 |
Главная |


Помехоустойчивое кодирование информации
|
из
5.00
|
Кодирование в широком смысле слова можно определить как процедуру взаимно однозначного отображения сообщений в сигналы, иными словами, преобразования сообщения в код. Декодированием называется обратный процесс. Таблица соответствия между совокупностью используемых сообщений и кодовыми комбинациями, которые их отображают, называется первичным кодом. В этом случае кодовая комбинация содержит k элементов. Кодовая комбинация избыточного кода содержит n элементов, где n > k.
Способность кода обнаруживать и исправлять ошибки обусловлена наличием избыточных элементов в кодовой комбинации r = n – k.
В этом случае общее число возможных кодовых комбинаций будет
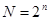 , число разрешенных комбинаций
, число разрешенных комбинаций 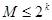 , а запрещенных
, а запрещенных 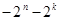 .
.
Искажение информации в процессе передачи сводится к тому, что некоторые из переданных элементов заменяются другими – неверными. При этом для систематических кодов из 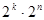 случаев передачи возможно
случаев передачи возможно 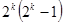 случаев перехода в другие разрешенные комбинации, что соответствует необнаруживаемым ошибкам, и
случаев перехода в другие разрешенные комбинации, что соответствует необнаруживаемым ошибкам, и 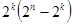 случаев перехода в неразрешенные комбинации, которые могут быть обнаружены [5, 65]. Следовательно, часть опознанных ошибок от общего числа возможных случаев передачи составит
случаев перехода в неразрешенные комбинации, которые могут быть обнаружены [5, 65]. Следовательно, часть опознанных ошибок от общего числа возможных случаев передачи составит
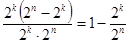 .
.
Например, при использовании одного избыточного элемента (r = 1) часть опознанных ошибок составляет
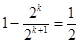 .
.
Для того чтобы искаженная кодовая комбинация была опознана с наименьшей ошибкой, необходимо чтобы остальные 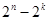 запрещенных комбинаций были разбиты на
запрещенных комбинаций были разбиты на 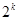 непересекающихся множеств
непересекающихся множеств 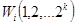 , причем
, причем 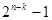 кодовые комбинации, принадлежащие
кодовые комбинации, принадлежащие 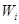 , должны в наибольшей степени быть похожими на i-ю разрешенную комбинацию и должны быть приписаны ей.
, должны в наибольшей степени быть похожими на i-ю разрешенную комбинацию и должны быть приписаны ей.
Процедура опознания искаженной кодовой комбинации в этом случае будет состоять в ее сравнении со всеми 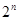 кодовыми комбинациями. Когда произойдет совпадение с одной из комбинаций, принадлежащих , осуществится отождествление искаженной комбинации с i-й разрешенной, т.е. исправление ошибки. Ошибка будет исправлена в случаях из всех возможных. Отношение числа исправляемых кодом ошибочных кодовых комбинаций к числу обнаруживаемых ошибочных комбинаций равно [5, 67]:
кодовыми комбинациями. Когда произойдет совпадение с одной из комбинаций, принадлежащих , осуществится отождествление искаженной комбинации с i-й разрешенной, т.е. исправление ошибки. Ошибка будет исправлена в случаях из всех возможных. Отношение числа исправляемых кодом ошибочных кодовых комбинаций к числу обнаруживаемых ошибочных комбинаций равно [5, 67]:
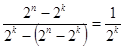 .
.
Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга, называемым кодовым расстоянием. Оно выражается числом элементов, в которых комбинации отличаются одна от другой, и обозначается через d. Минимальное количество элементов, в которых все комбинации кода отличаются друг от друга, называется минимальным кодовым расстоянием d0. Минимальное кодовое расстояние – параметр, определяющий помехоустойчивость избыточного кода. В общем случае для обнаружения всех ошибок до 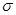 -кратных включительно минимальное кодовое расстояние
-кратных включительно минимальное кодовое расстояние
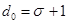 . (3)
. (3)
Минимальное кодовое расстояние, необходимое для одновременного обнаружения и исправления ошибок:
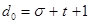 , (4)
, (4)
где t – число исправляемых ошибок.
Для кодов, только исправляющих ошибки:
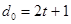 (5)
(5)
Соотношения (3), (4) и (5) определяют лишь кратность гарантийно обнаруживаемых и исправляемых ошибок. Обычно коды обнаруживают и исправляют часть ошибок и более высокой кратности.
К наиболее употребляемым избыточным кодам можно отнести блоковые и непрерывные коды.
Блоковые коды характеризуются тем, что исходная непрерывная информационная последовательность разделяется на отдельные части, каждая из которых кодируется отдельно и независимо от других частей, образуя раз решенные слова избыточного кода.
Равномерные блоковые коды характеризуются одинаковой длиной разрешенных кодовых слов, в отличие от неравномерных кодов.
В непрерывных кодах исходная информационная последовательность не разделяется на части, а кодируется непрерывно, причем избыточные элементы формируются на определенных позициях между информационными. Равномерные блоковые коды подразделяются на линейные и нелинейные.
Линейные коды образуют наиболее обширный подкласс кодов и определяются тем, что сумма по модулю для двух и более разрешенных комбинаций кода дает комбинацию этого же кода.
Нелинейные коды не обладают этим свойством. Примером нелинейных кодов является код с постоянным весом, применяемый в телеграфии. В некоторых случаях линейные коды называют групповыми, что обусловлено математическим описанием подмножества разрешенных кодовых слов длины n как подгруппы в группе всех слов длины n. Линейный код, в котором информационные и проверочные элементы разделены и расположены на строго определенных позициях, называется систематическим, в отличие от несистематических кодов, в которых нельзя в явном виде выделить информационные и проверочные элементы. Систематические коды получили наибольшее распространение. Систематические коды, как правило, обозначаются (n, k) – кодами и включают: коды с проверкой на четность, коды Хэмминга, циклические коды, коды с повторением, итеративные коды, каскадные, коды Рида–Малера, дециклические коды и много других [3, 32].
В информационных системах для передачи коротких команд управления нашли наибольшее применение циклические коды; для обнаружения ошибок при встроенном контроле аппаратуры обработки – коды с одной проверкой на четность; при хранении информации – коды с повторением; при непрерывной передаче больших массивов измерительных данных – сверточные коды. Для повышения эффективности обработки избыточных кодов развиваются различные квазиоптимальные методы декодирования, использующие дополнительную информацию о ненадежных элементах передаваемых данных.
Циклические коды
|
из
5.00
|
Обсуждение в статье: Помехоустойчивое кодирование информации |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы