользователю возможность указать пропущенные значения (рисунок 28).

Рисунок 28.
Кратко напомним содержание этого понятия.
Предположим, в результате некоего эксперимента исследователь получил несколько анкет, в которых респондент по каким-то причинам не дал ответов на часть вопросов. Последующими действиями экспериментатора должны быть следующие: занести содержимое всех анкет в файл данных SPSS, то есть создать соответствующие анкетным вопросам переменные и снабдить их эмпирическими значениями. Предположим, исследователь выдвинул несколько гипотез. Для проверки одних из них данных достаточно (пусть на соответствующие вопросы ответили 100% респондентов), а для проверки других данных не хватает (есть те, кто эти вопросы пропустил). Ясно, что часть гипотез можно теперь проверить, используя 100% анкет – это будут те вопросы, на которые все добросовестно ответили. Но как быть там, где есть пропущенные вопросы? В этом случае данные таких респондентов вовсе не включаются в обработку, т.е. строки (кейсы) этих лиц или конкретные ячейки таблицы исключаются из рассмотрения.
Часто допускается ошибка, состоящая в том, что пропущенному значению присваивают величину «ноль». Но ноль рассматривается процессором как равноправное число, и этот факт может внести в расчеты существенные искажения. К тому же ((2) стр. 26) в некоторых методиках действительно существует вариант ответа, равный нулю.
Опция Missing позволяет указывать программе значения, которые в данном случае следует считать пропущенными, хотя для других статистических процедур они могут быть вполне пригодны.
По умолчанию (рисунок 28) программа считает, что пропущенных значений нет. Если это действительно так, эту опцию можно вовсе не задействовать. Как видно из рисунка 29, пропущенные значения можно задать следующими способами:
- три конкретных значения, заданных вручную;
- интервал;
- интервал + одно конкретное значение.
(В некоторых случаях (в зависимости от характера переменной) часть этих возможностей не может быть использована (соответствующие окна пригашены и не активируются)).
Если пользователь не указан никаких пропущенных значений, то программа воспринимает в этом качестве только содержимое незаполненных ячеек (т.н. System Missing) – то есть значения, пропущенные в буквальном смысле.
Хитрость. Это обстоятельство может быть использовано практически: иногда проще временно удалить одно или несколько значений, предварительно запомнив их, а после выполнения статистической операции опять внести их в ячейки.
(8) Columns. Эта опция позволяет менять ширину колонки для переменной (сколько знаков будет видно в ячейке). Она особенно удобна для переменных, заданных в качестве текстовых (String).
(9). Align / Выравнивание. Декоративная функция, позволяющая по выбору пользователя располагать данные по левому/ правому краю ячейки или в ее середине. На содержательную сторону дела она влияния не оказывает.
(10) Measure. Одна из важнейших опций, позволяющая задавать тип измерительной шкалы (рисунок 29).
Здесь:
- Scale – шкала отношений;
- Ordinal – порядковая (ранговая) шкала;
- Nominal – номинальная шкала.
По умолчанию, шкала устанавливается как шкала отношений. Очевидно, что переменную типа String, содержащую текстовые сведения, следует наделять свойствами номинальной шкалы. Еще одним примером необходимости задания номинального типа шкалы может послужить случай, когда переменная является вспомогательной, введенной для того, чтобы делить выборку по какому-либо признаку, и содержащая только, скажем, значения, равные единице или двойке. Единица тогда будет означать присутствие какого-либо признака, а двойка – его отсутствие. (Подробнее – в упражнении по вычислению критерия Манна-Уитни.)
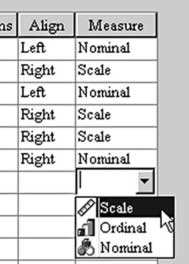
Рисунок 29.
|
из
5.00
|
Обсуждение в статье: Импорт и экспорт данных |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы