 |
Главная |


Облачные технологии в маркетинговых исследованиях
|
из
5.00
|
Возникновение и развитие облачных технологий напрямую связано с возникновением сетевых компьютерных технологий. Стоит отметить, что задача хранения больших объемов информации и распространение этой информации существовала задолго до появления компьютерной техники и тем более компьютерных сетей. Однако кардинальное решение этой задачи стало возможным только благодаря появлению сначала компьютеров, а затем объединению компьютеров в сети.
Главным отличительным свойством облачных технологий является предоставление услуг пользователям сети в виде различных сервисов. В зависимости от вида сервисов сложилась устойчивая классификация облачных технологий. Одним из первых сервисов, предоставляемых пользователям сети, стал сервис предоставления программного обеспечения, получивший аббревиатуру SaaS (Software as a Service). В 2002 году компания Amazon разработала облачный сервис, позволяющий хранить информацию на сетевых ресурсах. В дальнейшем эта компания постоянно совершенствовала свои продукты и стала лидером рынка предоставления облачных услуг.
В случае предоставления пользователям сервисов класса SaaS для них предоставляется доступ к программному обеспечению, которое устанавливается на серверах в сети интернет. Чаще всего программное обеспечение бывает востребовано только в определенные моменты времени. Например, для изучения возможностей корпоративных ERP систем в учебном заведении в период учебного семестра или учебной сессии. Поскольку стоимость таких систем весьма существенна, реальная возможность приобретения программы чаще всего отсутствует. В такой ситуации воспользовавшись сервисом SaaS можно решить данную проблему с минимальными затратами. Здесь также следует иметь в виду, что компания, предоставляющая данную услугу, в полной мере отвечает за обновление программного обеспечения и за выполнение лицензионных норм по его применению.
Распределение наиболее востребованных облачных сервисов данного класса приведено на рисунке 10.4.
 |
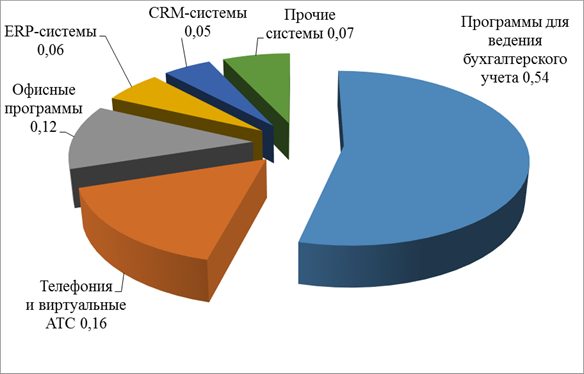
В качестве примера предоставления облачных сервисов класса SaaS можно назвать линейку продуктов компании 1С. В целях привлечения клиентов такие компании предоставляют различные формы оплаты услуг, в том числе и возможность оплаты за реальные сроки использования программы. Облачный сервис 1С: Предприятие через Интернет позволяет:
1. Всем сотрудникам организации и ее руководителям работать в любое время с программой вне зависимости от места расположения, используя возможности сети Интернет.
2. Организовать многопользовательский режим работы с программой, что особенно актуально для удаленных подразделений и офисов.
3. Одному специалисту одновременно обслуживать несколько организаций.
4. Снять с пользователя все вопросы, связанные с обновлением и настройкой сервисов.
5. Предоставить доступ к информационной базе внешним консультантам или аудиторам. консультантам.
Использование сервисов SaaS не требует больших инвестиций и особенно выгодно для малых предприятий и предприятий, только организующих свой бизнес.
Еще один класс облачных услуг, получивших большую популярность в связи с размещением в сети различных сайтов и корпоративных порталов. В этом случае пользователю предоставляется возможность размещать на сервере владельца услуг материалы сайта и все необходимые файлы. При этом сервис предоставляется как инфраструктура. Этот класс облачных технологий имеет аббревиатуру IaaS (Infrastructure as a Service). Пользователь получает уникальный IP - адрес для доступа к размещенному сайту. Как правило, провайдер обеспечивает необходимый набор компонент, возможности использования базы данных, программный интерфейс для связи с web приложением. Процесс размещения сайта в сети интернет получил название хостинга. Существуют разные формы и условия предоставления хостинга. Это бесплатный хостинг с ограниченными условиями размещения материалов и платный хостинг, обеспечивающий все необходимые элементы облачного сервиса.
Для разработки прикладного программного обеспечения необходима информационно-технологическая платформа, включающая операционную систему, средства инструментальной разработки, системы управления базами данных, сервисное программное обеспечение. Программная платформа служит фундаментом для построения программного обеспечения и требует для развертывания значительных затрат. Одним из решений в этом случае является платформа, развернутая на облаке и предоставление к ней доступа для пользователей данного сервиса. Аббревиатура данного сервиса PaaS (Platform as a Service). Сервисы класса PaaS во многом схожи с сервисами IaaS, дополняя последние операционной системой и системным программным обеспечением. В качестве массового использования сервисов PaaS можно указать системы электронной коммерции. Пользователю предлагается готовая инфраструктура, требующая минимальных затрат на настройку.
Разные группы пользователей используют разные классы облачных сервисов. Для специалистов занятых обработкой данных наибольший интерес представляют облачные сервисы, предоставляющие пользователю дисковое пространство DaaS (Data as a Service). Данные как услуга на сегодня один из самых востребованных облачных сервисов. Возникло целое направление в информационных технологиях, связанное с организацией хранения данных, доступа к данным, обработке данных. На смену серверных комнат, с установленными серверами для хранения больших массивов данных, сегодня приходят специализированные центры обработки данных (ЦОД). Доступ к данным обеспечивается сетевыми возможностями и средствами телекоммуникаций. Сетевые ЦОД обслуживает одновременно огромное количество пользователей, обеспечивая при этом конфиденциальность данных, сохранность и доступность. Для заказчика сервиса DaaS осуществляется техническая поддержка оборудования, резервное копирование данных, антивирусная защита и ряд других необходимых процедур. Все центры обработки данных можно разделить на две группы. Первую группу составляют корпоративные ЦОД, например, ЦОД Сбербанка или ЦОД Пенсионного фонда. Вторую группу ЦОД составляют компании предоставляющие свои ресурсы всем заинтересованным пользователям в том числе и физическим лицам в виде сервиса.
Деление облачных сервисов на классы является условным. В реальной практике применения сервисов происходит интеграция сервисов в зависимости от решаемых практических задач. Кроме того, разные компании такие как IBM, IDC, Gartner предлагают свою классификацию, порой несовпадающую с другими представлениями облачных технологий. На рисунке 10.5 представлена схема предоставления облачных услуг, предложенная компанией IBM.
 |
Приведенная выше классификация облачных сервисов в качестве классификационного признака использует вид предоставляемого пользователям сети сервиса. По модели реализации облачные сервисы принято условно разделять на три группы:
1. Публичное облако - ИТ сервисы предоставляются различным компаниям, организациям и частным лицам как услуги. При этом ИТ- инфраструктура облака находится полностью под управлением и обслуживанием владельца облака. В качестве примера этой категории сервиса можно привести предоставление хостинга для размещения сайтов. Кроме того, можно указать такие массовые и общедоступные для населения услуги как социальные сети, электронная почта, хранилища данных, открытые образовательные ресурсы и ряд других сервисов.
2. Частное облако - ИТ- инфраструктура частного облака контролируется и управляется одной компанией. Главное отличие частного облака от традиционной ИТ структуры бизнеса в том, что бизнес получает по запросу ИТ сервисы частного облака с заранее известными экономическими и эксплуатационными параметрами. ИТ инфраструктура частного облака строится по другим принципам нежели традиционная ИТ инфраструктура информационных подразделений компаний. Таким образом частное облако можно рассматривать как хранилище разнообразных услуг. По запросу бизнеса эти услуги предоставляются для решения текущих задач компании. Еще одним фактором, влияющим на рост числа сервисов этого вида, является активный переход на мобильные устройства доступа в сеть. Мобильность доступа сотрудников к корпоративным приложениям существенно влияет на популярность облачных технологий несмотря на определенные риски по обеспечению конфиденциальности информации. Основными потребителями частных облаков являются компании с развитой ИТ инфраструктурой и имеющие свои центры обработки данных. Кроме того, ряд российских законодательных актов запрещают размещение персональных данных на зарубежных серверах.
3. Гибридное облако. Публичные и частные облака имеют как преимущества, так и недостатки. В таблице 10.1 приведены некоторые сравнительные характеристики этих облаков.
Таблица 10.1
Сравнение сервисов публичное и частное облако
| Публичное облако | Частное облако |
| Публичный доступ к ресурсам | Доступ к ресурсам облака ограничен |
| Поддержка большого числа пользователей | Может быть предоставлен доступ только определенным пользователям |
| Доступность в любой точке мира | Доступ к ресурсам возможен по защищенному или выделенному каналу |
| Не применимо для конфиденциальной информации | Применимо для хранения конфиденциальной информации |
Гибридные облака предполагают совместное применение частного и публичного облака. При этом доступ осуществляется из собственного облака для ресурсов, требующих конфиденциальности, и из публичного облака для всех остальных ресурсов. Например, разместить сайт компании целесообразно на публичном облаке, тогда как внутренние информационные системы на частном облаке. Гибридные облака в этой связи рассматриваются как расширение частных облаков. Главным преимуществом такого подхода является экономия средств на развертывания внутренней ИТ инфраструктуры, поскольку не всегда удается спрогнозировать развитие компании и потребности в ИТ ресурсах.
Аналитическая компания IDC, анализируя этапы развития ИТ отрасли выделяет три основных этапа, основанные на трех различных платформах.
В основе первой платформы лежали мейнфреймы с подключенными к ним терминалами. Основу второй платформы составляют персональные компьютеры, объединенные в локальные сети и подключенные к сети интернет. Третья платформа отличается ростом подключений к сети мобильных устройств, развитием социальных сетей, ростом предложений облачных сервисов. Переход на новую платформу сопровождается увеличением числа пользователей ИТ сервисов. В основе третьей платформы четыре базовые элемента: большие данные, облачные сервисы, мобильные устройства, социальные технологии.
Практически все аналитические компании, анализируя рынок облачных услуг отмечают высокую положительную динамику этой отрасли. Среди основных тенденций рынка отмечается:
· увеличение числа предприятий и организаций, переходящих в облако;
· уменьшение стоимости облачных услуг;
· снижение опасений по поводу обеспечения информационной безопасности;
· увеличение доли гибридных облаков.
Существует целый ряд факторов, влияющих на рост рынка облачных услуг. Одним из таких факторов является углубление разделения труда. Для повышения производительности труда и достижения наилучшего экономического эффекта компании стремятся к оптимизации свих ресурсов и передачи ряда непрофильных активов на аутсорсинг. Разработка собственными силами программного обеспечения сегодня могут позволить себе только очень крупные компании. Для большинства предприятий и организаций все более привлекательным решением становится переход на облачные сервисы.
На рисунке 10.6 представлено распределение российских облаков по трем группам.
Что касается распределения облаков по видам сервисов, то наибольшее распространение получили SaaS и IaaS облака и в меньшей степени PaaS облака. Среди компаний лидеров можно назвать: Amazon, Microsoft Azure, Google Cloud Platform, IBM. В целом наблюдается активный рост рынка облачных технологий. Рост рынка составляет 15-20% в год. Среди российских компаний можно указать компании Яндекс, Mail.ru, МТС. В рамках программы «Цифровая экономика России» планируется разработать генеральную схему размещения ЦОДов, а также создать консорциум ЦОДов.
По мнению специалистов, сфера маркетинга всегда активно использовала передовые информационные технологии. Облачные технологии обеспечивают хранение больших объемов данных, предоставляют в распоряжения маркетолога облачные сервисы и инфраструктуры для проведения маркетинговых исследований. Обеспечение безопасности данных определило использование частных облаков, развернутых в собственных центрах обработки данных. В частных облаках размещают такие маркетинговые информационные системы как ERP и CRM, на которых построена основная деятельность по работе с потребителями. В то же время для решения ряда текущих маркетинговых задач используются и публичные облака. В частности, такие облака используются для предоставления клиентам разнообразных информационных услуг и повышения сервиса обслуживания. Рассмотрим основные направления использования облачных технологий в сфере маркетинга.
1. Проведение аналитических исследований в области риск-менеджмента и ценообразования. Такие вычисления оперируют большими объемами распределенных данных и требуют больших объемов памяти и вычислительных ресурсов. Поэтому перенос таких операций в облако дает большой экономический эффект. Вычисления могут выполняться как в частном, так и в гибридном облаке.
2. Исследование рынков. Банковская деятельность требует постоянного мониторинга рынков и отраслей экономики, входящих в сферу интересов финансового учреждения. Как правило такие данные могут быть получены из открытых источников. Наиболее рациональным вариантом для проведения маркетинговых исследований в данном случае могут быть публичные облака.
3. Подготовка внутренней отчетности. Этот вид деятельности требует значительных вычислительных мощностей, поэтому загрузка собственных серверов отчетами может привести к снижению производительности операций. Для снижения нагрузки в данном случае могут быть использованы гибридные облака.
4. Предотвращение мошеннических действий и операций. В настоящее время разработаны и используются комплекс облачных сервисов, анализирующие поведение клиентов путем распознавания видео и выявления мошеннических сценариев. Такие сервисы используют службы безопасности банков.
5. Аналитические системы исследования поведения клиента. Удержание клиента в условиях конкуренции важнейшая задача любого бизнеса. Для этих целей разработаны облачные сервисы, позволяющие анализировать поведение клиента и прогнозировать его дальнейшие действия. В качестве примера можно привести сервисы Microsoft Stream Analytics и HD Insight.
6. Операции трейдинга. Для анализа биржевых новостей и текущего состояния рынка хорошо себя зарекомендовали облачные сервисы на публичных облаках. Перенос биржевой аналитики в облако позволяет разгрузить серверы банка и его телекоммуникационные каналы.
7. Облачные сервисы для сайтов. Эти сервисы обеспечивают доставку контента на устройства клиентов, в том числе и на мобильные устройства. Хостинг сайтов одна из самых востребованных облачных услуг, имеющих целью обслуживание розничных клиентов. Кроме того, с помощью облачного сервиса появляется возможность дистанционного управления смартфонами и планшетами, осуществлять контроль всех внешних устройств, подключаемых к корпоративной информационной системе.
Скоринг в маркетинге
Скоринг[67] (англ. scoring – счет, счет очков в игре) – модель классификации клиентов любого рода на группы, когда характеристика, разделяющая группы неизвестна, но при этом известны другие факторы, которые связаны с изучаемой характеристикой.
Любая скоринговая система основывается на следующем постулате: «Клиенты со схожими социальными характеристиками в одинаковых ситуациях ведут себя одинаково». Тогда, приняв этот постулат, можно строить различные статистические модели, применимые в бизнесе.
Пусть клиента можно описать следующим набором характеристик:
· пол;
· возраст;
· доход;
· сумма вклада в банке;
· семейное положение;
· количество детей;
· должность;
· время работы в одном месте
· и т.д.,
На основе исторических данных о достаточно большой группе клиентов может быть построена модель, которая будущих клиентов будет автоматически относить клиентов к приоритетным группам.
В общем случае скоринговая модель строится по следующему алгоритму:
1. Выбирается интересующая характеристика.
2. Выбираются факторы, связанные с интересующей характеристикой.
3. Строится таблица, в которую для каждого клиента заносятся данные интересующей характеристики и значения связанных факторов.
4. Выбирается математический или иной формальный аппарат, который используя таблицу, построенную в п.3, классифицирует клиентов
5. Построенная модель позволит ранжировать новых клиентов по приоритетным группам.
| Немного истории. Исторически первыми скоринговыми системами были системы оценки рисков по кредитам и управление ими на основе прогноза невозврата кредита или просрочки платежа. В качестве главной характеристики рассматривалась способность клиента вернуть взятый кредит. В качестве связанных факторов могут быть рассмотренные выше факторы. Понятно, что банки, выдавая кредиты, всегда оценивали риски и всегда были случаи отказа в кредитах. Каждый банк сам разрабатывал для себя систему скоринга (и методику, и документоведение). Оценка рисков производилась на основе документов, предоставленных клиентом. Эта информация вносилась в скоринговые карты (досье клиента) и оценивалась по ряду параметров (начиная от семейного положения и заканчивая стажем и заработной платой по текущему месту работы). Такая система скоринга обладала следующими недостатками: · оценки носили субъективный характер и в значительной степени определялись опытом работы сотрудника банка; · незначительное количество параметров (как правило, не более 20), по которым оценивался риск; · оценка производилась на основании информации, предоставленной клиентом, а, следовательно, не всегда правдивой. Внедрение информационных технологий не могло обойти стороной и скоринг. Кредитные организации начали разработку собственных программных продуктов, основанных на собственных методиках. На рынке появились специализированные программные продукты, использующие различные математические модели. Необходимая для оценки кредитоспособности заемщика информация бралась не только из документов, предоставленной заемщиком, но и из баз данных кредитной организаций. По данным некоторых исследователей, внедрение таких систем позволило сократить на 50% уровень безнадежного долга. В 80-ых годах прошлого века появились первые разработки на основе искусственного интеллекта, в частности, компания HNC разработала нейросетевую модель кредитного скоринга, обладавшую преимуществами по сравнению с моделями статистического анализа, главным из которых была способность к обучению. Это стало началом перехода многих кредитных организаций на системы на основе искусственного интеллекта. |
Развитие информационных технологий и маркетинга привело к тому, что технологии скоринга внедрились в маркетинг, в частности в Интернет маркетинге появился ЛИД-скоринг (от англ. Lead –вести, возглавлять, лидировать). Таким образом, можно выделить две основных сферы применения скоринга:
1. Маркетинг, где в свою очередь можно выделить:
1.1. ЛИД-скоринг.
1.2. Разбиение клиентов на группы, поощрение которых скидками или бонусами даст наибольший результат.
2. Кредитный скоринг, где выделяют:
2.1. Определение потенциальных клиентов-потребителей предлагаемого продукта, что позволит снизить затраты на привлечение новых клиентов и максимально удовлетворить потребности уже привлеченных клиентов.
2.2. Разбиение клиентов, подавших заявки на кредит на потенциальных должников и потенциальных добросовестных плательщиков.
Остановимся подробнее на каждой из указанных сфер применения скоринга.
ЛИД-скоринг появился в компании IBM. Компания получала около 4000 заявок на продукты. Обработка такого количества заявок требовала значительного количества специалистов. Чтобы оптимизировать процесс было предложено сегментировать клиентов в зависимости от различных характеристик и начислять им баллы по заранее установленной шкале. Так, например, тор-менеджер компании получал 100 баллов, а студент 10. Клиент, у которого мало баллов, получал в ответ СМС или письмо, клиенту с большим количеством баллов звонил менеджер.
Термином ЛИД обозначают потенциального клиента, который откликнулся на маркетинговые коммуникации (звонки, заполненные анкеты, комментарии в социальных сетях, заявки на сайте, письма, и т.д.). Определяют 3 вида лидов:
· холодный лид – клиент, потребность в товаре или услуге у которого еще не сформировалась, может быть даже не знающий о вашей компании;
· теплый лид – клиент, осведомленный о вашей компании, ее продуктах или услуге, понимающий, что ему нужно, но не определившийся с поставщиком;
· горячий лид – клиент, который готов именно ваш товар или вашу услугу.
Тип канала, посредством которого пришел клиент, определяет тип лида:
· Nets (неты) – клиенты привлеченные в компанию применением маркетинговых инструментов в Интернете таки, как реклама, вебинары, контент в блогах; преимущество – широкий охват аудитории, большое количество лидов, простота расчета эффективности каналов получения лидов; недостатки: низкая сумма сделок, «количество» преобладает над «качеством»;
· Seeds (сиды) –обратились в компанию на основании информации, полученной от других клиентов; таким образом, клиенты компании, довольные обслуживанием, распространяют о ней положительную информацию и привлекают новых клиентов; спрогнозировать поведение привлеченных таким способом клиентов довольно трудно;
· Spears (спирсы) – приходят в компанию после физического контакта с сотрудниками компании (личная встреча, обзвон, раздача визиток); как правило спирсы – это предсказуемый результат, мгновенная обратная связь.
Таким образом, главная задача ЛИД-скоринга – разбиение клиентов, обратившихся в компанию, на виды и в соответствии с принятой в компании методикой стимулировать их конверсию от холодных в горячих.
Начисление баллов компании ведут по собственным методикам, но как правило, баллы начисляются за:
· посещение страницы сайта;
· посещение определенной страницы;
· посещение определенной страницы сайта более заранее установленного числа раз;
· открыл письмо;
· ответил на письмо;
· зарегистрировался на вебинар;
· и т.д.
Начисление баллов, как правило встраивают в программное обеспечение Интернет-магазинов и CRM-систем. Это позволяет автоматически находить горячих клиентов и информировать менеджеров на обращение к такому клиенту.
Разбиение клиентов. Рассмотрим компанию, которая проводит кампанию по удержанию постоянных клиентов. Для этого решено сделать скидку на некоторую группу товаров так, чтобы это принесло максимальную выгоду. Следовательно, нужно выделить соответствующую группу клиентов и товары, их интересующие. Информацию о клиентах и покупках, которые они делают, можно получить, используя информацию, которая привязана к карте постоянного покупателя. Дале клиентов можно разделить на группы в соответствии с частотой посещения или в соответствии с суммой, потраченной за период.
Качественно построенная скоринговая модель позволит выбрать группы клиентов и систему их стимулирования, чтобы получить от проводимой акции максимальный эффект.
Определение потенциальных клиентов-потребителей предлагаемого продукта. Здесь выделяют:
· скоринг отклика: модели оценивают реакцию клиентов на информацию о новом продукте;
· скоринг потерь/сохранения: модели позволяют спрогнозировать дальнейшее поведение клиента: будет ли он пользоваться предлагаемым продуктом или уйдет в другую компанию.
Разбиение клиентов, подавших заявки на кредит на потенциальных должников и потенциальных добросовестных плательщиков или классический кредитный скоринг.
Проблема кредитного скоринга может быть сформулирована следующим образом: пусть известны ответы заемщика на вопросы анкеты 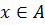 , тогда необходимо определить группу, к которой относится заемщик:
, тогда необходимо определить группу, к которой относится заемщик: 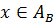 - «плохие» или
- «плохие» или 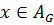 – «хорошие». Понятно, что абсолютно точная классификация невозможна потому, что и «плохой» и «хороший» заемщики могут иметь одинаковые ответы на вопросы анкеты.
– «хорошие». Понятно, что абсолютно точная классификация невозможна потому, что и «плохой» и «хороший» заемщики могут иметь одинаковые ответы на вопросы анкеты.
Разработка модели скоринга требует полной и достоверной информации о заемщиках кредитной организации. Объем данных может меняться в зависимости от конкретной модели, но в любом случае должен удовлетворять условиям случайности и статистической значимости. Для построения модели могут использоваться как внутренняя информация банка, так и внешние данные, например, Национального бюро кредитных историй[68]. Модель должна применяться только в отношении тех условий (кредитных продуктов, сектора рынка и даже экономической ситуации), данные о которых легли в основу модели. Так сведения по ипотеке не могут быть безусловно использованы при разработке модели по автокредитам. Важен также и период, за который используются данные. Так информацию для построения модели скоринга заявок потребительских кредитов рекомендуют брать за последние 2-5 лет, в тоже время для моделей поведенческого скоринга – 6-12 месяцев . Как правило, при разработке модели из набора данных исключают информацию о «нетипичных» клиентах (мошенники, сотрудники банка, умершие клиенты, VIP-клиенты, клиенты с аномально большими суммами, нестандартными условиями погашения и целями кредита).
Модели кредитного скоринга в настоящее время строятся на основе методов:
· статистики (линейная регрессия, дискриминантный анализ, логистическая регрессия, деревья классификации);
· исследования операций (линейное программирование, нелинейная оптимизация);
· искусственного интеллекта (нейронные сети, экспертные системы, байесовские сети).
Модели кредитного скоринга.
Множественная линейная регрессия. Определяем зависимую переменную Y, принимающую значение 0 в случае «плохого» клиента и 1 в случае «хорошего». Статистическая выборка, информация о клиентах, получивших кредиты, представляет собой матрицу размером N × (M+1), где N – объем выборки, т.е. количество клиентов, информация о которых использовалась для построения модели; M – количество вопросов в анкетах клиентов; еще один столбец матрицы - это апостериорная информация о клиенте: к какой категории он отнесен – «плохой» или «хороший». Таким образом, модель – это выражение, связывающее вероятность дефолта клиента со значениями ответов на вопросы анкеты:
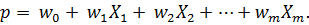
Весовые коэффициенты 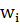 могут быть найдены методом наименьших квадратов. Приведенное выражение следующее несоответствие: в левой его часть имеем вероятность, которая может принимать значения между 0 и 1. Правая же часть может принимать любые значения. Чтобы преодолеть это противоречие, приходится искать какие-то приемы. Например, заменять значение вероятности некоторой функцией от него.
могут быть найдены методом наименьших квадратов. Приведенное выражение следующее несоответствие: в левой его часть имеем вероятность, которая может принимать значения между 0 и 1. Правая же часть может принимать любые значения. Чтобы преодолеть это противоречие, приходится искать какие-то приемы. Например, заменять значение вероятности некоторой функцией от него.
Логистическая регрессия. Метод логистическое регрессии базируется на том, что значения выборки используются для нахождения вероятности того, эта выборка принадлежит к определенному классу. Пусть рассматривается только два класса, например, «хороший клиент» и «плохой клиент». (Напомним, что в линейной регрессии на основании выборки фактически рассчитывается значение зависимой переменной, принимающей только два значения: «хороший» клиент / «плохой» клиент, давать кредит / не давать кредит). Тогда все пространство исходных значений может быть разделено на две области, соответствующие рассматриваемым классам, и граница между ними (областями) линейна, т.е. прямая, плоскость и т. д., в зависимости от того, по скольким независимым переменным мы «оцениваем» клиента. Такая граница называется линейным дискриминантом, т.к. выражается линейной функцией нескольких переменных (рисунок 10.7). Функция, соответствующая линейному дискриминанту, представленному на рисунке 10.7 имеет вид:
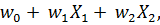
т.е. клиент «оценивается» только по двум параметрам.
Если теперь рассмотреть произвольную точку А(a1, а2) на координатнойплоскости, то возможны три варианта:
1. Точка А лежит в области «хороший» клиент. Тогда выражение 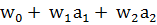 принимает положительное значение. И чем больше это значение, тем больше расстояние между границей и точкой А, и, следовательно, больше вероятность того, что точка принадлежит классу «хороший» клиент, и эта вероятность находится в пределах (0,5;1].
принимает положительное значение. И чем больше это значение, тем больше расстояние между границей и точкой А, и, следовательно, больше вероятность того, что точка принадлежит классу «хороший» клиент, и эта вероятность находится в пределах (0,5;1].
2. Точка А лежит в области «плохой» клиент. Тогда выражение принимает отрицательное значение. И чем больше это значение по модулю, тем больше расстояние между границей и точкой А, и, следовательно, больше вероятность того, что точка принадлежит классу «плохой» клиент, и эта вероятность находится в пределах [0;0,5).
3. Точка А лежит на самой границе. Тогда значение выражения 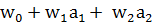 равно нулю. Следовательно, модель не может определить, к какому классу принадлежит точка А, поэтому вероятность равна 0,5.
равно нулю. Следовательно, модель не может определить, к какому классу принадлежит точка А, поэтому вероятность равна 0,5.
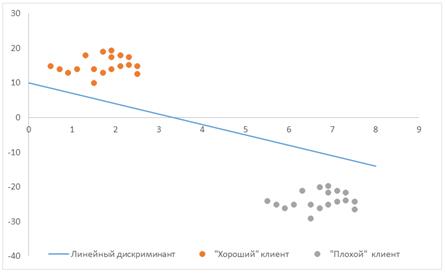
Рис. 10.7. Линейный дискриминант двух областей
Таким образом, предсказание значения бинарной переменной р (принимающей два значения 0 и 1 в методе множественной линейной регрессии) заменяется вычислением значения непрерывной переменной, принимающей значения (-∞, ∞) при любых значениях независимых переменных. Для преобразования полученного значения в вероятность применяется так называемое логит-преобразование по следующей формуле:
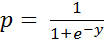 ,
,
где
 вероятность того, что клиент «хороши» или клиент «плохой»;
вероятность того, что клиент «хороши» или клиент «плохой»;
y = 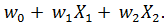
Переменные 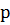 и y связаны между собой зависимостью, представленной на рисунке 10.8.
и y связаны между собой зависимостью, представленной на рисунке 10.8.
Как видно из выражения линейного дискриминанта, его положение в системе координат и, следовательно, «качество» разделения клиентов на классы определяется значениями коэффициентов 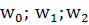 (рисунок 10.9).
(рисунок 10.9).
 |
Рис. 10.8. Логистическая кривая
 |
Из многих способов нахождения коэффициентов уравнения регрессии довольно часто используется метод максимального правдоподобия. Сущность метода заключается в следующем.
Рис. 10.9. Линейный дискриминант при разных значениях коэффициентов
По данных о уже выданных и уже выплаченных кредитах составляется выборка (таблица), в которую заносятся значения всех переменных, характеризующих клиента (значения 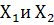 ) и «категория» клиента («плохой» или «хороший»). Полученная выборка анализируется в соответствии с определенными правилами. Например, удаляются строки, соответствующие «аномальным» клиентам (очень молодым или очень пожилым, клиентам, бравшим нетипично большой или наоборот очень маленький кредит, и т.д.).
) и «категория» клиента («плохой» или «хороший»). Полученная выборка анализируется в соответствии с определенными правилами. Например, удаляются строки, соответствующие «аномальным» клиентам (очень молодым или очень пожилым, клиентам, бравшим нетипично большой или наоборот очень маленький кредит, и т.д.).
Оставшуюся выборку делят на две части в отношении ¾ на ¼ или 2/3 на 1/3. Большая часть выборки используется для нахождения неизвестных коэффициентов линейного дискриминанта (обучающая выборка), меньшая часть используется для проверки адекватности полученной модели (тестирующая выборка).
Рассмотрим теперь некоторую функцию g(А), где А – точка данных обучающей выборки (строка данных таблицы). Значение функции g(А) можно рассматривать как значение вероятности того, что точка А принадлежит, например, классу «хороший» клиент: g(А) = Рхк (Рхк – значение, полученное с использованием модели логистической регрессии). Иначе, функция g(А) количественно оценивает вероятность того, что модель правильно классифицирует точку обучающей выборки. Если рассмотреть «среднее» значение функции g(А) на всей обучающей выборке, то оно будет показывать значение вероятности того, что случайная точка данных будет классифицироваться системой корректно. Но, как следует из рис. 5.9, корректность классификации зависит от положения на оси координат линейного дискриминанта. (Например, линейный дискриминант 4 не «может» правильно классифицировать точки.) Поэтому функция g(А) должна также зависеть от параметров линейного дискриминанта 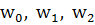 , следовательно g(A, ). Значения выбирают так, чтобы «среднее» значение g(A, ) принимало максимальное значение на всем множестве обучающей выборки.
, следовательно g(A, ). Значения выбирают так, чтобы «среднее» значение g(A, ) принимало максимальное значение на всем множестве обучающей выборки.
Когда модель получена, проводится оценка ее адекватности, для чего используется ранее упоминаемая тестирующая выборка. Значения независимых переменных тестирующей выборки подают на вход модели, определяют значение зависимой переменной, определяющее принадлежность к тому или иному классу, и сравнивают расчетное значение с фактическим. Если процент расхождений расчетных и фактических значений невелик, модель считается адекватной и может быть использована. В противном случае осуществляют еще одну итерацию, т.е. формируют новую обучающую и новую тестирующую выборку, пересчитывают параметры модели и опять проводят ее тестирование.
Получить линейную скоринговую функцию можно также методами линейного программирования. Пусть А – множество всех возможных ответов на вопросы анкеты заемщика X =( X 1 , X 2 ,….. Xk ). Банк должен разделить множество А на два подмножества:
· AG – соответствующие ответам «хорошего» заемщика;
· AB - соответствующие ответам «плохого» заемщика.
Пусть также имеет выборка из n уже проверенных заемщиков, причем первые nG строк выборки соответствую «хорошим» заемщикам, следующие nB строк – «плохим» (n = nG + nB). Пусть также вектор ( xi 1 , xi2,…,xi k ) – ответы i-ого заемщика на вопросы анкеты. Нужно такие значения весовых коэффициентов (w1, w2,…., wk ), чтобы взвешенная сумма w 1 X 1 + w 2 X 2 +..+ wkXk принимала значение, которое больше некоторой заранее установленной константы с в случае «хорошего» заемщика, и ниже – в случае «плохого» заемщика, т.е.
w 1 x
|
из
5.00
|
Обсуждение в статье: Облачные технологии в маркетинговых исследованиях |
|
Обсуждений еще не было, будьте первым... ↓↓↓ |

Почему 1285321 студент выбрали МегаОбучалку...
Система поиска информации
Мобильная версия сайта
Удобная навигация
Нет шокирующей рекламы