 |
Главная |


Статистическое кодирование: коды переменной длины, коды Шеннона-Фана и Хаффмена.
|
из
5.00
|
Первое правило построения кодов с переменной длиной вполне очевидно. Короткие коды следует присваивать часто встречающимся символам, а длинные редко встречающимся. Однако есть другая проблема. Эти коды надо назначать так, чтобы их было возможно декодировать однозначно, а не двусмысленно. L=2^b, b-исходная разрядность
Рассмотрим четыре символа 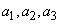 и
и  . Если они появляются в последовательности данных с равной вероятностью (
. Если они появляются в последовательности данных с равной вероятностью ( 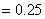 каждая), то мы им просто присвоим четыре двухбитовых кода 00, 01, 10 и 11. Все вероятности равны, и поэтому коды переменной длины не сожмут эти данные. Для каждого символа с коротким кодом найдется символ с длинным кодом и среднее число битов на символ будет не меньше 2. Избыточность данных с равновероятными символами равна нулю, и строку таких символов невозможно сжать с помощью кодов переменной длины (или любым иным методом).
каждая), то мы им просто присвоим четыре двухбитовых кода 00, 01, 10 и 11. Все вероятности равны, и поэтому коды переменной длины не сожмут эти данные. Для каждого символа с коротким кодом найдется символ с длинным кодом и среднее число битов на символ будет не меньше 2. Избыточность данных с равновероятными символами равна нулю, и строку таких символов невозможно сжать с помощью кодов переменной длины (или любым иным методом).
Предположим теперь, что эти четыре символа появляются с разными вероятностями, то есть  появляется в строке данных в среднем почти в половине случаев,
появляется в строке данных в среднем почти в половине случаев,  и
и  имеют равные вероятности, а возникает крайне редко. В этом случае имеется избыточность, которую можно удалить с помощью переменных кодов и сжать данные так, что потребуется меньше 2 бит на символ.
имеют равные вероятности, а возникает крайне редко. В этом случае имеется избыточность, которую можно удалить с помощью переменных кодов и сжать данные так, что потребуется меньше 2 бит на символ.
Значит, выбирая множество кодов переменной длины, необходимо соблюдать два принципа: (1) следует назначать более короткие коды чаще встречающимся символам, и (2) коды должны удовлетворять свойству префикса. Следуя эти принципам, можно построить короткие, однозначно декодируемые коды, но не обязательно наилучшие (то есть, самые короткие) коды. В дополнение к этим принципам необходим алгоритм, который всегда порождает множество самых коротких кодов (которые в среднем имеют наименьшую длину). Исходными данными этого алгоритма должны быть частоты (или вероятности) символов алфавита. К счастью, такой простой алгоритм существует. Он был придуман Давидом Хаффманом и называется его именем.
Код Хаффмана
Метод Хаффмана является простым и эффективным, однако, как было замечено в § 1.4, он порождает наилучшие коды переменной длины (коды, у которых средняя длина равна энтропии алфавита) только когда вероятности символов алфавита являются степенями числа 2, то есть равны 1/2, 1/4, 1/8 и т.п. Это связано с тем, что метод Хаффмана присваивает каждому символу алфавита код с целым числом битов. Теория информации предсказывает, что при вероятности символа, скажем, 0.4, ему в идеале следует присвоить код длины 1.32 бита, поскольку . А метод Хаффмана присвоит этому символу код длины 1 или 2 бита.
Предположим, у нас есть строка «beep boop beer!», для которой, в её текущем виде, на каждый знак тратится по одному байту. Это означает, что вся строка целиком занимает 15*8 = 120 бит памяти. После кодирования строка займёт 40 бит
Чтобы получить код для каждого символа на основе его частотности, нам надо построить бинарное дерево, такое, что каждый лист этого дерева будет содержать символ (печатный знак из строки). Дерево будет строиться от листьев к корню, в том смысле, что символы с меньшей частотой будут дальше от корня, чем символы с большей.

После вычисления частот мы создадим узлы бинарного дерева для каждого знака и добавим их в очередь, используя частоту в качестве приоритета:

Теперь мы достаём два первых элемента из очереди и связываем их, создавая новый узел дерева, в котором они оба будут потомками, а приоритет нового узла будет равен сумме их приоритетов. После этого мы добавим получившийся новый узел обратно в очередь.

Повторим те же шаги и получим последовательно:



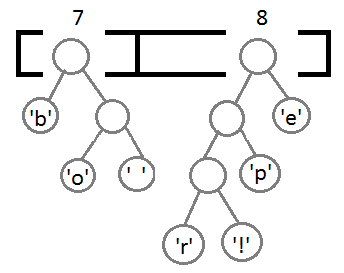
Ну и после того, как мы свяжем два последних элемента, получится итоговое дерево:

Теперь, чтобы получить код для каждого символа, надо просто пройтись по дереву, и для каждого перехода добавлять 0, если мы идём влево, и 1 — если направо:


Чтобы расшифровать закодированную строку, нам надо, соответственно, просто идти по дереву, сворачивая в соответствующую каждому биту сторону до тех пор, пока мы не достигнем листа. Например, если есть строка «101 11 101 11» и наше дерево, то мы получим строку «pepe».
Итак, алгоритм Хаффмана работает следующим образом:
1. На вход приходят упорядоченные по невозрастанию частот данные.
2. Выбираются две наименьших по частоте буквы алфавита, и создается родитель (сумма двух частот этих «листков»).
3. Потомки удаляются и вместо них записывается родитель, «ветви» родителя нумеруются: левой ветви ставится в соответствие «1», правой «0».
4. Шаг два повторяется до тех пор, пока не будет найден главный родитель — «корень».
Код Хафмена-наилучший код переменной длины.

Достоинства = сокращение объема данных до теоретически возможного предела.
Недостатки = сложность.
Алгоритм Шеннона-Фано
Алгоритм Шеннона-Фано работает следующим образом:
1. На вход приходят упорядоченные по невозрастанию частот данные.
2. Находится середина, которая делит алфавит примерно на две части. Эти части (суммы частот алфавита) примерно равны. Для левой части присваивается «1», для правой «0», таким образом мы получим листья дерева
3. Шаг 2 повторяется до тех пор, пока мы не получим единственный элемент последовательности, т.е. листок
4. Пример кодового дерева:
5. Исходные символы:
6. A (частота встречаемости 50)
7. B (частота встречаемости 39)
8. C (частота встречаемости 18)
9. D (частота встречаемости 49)
10. E (частота встречаемости 35)
11. F (частота встречаемости 24)
12. 
13. Кодовое дерево
14. Полученный код: A — 11, B — 101, C — 100, D — 00, E — 011, F — 010.
Кодирование Шеннона — Фано является достаточно старым методом сжатия, и на сегодняшний день оно не представляет особого практического интереса. В большинстве случаев, длина последовательности, сжатой по данному методу, равна длине сжатой последовательности с использованием кодирования Хаффмана.
|
из
5.00
|
Обсуждение в статье: Статистическое кодирование: коды переменной длины, коды Шеннона-Фана и Хаффмена. |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы